Oops! Something went wrong while submitting the form.
As businesses advance towards digitization, data is becoming the lifeblood of operations. In this environment, efficient data management has never been more critical.
As Pearl Zhu noted, "We are moving slowly into an era where big data is the starting point, not the end."
This growth of data, highlights the crucial role efficient data management plays in the success of modern businesses and how they rely on information from different sources to make decisions.
However, using the insights within all this data requires effective strategies, such as data extraction and ingestion, to transform it into useful knowledge.
This article provides valuable guidance for two core processes in data workflows, i.e., data extraction vs data ingestion. Data extraction involves retrieving information from various sources, such as databases, websites, or files.
On the other hand, data ingestion involves importing, transforming, and loading data into a target system. Discerning how each supports your goals is key. Whether you oversee operations, underwriting, tech infrastructure, or work with documents.
So, is it Data Extraction vs. Data Ingestion?
Understanding Data Extraction
Data extraction is the systematic process of collecting data from various sources, such as databases, websites, APIs, logs, and file types. It serves as a crucial early step in the data lifecycle. It bridges the gap between raw, unorganized data and the actionable insights businesses can glean through analysis.
As the volume and value of data continue growing remarkably, the demand for extraction technologies is soaring as well. The global data extraction market was valued at $2.14 billion in 2019.
Encouragingly for extraction solution providers, this market is projected to reach $4.90 billion by 2027, with an impressive compound annual growth rate of 11.8% from 2020 to 2027. This surge reflects the rising need for efficient data management solutions.
Extraction plays a pivotal role in data integration by centralizing information from diverse sources and organizing it for functions like warehousing, business intelligence, mining, and analytics.
This sets the stage for further data exploration and unlocks its true potential. Technologies like optical character recognition (OCR) and intelligent document recognition (IDR) represent significant advancements in the field. Automating document extraction and classification with these tools offers enormous potential to enhance productivity.
Imagine this: Logistics companies routinely handle massive volumes of invoices, orders, and customer data. Speedy and accurate processing is vital to avoid disruptions. By automating extraction through rule-based templates, logistics firms can identify key details from structured and unstructured files like PDFs and text documents.
Instead of manually coding each document, employees can simply run them through the system, saving time and minimizing errors.
This is just one example – the benefits extend to various industries like banking, where automated extraction allows analysts to focus on strategic tasks, such as identifying trends, managing risk, and ensuring compliance.
Benefits of Data Extraction
Extract data from various sources like web pages, databases, documents, and more.
Automate data extraction to reduce manual labor costs and processing time.
Identify patterns and trends across different data sources for valuable insights (e.g., seasonal fluctuations, customer behavior).
Gain real-time insights from extracted data to gain a competitive advantage.
Challenges of Data Extraction
Ensure data integrity throughout the extraction process to avoid flawed analysis and reports.
Manage large datasets effectively to overcome issues like duplicate data, missing values, and format differences.
Implement strong security measures to protect sensitive information during extraction and storage.
Adhere to legal and ethical standards for data privacy and security within your industry and region.
We've covered the basics of data extraction and its potential applications across various industries. Now, let's delve into data ingestion.
Understanding Data Ingestion
Data ingestion is the first critical step in transforming raw data into actionable insights. It involves collecting data from diverse sources, preparing it for storage and analysis, and loading it into a destination system.
Data comes from many places, such as customer databases, social media APIs like Twitter, sensor devices in Internet of Things applications, and public websites. The ingestion process begins by connecting to these diverse data sources using various interfaces, such as pulling tweets from the Twitter API, querying data from SQL databases, or streaming sensor readings from IoT gateways.
The data is then transferred to a centralized system like a data warehouse or data lake. In this stage, initial processing may occur to prepare the data for analysis. Once ingested and initially processed, the data is more accessible for efficient querying, exploration, and advanced analytical techniques.
Along the way, the raw data undergoes some processing. This processing will prepare the data for queries and modeling. It involves cleaning records, standardizing formats, and enriching them with metadata. Your goal here is to organize the information in a unified architecture so it's available to data scientists and business analysts.
Data ingestion can happen continuously in real-time or periodically in batches. Real-time ingestion imports new observations as you generate them to provide live, up-to-the-minute visibility. Batch ingestion collects data over time, hourly or daily, before loading it in one go. The right approach depends on your specific analytics and reporting needs.
Regardless of timing, the ingestion phase is crucial for enabling high-value analysis later. It brings outside information into your business's control and sets the stage for gleaning insights from it. When done effectively, the process of ingestion also leads to the next data transformation and discovery stages.
Data ingestion technology has some helpful benefits. It can make teams more efficient and give companies an edge over competitors. Here are a few of the main advantages:
Benefits of Data Ingestion
It brings all data together in one place so teams can find and use it quickly.
The processes clean up data from different sources and put it in set formats that are clear.
Ingestion does some work automatically so engineers can focus on other essential tasks.
Real-time data ingestion lets businesses see problems and opportunities to make smart decisions.
Helps engineers build apps and tools that move data fast for a good user experience.
Challenges of Data Ingestion
Data ingestion faces challenges, too.
Ensuring data quality across diverse sources requires robust cleaning and validation techniques.
Data latency presents a significant challenge in data ingestion, causing delays in data availability and accessibility. The delay can occur due to many factors, such as network congestion, data processing bottlenecks, and inefficient data transfer mechanisms.
Data ingestion pipelines face major challenges when interfacing with numerous third-party applications and operating systems. Ensuring uninterrupted integration with varied systems requires carefully considering compatibility issues and using strong communication protocols.
Now that we have explained the primary concepts, it's time to extensively compare data extraction and data ingestion so you can make an informed decision.
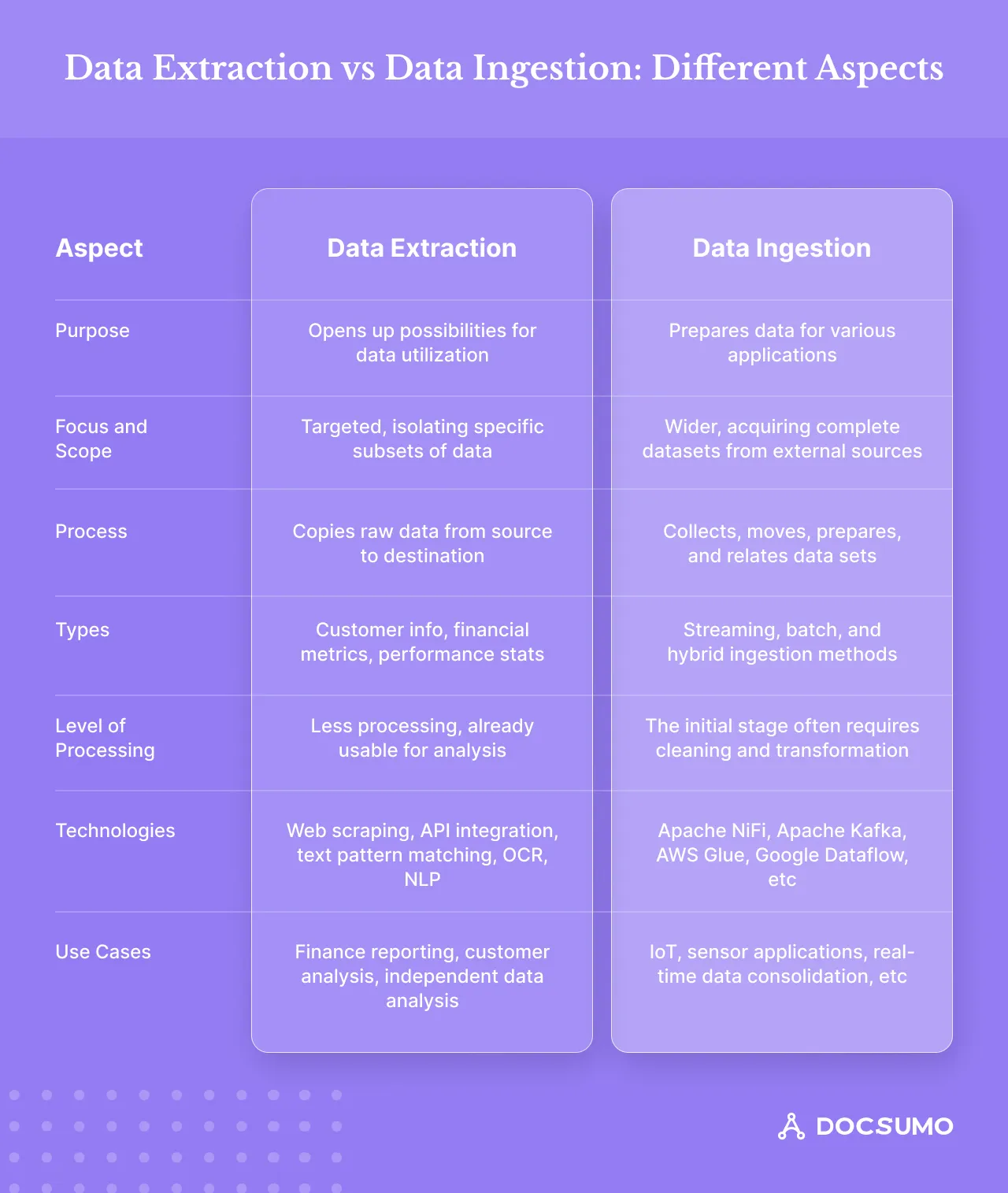
Head-to-Head Comparison: Data Extraction vs Data Ingestion
How we get data into our systems and prepare it for analysis is an important consideration. Many compare and contrast two approaches, i.e., Data Extraction vs Data Ingestion. But it's not always an either/or decision.
Recognizing the strengths and weaknesses of each method can help us design data workflows that work well.
Let's break down some of the critical differences between data extraction vs data ingestion.
Purpose
Data extraction opens up new opportunities. When you extract data from external systems into your databases, you gain control over valuable information. No longer tied to outdated software or licensing, the data belongs to your business, and you can use it however you see fit. Extraction liberates data so you can fully use its potential.
Data ingestion transforms information into insight. The process involves preparing data to be easily understood and applied across analytics, apps, machine learning, and more. It ensures accuracy and consistency so teams aren't overwhelmed by unusable information. Ingestion bridges the gap between raw inputs and refined outputs that people can confidently work with to generate insights, automate processes, and take their initiatives to the next level.
Focus and Scope
Data extraction is more targeted in its aim, isolating particular subsets of information from within existing data stores to meet specific analysis needs. You can only extract the selected fields, records, or segments.
Data ingestion casts a wider net. The goal is to acquire data from multiple external sources, such as files, databases, or data feeds. Rather than picking out elements, the complete datasets are brought into your system.
Process
Data extraction involves pulling raw information from its source, whether a database, spreadsheet, cloud app, or even scraping from websites, and transferring it elsewhere.
Data ingestion is the process of gathering, moving, and preparing various datasets to create a centralized information hub. The aim is to ensure the data is easily queried and understood within its context, curated at the right level of detail, availability, and completeness to support analytical needs.
Types
Data extraction involves gathering various data types, such as customer information, financial metrics, and performance statistics. Customer data, including contact information, purchase histories, and online activities, helps you better understand your audience. Financial data, such as sales figures and costs, helps companies track their business performance. Meanwhile, performance data provides insights into specific tasks or processes, including shipping logistics for retailers and hospital post-surgical outcomes.
Data ingestion, on the other hand, focuses on how data is imported into platforms for storage, processing, and analysis. There are three main approaches: streaming, batch, and hybrid. Streaming captures data in real time as it's generated, allowing for immediate reactions. Batch ingestion collects data periodically, which is suitable for retrospective analysis. Hybrid ingestion combines elements of both, processing data at short intervals.
Level of Processing
Data extraction is a more targeted process that focuses on specific data already in a usable format for analysis. You only need a little additional work before digging into the extracted data.
Data ingestion usually marks the beginning of a lengthier data preparation workflow. When data is ingested, it often needs to undergo various processing steps, such as cleaning, transforming, and enriching, before it's truly ready to be examined.
Technologies
Data extraction uses diverse methods to gather insights. Web scraping automates website browsing for effortless data collection. API integration facilitates easy data and functionality sharing between apps. Text pattern matching and optical character recognition convert documents and images into editable text. Natural language processing accurately derives structured data using tools such as Python and TensorFlow.
Data ingestion typically involves using tools such as Apache NiFi and Apache Kafka and cloud-based services such as AWS Glue and Google Dataflow. The tools streamline data movement from source systems to warehouses, lakes, or other storage solutions, facilitating efficient data ingestion.
10X Efficiency with AI Data Extraction Solutions
Turn hours of data extraction into minutes of review with Docsumo AI.
Use Cases
Data extraction plays a crucial role in business by retrieving data from various systems. For example, finance teams may extract financial data from their ERP system into a centralized database for reporting and analysis. Customer service teams could pull customer information from their CRM to better understand customer needs.
Data ingestion in real-time offers distinct advantages, especially where immediate access to the latest information is vital. For instance, IoT and sensor applications collecting streaming data require continuous processing, making data ingestion essential. It's also used to consolidate real-time data from various sources into a central system, enabling the generation of interactive reports and deeper insights. Key industries such as financial services, healthcare, transportation, and retail heavily rely on data ingestion. It helps industries make split-second investment decisions, incorporate live patient data into treatment plans, maximize transportation efficiency, and refine marketing and store operations.
Choosing the Right Approach: Data Extraction or Data Ingestion
When deciding how to bring data into your analysis, you should consider factors like how much data they need to work with, how often it's updated, where it comes from, and your goals.
Extraction is suitable for business intelligence and analytics, pulling specific data from various sources on a scheduled basis, such as daily reports. Ingestion works best for real-time or near-real-time analytics, constantly feeding large data volumes into analytical models and algorithms.
Let's look at some important technical and economic factors to consider so you can make an informed decision.
Data Format
Data extraction can yield various formats, including CSV for simplicity and compatibility and JSON or XML for structured data, which are often used in database extractions and web scraping.
Data ingestion pipelines support standardized file types such as CSV and JSON for simple and structured data, XML for complex nested information, Parquet for massive datasets, and Avro for flexible schema synchronization.
Cost Considerations
Costs vary depending on the specific solutions, data quantities, qualities, and customization required.
Data extraction typically costs less due to its focus on subsets.
Data ingestion may offer greater long-term cost-effectiveness due to enhanced quality, consistency, and outcomes. Although startup fees are often higher, the insights and value gained justify the investment over the project's lifespan.
Real-Time Insights
Data extraction involves retrieving information from different sources in batches or at scheduled intervals. Since the data is processed periodically, it can limit real-time analysis and potentially delay new understandings.
Data ingestion facilitates a continuous streaming movement of data from its origins to destinations in real-time. It enables on-the-spot processing and insight generation, making the process suitable when up-to-the-minute information is vital for timely applications.
Accuracy
Data extraction results vary based on methods, skills, and data type. Careful technique usage is crucial to minimize errors. Approaches such as Support Vector Machines offer high accuracy, as shown in credit card fraud detection studies achieving 95% accuracy.
Data ingestion poses a challenge in organizing large volumes of data from various sources for downstream systems. Profiling the data during ingestion is vital to maintain consistent data formats.
Key Advantages
Data extraction helps you analyze segmented data from diverse systems. The process involves gathering insights from databases, cloud platforms, and web apps, offering tighter control over sensitive data. Automation saves time and reduces errors, enhancing efficiency. Analyzing extracted data reveals patterns for informed decision-making. With a comprehensive view, companies identify areas for improvement and stay ahead.
Data ingestion scales effectively, helping you rapidly process vast data volumes. Centralizing data streamlines analysis, improving its quality by structuring raw inputs. Integrating structured and unstructured sources yields comprehensive insights from diverse touchpoints such as social media. Moreover, ingestion facilitates swift issue identification and resolution, improving experiences and preempting potential problems.
Optimal Application Scenarios
Data extraction is preferable when data volumes are modest and can be handled offline without needing real-time or near-real-time analytics. You can also use data extraction when integrating diverse data sources into a unified database for analytics.
Data ingestion is ideal for handling large data volumes, reaching scales such as petabytes or exabytes, which are essential for cognitive analytics systems.
Future of Data Management: Combining Extraction and Ingestion
While promising on their own, data extraction and ingestion processes face inherent challenges that can introduce errors and inefficiencies if handled separately. Maintaining data quality, security, and governance becomes difficult without end-to-end visibility of the data lifecycle.
However, an integrated approach has the power to overcome these obstacles. By automating extraction and ingestion into a single, uninterrupted flow, you can achieve transparency and control. You can also identify and resolve any data accuracy, consistency, or protection issues before they impact analytics or decision-making.
For example, customer analytics teams benefit from continuously aggregating customer data from various sources, such as CRM, support tickets, CX software, and web activity. The integrated approach enables unified 360-degree views of customers.
Similarly, supply chain planners gain real-time visibility into inventory, orders, shipments, and more, facilitating proactive monitoring of global operations. Finance departments also benefit from streamlined financial reporting. The integrated strategy enables companies to automatically capture and combine transactions from ERP, payment, and general ledger systems into data warehouses.
As you can see, the integrated approach allows for more informed decision-making across your business. Certain platforms such as Docsumo support this integration by automatically processing documents to extract and prepare data for several purposes.
As a one-stop platform for automated document processing, Docsumo extracts and classifies data while preparing it for downstream use. Customers can make the best use of AI to extract structured outputs and then ingest these into their preferred systems through well-documented APIs.
By providing tools for unified extraction, classification, and ingestion in a single system, Docsumo truly helps businesses optimize their data assets. When extracted and ingested together, teams realize enhanced data-driven operations, reduced costs, and competitive advantage through data power.
Try Docsumo to achieve a competitive edge with efficient data extraction.
Additional FAQs: Data Extraction vs Data Ingestion
1. When should I use data extraction over data ingestion?
When your main focus is analyzing data from various sources rather than real-time processing, data extraction takes priority over data ingestion.
2. Can data ingestion processes improve the accuracy of the extracted data?
Yes, data ingestion processes play a crucial role in ensuring the accuracy of the extracted data. The process involves cleansing, validating, standardizing, enriching, and monitoring the data entering the system.
3. How do data extraction and ingestion fit into the larger data management ecosystem?
Data ingestion and data extraction are fundamental concepts in data management. They help you acquire, process, and transport data from diverse sources to a central repository for subsequent analysis and decision-making.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.

.webp)
.webp)
.png)