Suggested
12 Best Document Data Extraction Software in 2025 (Paid & Free)
Businesses utilize different data extraction techniques, from text pattern matching and data mining to manual data entry and natural language processing (NLP). This article discusses the top data extraction techniques in detail and evaluates the best data extraction tools with their features and reviews.


According to a 2023 Statista global survey, over three-quarters of respondents reported driving innovation with data, and half considered their businesses competing on data and analytics.
With an increasing focus on the importance of data-driven decisions, 87.9% of organizations consider investments in data and analytics as their top priority in 2024.
Data extraction and analysis facilitate accurate loan amount calculations, streamline supply chain operations, provide real-time insights into customer behaviors, mitigate risks, optimize spending, and detect fraud efficiently.
Here are the top 10 data extraction techniques for organizations to employ according to their business requirements:
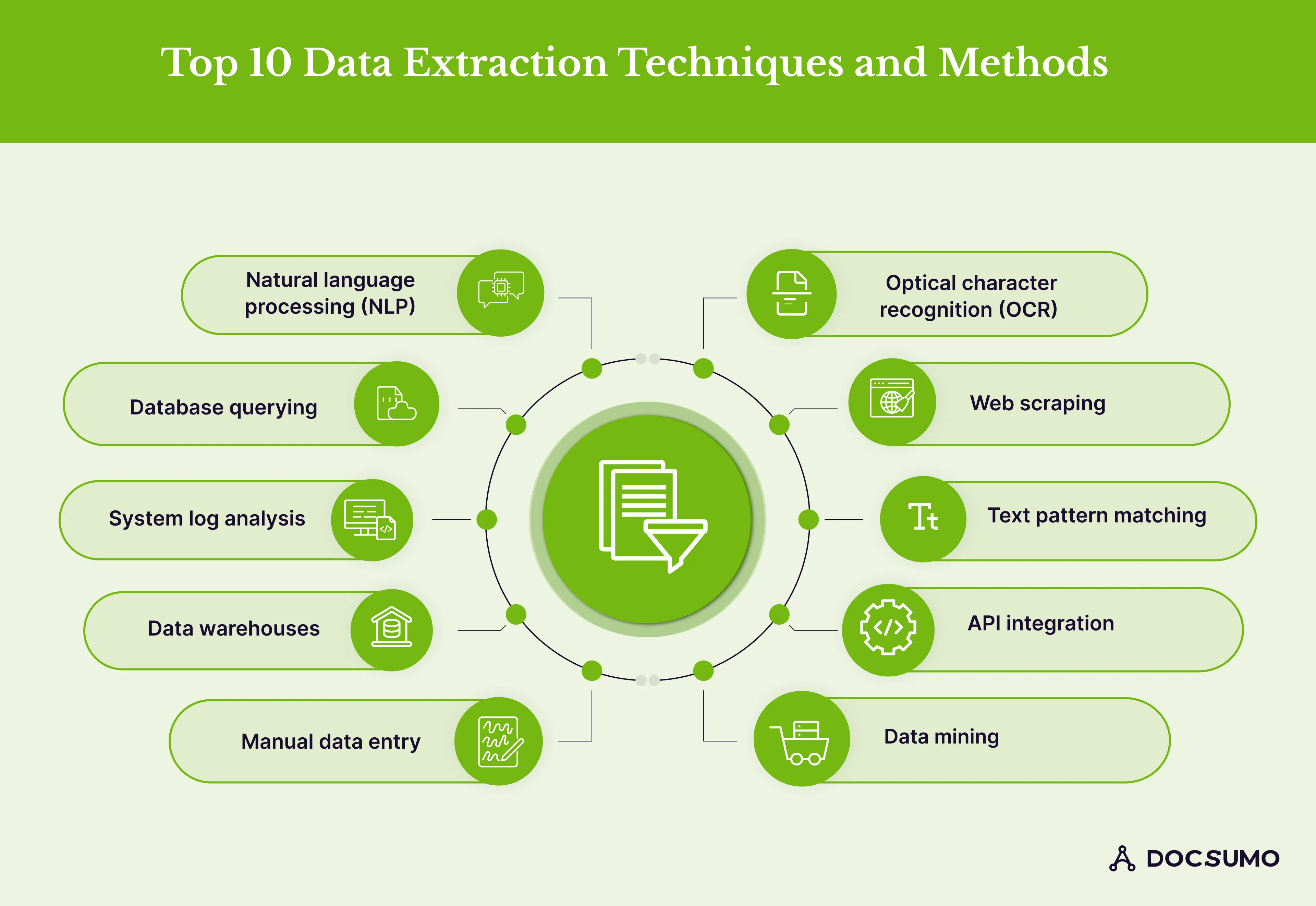
Web scraping refers to the automated process of extracting data from websites. It involves using software or scripts to retrieve specific information from web pages, text, images, and links, or converting it into a structured format for further analysis and storage.
The collected data is then converted into a suitable format for spreadsheets and APIs.L
While you can perform web scraping manually, the term typically refers to automated processes by bots or web crawlers. It is a method of gathering and copying specific data from the web, which is then stored in a centralized local database for later retrieval or analysis.
Individuals and businesses can use scraping tools or libraries instead of manually noting down key data points (name, address, prices, dates, etc.)
1. Using a web scraping tool, send an HTTP request to the target website's dedicated server to retrieve the HTML content of the web pages.
2. After a website grants access to the scraper, the HTML markup is parsed to identify and extract the required data elements. Parsing entails understanding the structure and arrangement of the HTML document and identifying particular HTML tags, attributes, or CSS selectors that are linked to the desired data.
3. The extracted and cleaned data is stored in a structured format such as CSV, JSON, or a database for future reference and further analysis.
An API integration provides fast and efficient access to large amounts of data from disparate sources. It serves as a bridge between different systems, facilitating smooth data exchange and simplifying the process of extracting data from diverse sources, including databases, websites, and software programs, eliminating the need for manual access to each source.
An API enables data centralization by consolidating all data and application sources into a unified platform. This centralization allows for data cleansing, preparation, and seamless transfer to the intended final destination, such as a data warehouse.
Banking, logistics, and insurance companies use OCR APIs to extract data from financial statements, invoices, and claims documents. Using a web scraping API to integrate the previously discussed data harvesting techniques with whatever app or project a particular business wants to implement is possible. This level of flexibility and adaptability is a crucial selling point of APIs in general.
1. After authenticating the user's identification with an API key, use the API documentation or instruction manual to make API calls to retrieve the desired data.
2. Once the API returns the data, you parse and extract the relevant information from the response. You may need to transform the data into a consistent format or structure suitable for analysis or storage in your system.
3. The extracted data can be integrated into your analytics platform, business intelligence tools, or data warehouse. You can combine it with data from other sources to perform comprehensive analysis, generate insights, and create reports or visualizations
In this data extraction methods, text pattern matching refers to finding specific patterns or sequences of characters within a given text or document. It involves searching for predefined patterns or regular expressions that match a desired format, structure, or sequence of characters.
It allows you to validate data and search for specific words, phrases, or patterns within a document or an extensive collection of documents.
Pattern matching techniques can range from simple string matching and regular expressions for natural language processing, such as grammar and speech recognition, to more advanced ML algorithms that help with complex fraud detection and financial analysis patterns.
1. First, you define the pattern you want to match. It can be regular expressions, keywords, phrases, or other pattern definitions to determine the sequence you wish to search for.
2. Provide the text or document where you want to search for the pattern. It can be a paragraph, a document, or even an extensive collection of documents.
3. The text pattern matching algorithm processes the pattern and text input to identify matches. The algorithm typically scans the text input character by character, comparing it with the pattern to identify matches.
4. Depending on the requirements, the algorithm may iterate through the text input multiple times to find all possible matches.
Optical character recognition (OCR) refers to the electronic process of converting images containing typed, handwritten, or printed text into machine-readable text. It can be performed on various sources, including scanned physical documents or digital images.
Industries like banking, healthcare, and logistics depend on OCR tools for data entry automation, document digitization, processing loan applications, bank statements, receipts, and invoices.
1. The OCR tool acquires an image by scanning physical documents, files or websites.
2. The acquired image is preprocessed to enhance its quality and optimize it for processing. Techniques involve deskewing, despeckling, script recognition, and various other adjustments.
3. It analyzes the preprocessed image and identifies individual characters or symbols using pattern matching or feature recognition. It matches the patterns and shapes in the image against a database of known characters.
4. After extraction, the text data is outputted in a digital format, such as PDF or word-processing document.
Data mining involves extracting and identifying patterns within extensive datasets by integrating machine learning, statistics, and database systems.
It enables informed decision-making, trend identification, and future outcome prediction. For instance, organizations utilize data mining to uncover patterns in customer behaviour and leverage customer feedback to enhance their products and services.
Similarly, financial institutions employ data mining to analyze credit card transactions and detect fraudulent activity.
1. The initial stage of the data mining process involves defining the data to be mined, establishing data collection and storage methods, and determining the desired presentation format.
2. The next step is cleaning, aggregating, and formatting the selected information. The transformation of this data is a crucial step that directly impacts the effectiveness and outcomes of the data mining process.
3. After choosing and evaluating the right models, the next step is to apply the data mining algorithms to the dataset to uncover patterns, relationships, and trends that may not be readily apparent. It involves discovering associations, predicting outcomes, identifying anomalies, or segmenting the data into meaningful groups.
Natural language processing (NLP) combines linguistics, computer science, and AI to explore the interaction between computers and human language. Its primary objective is to process and analyze vast volumes of natural language data effectively.
The ultimate goal is to enable computers to comprehend the content of documents, including capturing contextual subtleties and nuances inherent in language. By achieving this capability, NLP technology can accurately extract valuable information and insights while categorizing and organizing them.
NLP technologies like chatbots, email filters, smart assistants, language translation, etc., have several use cases, from social media sentiment analysis to client communication.
into: have several use cases, from social media marketing sentiment analysis to client communication.
1. The initial step involves preparing the text for analysis. It may include tasks like tokenization (breaking text into individual words or sentences), removing punctuation, converting text to lowercase, and handling special characters.
2. The next stage is called stemming or lemmatization, where the words are reduced to their root forms.
3. In the part-of-speech tagging stage, NLP assigns grammatical tags to words in a sentence, such as nouns, verbs, adjectives, or adverbs, to understand each word's role and syntactic context.
4. In the named entity recognition stage or NER, NLP techniques identify and extract named entities from the text, such as person names, locations, organizations, etc.
5. The next stage is Semantic analysis which focuses on understanding the meaning of words and sentences. It involves semantic role labeling, sentiment analysis, word sense disambiguation, and entity linking. Semantic analysis helps interpret the text's intended meaning, sentiment, and contextual nuances.
Database querying refers to retrieving or extracting specific information or data from a database. It involves using a structured query language, SQL (Structured Query Language), to interact with a database management system (DBMS) and retrieve the desired data based on specific criteria or conditions.
1. The first step is to define the query based on the data you want to retrieve. It includes specifying the tables and columns and any conditions or filters to narrow down the results.
2. Once formulated, the query is written in the appropriate syntax of the chosen database query language, such as SQL.
3. After writing the query, it is executed or run against the database. The DBMS processes the query and retrieves the requested data based on the specified criteria.
4. Once the query is executed, the DBMS returns the result set, which is the data that matches the query criteria. The result set can be further analyzed, filtered, sorted, or aggregated as needed.
The log analysis method reviews, extracts, and interprets systems-generated logs. It can be done manually or using log analysis tools.
This is one of data extraction methods, that uses various techniques, such as pattern recognition, normalization, anomaly detection, root cause analysis, performance analysis, and semantic log analysis.
Log analysis helps improve security by detecting threats and cyber attacks and mitigating associated risks.
Data warehouses are document management systems that collect data from various sources and store it in a centralized location for analysis.
With the statistical analysis and data mining, visualization, and reporting features of a data warehouse, analysts and scientists can analyze historical records to derive insights that streamline business decision-making.
Manual data entry is the process of manually employing data operators to input data into computer systems or databases. Businesses have been using this traditional data processing method for years. However, problems with manual data entry include increased errors and training costs.
These unavoidable risks with manual document processing have led businesses to adopt technologies to automate data extraction and achieve greater efficiency and accuracy.
Let's evaluate the best data extraction tools in 2024 with their features, pricing, and reviews. These tools uses innovative data extraction methods to accurately and efficiently improve workflow automation.
Docsumo is an AI-powered data extraction platform that helps enterprises extract data from structured, semi-structured, and unstructured documents.
Pre-trained API models in Docsumo automatically capture key-value pairs, checkboxes, and line items from documents, freeing up employees for strategic tasks.
Businesses can also train custom models to extract data according to their requirements. The platform also helps with data analysis by studying trends and patterns and deriving actionable insights that optimize business operations and spending.
Google Cloud’s Document AI helps businesses build document processors to automate data extraction from structured and unstructured documents. This generative AI-powered platform effectively classifies documents and extracts crucial data from PDFs, printed texts, and images of scanned documents in 200+ languages.
Additionally, it offers advanced features such as recognizing handwritten texts (50 languages) and math formulas, detecting font-style information, and extracting checkboxes and radio buttons.
Microsoft Azure employs machine learning algorithms to extract texts, key-value pairs, and tables from documents. The platform has pre-trained models that automatically capture vital data from common documents such as receipts, purchase orders, and invoices.
The custom extraction capabilities let businesses extract tailored, reliable, and accurate data from documents.
Custom pricing
AWS Intelligent Document Processing powered by generative AI processes unstructured data files, classifies documents, captures vital information, and validates data against databases.
AWS IDP helps healthcare, insurance, legal, public sector, and lending industries automate their respective document processing workflows and improve efficiency.
Additionally, the platform automatically detects discrepancies such as missing digits in phone numbers, missing files, and incomplete addresses to ensure maximum accuracy.
Custom pricing
IBM Watson’s Discovery lets businesses create models to process multiple documents and reports, capture data, and derive insights from them. The platform effectively discovers patterns and trends, helping businesses uncover hidden insights that can transform their specific business requirements.
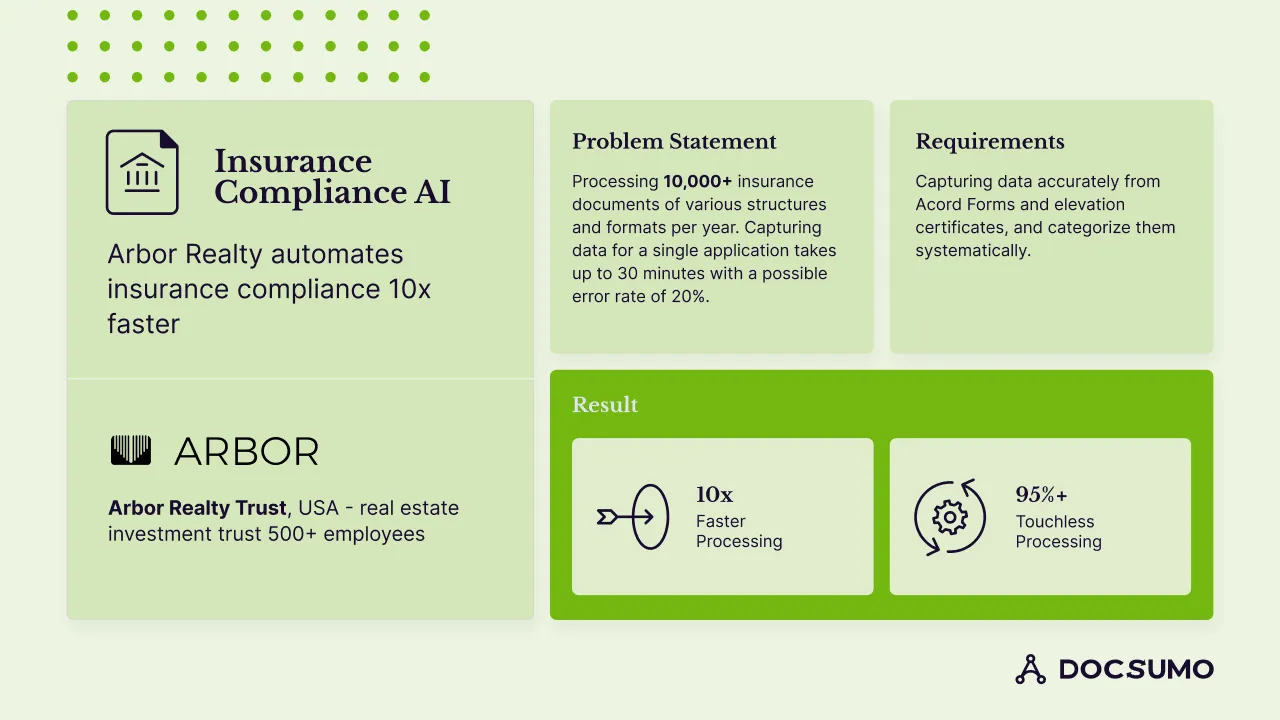
Here's how Docsumo helped Arbor, a real estate investment trust, automate insurance compliance by extracting accurate data from vital documents using its innovative data extraction methods.
Some of the many challenges that Arbor faced before implementing Docsumo were:
Docsumo’s AI-powered OCR solution:
The transformation and results are:
In Arbor Realty Trust CTO’s own words:
“Amongst others, the biggest advantage of partnering with Docsumo is the accuracy of the data capture they’re able to deliver. We’re witnessing a 95%+ STP rate, that means we don’t even have to look at risk assessment documents 95 out of 100 times, and the extracted data is directly pushed into the database”
- Howard Leiner, CTO, Arbor Realty Trust.
Data extraction tools automate the end-to-end document processing workflows, helping employees focus on strategic tasks. However, the accuracy of OCR technology is an important factor to consider while picking the right data extraction tool to avoid errors and inefficiencies.
After choosing the right OCR platform with a high accuracy rate, measure important metrics such as Character Error Rate (CER) and Word Error Rate (WER) and ensure good quality of original documents and scanned images to enhance precision.
Additionally, advanced techniques such as image rescaling, increasing contrast and density, binarization, noise removal, and skew correction will be employed to improve the accuracy of the OCR model and optimize efficiency.
Data extraction platforms like Docsumo, which integrate OCR technology with advanced AI technologies such as machine learning (ML) and natural NLP algorithms, will dominate the industry in the future because of their high adaptability and accuracy rate.
Sign up for a free trial of Docsumo and start extracting data with high accuracy.


Choosing the right extraction tool is critical to ensuring the integrity and security of the extracted data. Some factors to look for are robust security features, automation rate, adaptability, accuracy rate, scalability, and compliance. After assessing the features, take a free trial or book a demo session to understand the platform's functionalities.
Manual data extraction poses unwanted risks and unnecessary expenses in the long run. Unlike manual data extraction, document processing automation offers scalability, high security, and accuracy. Simply put, automated data extraction is better as it improves efficiency and productivity while reducing errors and costs.


