Suggested
12 Best Document Data Extraction Software in 2025 (Paid & Free)

.webp)
Structured data uses a schema or database model to organize and format data in a predefined manner. For example, the data is stored in tables and rows of any database or spreadsheet. Unstructured data, on the other hand, needs a predefined structure and is more challenging to organize in a format. Examples can be multimedia files, social media posts, etc.
Semi-structured data contains some organizational properties, like tags or metadata, but it does not adhere to a rigid schema like structured data. Some examples of semi-structured data are XML files and NoSQL databases. Demand for semi-structured data has grown significantly over the past few years, and more businesses depend on it to improve their business analytics and intelligence.
However, businesses must know how to extract semi-structured data to gather meaningful information. This article will discuss semi-structured data and explain how to extract and analyze it.
Semi-structured data can be referred to as data sets that are neither structured nor unstructured. It lies somewhere in between. These data sets cannot fit into relational databases or do not follow the tabular structure. Yet, it has some structural properties like tags and metadata.
Semi-structured data is a perfect blend of flexibility and complexity. This sets it apart in modern data extraction systems. For example, semi-structured data, such as JSON and XML files, does not require a solid schema like relational databases. This allows for including new fields or changes in data structure without making necessary alterations to the entire dataset.
Furthermore, data elements within semi-structured formats can be nested into different formats, offering flexibility in representing hierarchical relationships. Also, semi-structured data often enables a single field to accommodate various data types (e.g., strings, numbers, arrays) without explicit type declarations.
Suggested Reads: 5 Data Extraction Steps to Streamline Your Process
As semi-structured data has both organizational properties and flexibility in the schema, this flexibility benefits businesses, helping them manage and analyze data from various sources, adapt to changing data formats, and extract valuable insights easily.
.webp)
Based on their origin, semi-structured data comes in several formats. Some must be more structured, while others follow a fairly advanced hierarchical construction.
Javascript Object Notation, or JSON is an alternative to XML files. JSON files collect semi-structured data from IoT devices, web browsers, and smartphones. They organize the data in a human-readable format.
They have key-value pairs that support nested structures, making them flexible for complex data.
Example of JSON:

XML stands for eXtensible Markup Language. It uses tags to define data structure, allowing for hierarchy between elements. In web services, configuration files, and data interchange formats, XML documents are used.
Example of XML:
Comma-separated values are similar to Excel files but have data separated by commas. Each new line in a CSV file means a new database row. These files can transfer data in XLSX files to other programs that do not support such formats.
Example of CSV:

Log files, on the other hand, are generated by applications, servers, or devices and may follow a specific format.
Depending on the logged events, they can also include variable data fields and structures.
Example of Log files:
2024-04-03 10:15:20 - INFO - User logged in - Username: johndoe, IP: 192.168.1.100
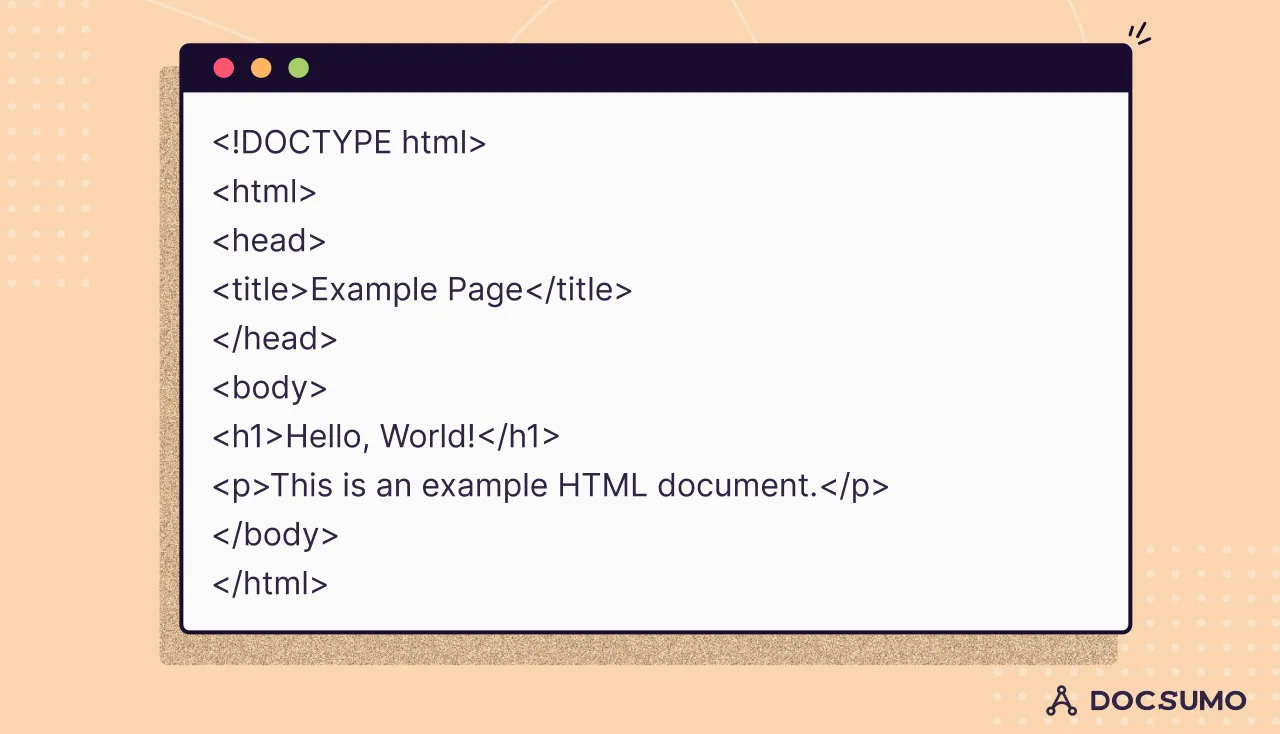
HTML is used to create web pages and web applications. These documents consist of a hierarchy of elements represented by tags.
Example of HTML:
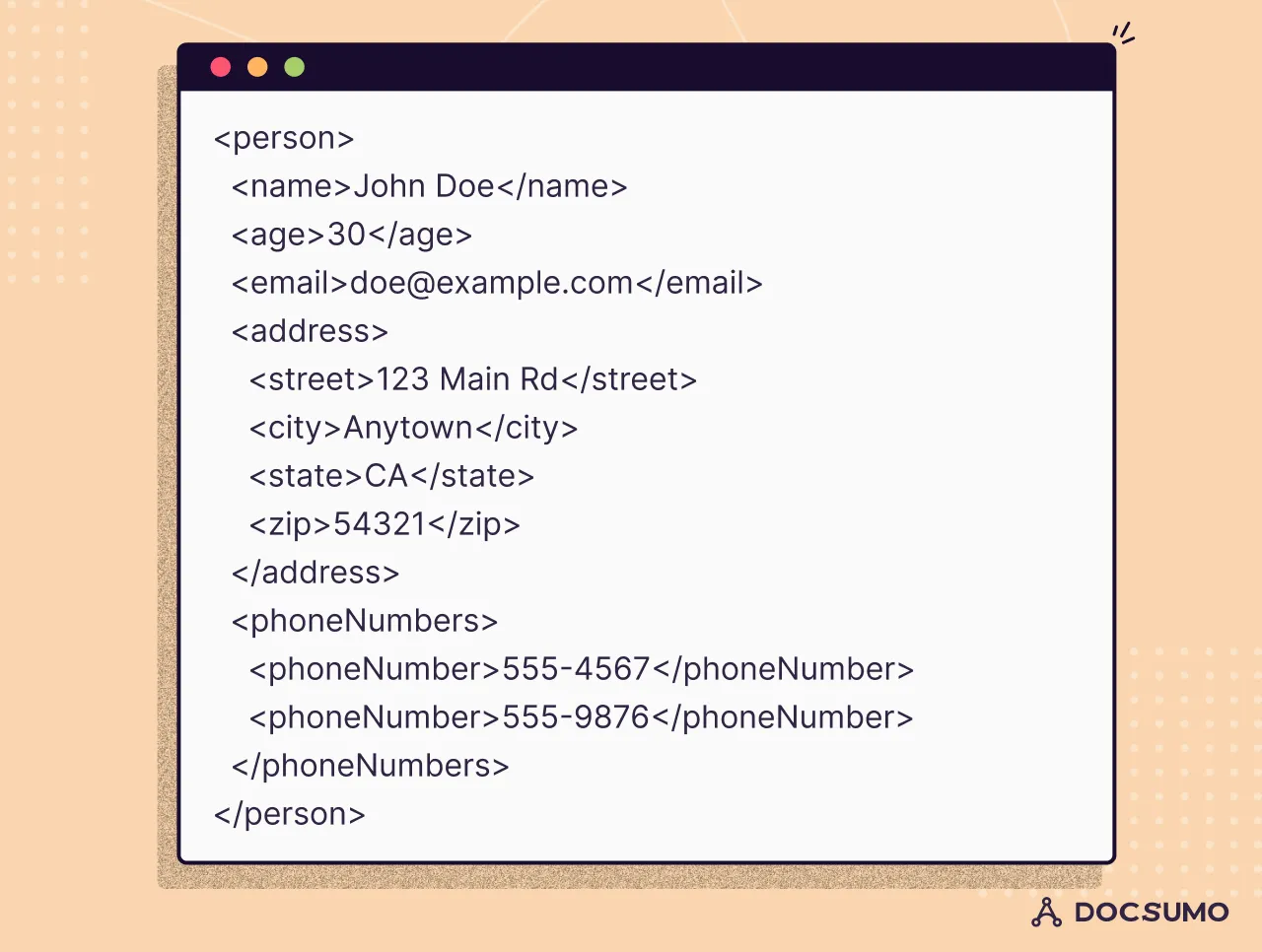
Emails contain semi-structured data. While the sender, recipient, subject, and message body can be structured, data content can vary based on the structure and format.
Example of email:

YAML files contain a human-readable data format. They are used to configure files and exchange data between programming languages. YAML allows for nested data structures and is less expansive than XML.
Example of YAML:

Semi-structured data can offer a lot to organizations when used correctly. Here are some of the advantages of semi-structured data:
Compared to traditional data formats like relational databases, semi-structured data are highly flexible. A strict schema does not have to be defined for these kinds of data; consequently, additional attributes can be attached easily without altering the entire set.
Such flexibility is critical for constantly changing environments where data schemes change regularly or frequently.
Integrating semi-structured data with other data formats is effortless. You do not have to go through a long conversion or transformation process to move this data around different environments. As a result, you can collect information from other sources seamlessly.
Semi-structured data can be added with additional contextual information using data augmentation techniques.
For example, in an eCommerce application, user interaction data, demographic information, purchase history, and browsing behavior could be added to enhance the context for user interactions and preferences.
Semi-structured data is highly scalable and capable of working with vast quantities of information in various formats. Given its adaptive capability, new data sources and formats can be integrated without significant modifications.
Scalability is essential in big data applications, IoT (Internet of Things) devices, and other systems that generate vast amounts of data.
Semi-structured data is a valuable tool that helps establish flexibility in how data can be presented and processed at different stages of iterative development cycles.
Agile teams can use specialized tools like NoSQL databases, JSON schema validators, and lightweight data transformation libraries to manage semi-structured data and ensure high-quality products. This makes developers more productive and allows them to quickly adapt to changing user requirements.
Semi-structured data can be stored in multiple ways, depending on the formats and requirements of applications and systems.
Document-oriented databases like MongoDB, Couchbase, or Amazon DocumentDB can store Semi-structured data in JSON or BSON format. Each document is allowed to have its unique structure.
Data storage systems, such as data lakes, are large repositories that can store a large volume of semi-structured data in its most raw format. These storage systems support multiple data types and formats and are cost-effective.
NoSQL databases can store semi-structured data as documents, columns, key-value pairs, etc. Supporting multiple schemas at a time, these databases are suitable for high-performance real-time read/write, which makes them ideal for processing semi-structured data with real-time applications or solutions.
Object storage systems offer features like versioning, encryption, and lifecycle management, making them suitable for storing large volumes of diverse data types, including semi-structured data. JSON, XML, or CSV can store semi-structured data as objects, typically in its native format.
Semi-structured data is stored in XML databases as individual XML documents, supporting hierarchical organization, indexing, and querying using XPath or XQuery. These databases provide features tailored for managing XML data, such as schema validation, full-text search, and document-level security. XML databases, such as eXist-db or BaseX, are efficient for storing and querying XML documents.
.png)
Businesses can Integrate semi-structured data into their workflows to enhance data-driven decision-making and operational efficiency.
Analyzing semi-structured data from IoT devices can predict failures early, enhance asset use, and reduce downtime.
Take Uber, for example. Uber obtains semi-structured information from its app, like GPS coordinates, ride history, traffic state, and weather, to manage pricing and route suggestions on demand.
An analysis of this information enables Uber to adjust prices for a particular place, time, or circumstance throughout the day and, in real-time, optimize routes for drivers with low waiting times and distance traveled while still maintaining efficiency; all these factors ultimately lead to a great customer experience.
E-commerce websites have enabled the customization of product recommendations and other promotional offers using semi-structured data from web analytics and browsing history, which provides optimal effectiveness and a greater chance of conversion into sales.
Consider the case of Amazon. It uses semi-structured data to analyze customers' browsing behavior, information on their purchasing history, and reviews, and segment the customer base to launch marketing campaigns. However, a key component of such success lies not only in data but also in the expertise of a skilled web designer, who ensures seamless navigation and enhances customer engagement
This adds an advantage since it predicts future buying behavior and creates personalized messages that are later shared through social media or emailed to customers with product recommendations.
It is important to note that when introducing search and indexing capabilities on semi-structured data repositories like data lakes, efficient data discovery will result in timely information for decision-makers to make strategic decisions and drive operational optimization.
Automating data extraction and transformation procedures from semi-structured sources, such as emails or PDFs, can significantly reduce manual work while increasing data quality for regulatory reporting.
By linking semi-structured information with structured data sources, analytical models can be optimized and provide complete details of the business cycle, making decision-making much more accurate.
Also, using machine learning algorithms on semi-structured data (such as clickstream data or sensor data) can help discover hidden patterns and correlations, identify new business prospects, and process optimizations for increased revenues and lower costs.
Several methods for extracting and analyzing semi-structured data are based on their formats. The standard techniques include:
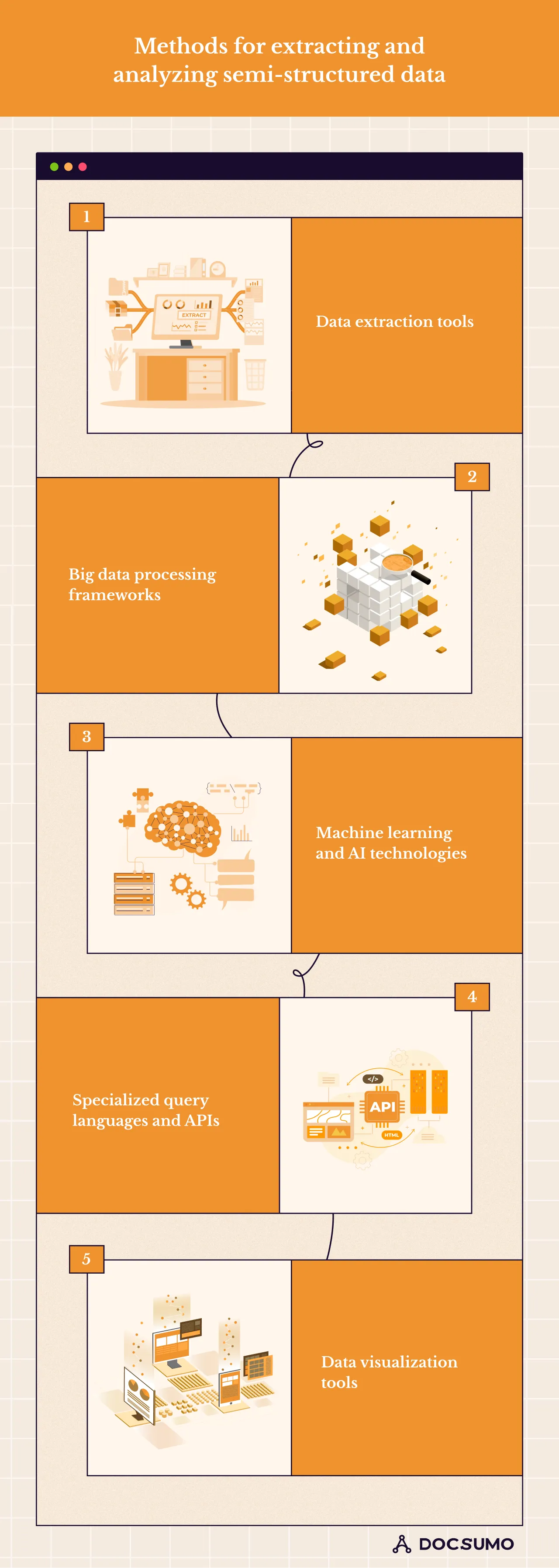
Several extraction tools can help you extract information from semi-structured data. Apache NiFi and Informatica can extract data from various sources and formats like JSON, XML, and CSV. These tools are ideal for defining extraction rules, mapping data elements to target destinations, and automating the extraction process using graphical user interfaces (GUIs) or scripting interfaces.
Many semi-structured data can be analyzed across distributed computing clusters using big data frameworks like Hadoop and Apache Spark.
They provide APIs and libraries that enable reading, transforming, and analyzing semi-structured data from distributed file systems or NoSQL databases. Examples include Apache Spark's DataFrame API or Hadoop's MapReduce programming model for processing semi-structured data at scale.
ML and AI can classify, cluster, and predict models for semi-structured data. These techniques include natural language processing (NLP), image recognition, and anomaly detection, which can be used to analyze unstructured or semi-structured data types.
When given a semi-structured data set, ML algorithms analyze patterns and relationships within the data to generate intelligent insights and provide predictions for the future.
Specialized query languages and APIs can retrieve information and analyze semi-structured data kept in databases or data lakes. JSONPath and XPath, for instance, are query languages that can be used to browse through and extract data from JSONs or XMLs.
Data visualization tools like Tableau, Power BI, etc., help visualize and explore semi-structured data using charts, graphs, dashboards, Excel, and more. These tools help users gain insights by visually representing patterns, trends, and relationships within the data.
Here are some common challenges and strategies to overcome these challenges for semi-structured data utilization:
As semi-structured data comes from different sources and in various formats, integration challenges can be faced. To overcome such challenges, you can implement data integration solutions and ETL (Extract, Transform, Load) processes.
You can also use data virtualization techniques to access and query data in its native format without physically moving it.
Semi-structured data need a well-defined schema, which can be challenging when enforcing data consistency and integrity. However, you can overcome this limitation using schema-on-read approaches, where data is understood and structured during analysis.
Additionally, analyzing and querying semi-structured data is time-consuming because of the nested structures and the need for a predefined schema. The data processing frameworks Apache Spark and Hadoop perform distributed processing of semi-structured data.
Semi-structured data may have inconsistencies, inaccuracies, and missing values that can lower its quality and reliability. Data cleansing and normalization can be used to identify and remove inconsistencies. You can also use profiling tools to check for data quality and establish data quality standards.
Processing vast sets of semi-structured data can be a computational bottleneck, affecting performance. Optimizing data processing pipelines and workflows for scalability and performance is beneficial in many scenarios.
Specifically, using techniques such as parallel processing and frameworks for distributed computing allows for distributing workloads across multiple nodes and clusters.
Semi-structured data may contain sensitive information, posing security and privacy risks. Implementing encryption, access controls, and data masking techniques is essential to secure semi-structured data at rest and in transit.
Organizations may need more skills and expertise to effectively utilize semi-structured data and related technologies. You must invest in employee training and development programs to enhance data analysis, engineering, and science skills.
Though semi-structured data is more complex to analyze than structured data, once you learn how to do this, you can use it to drive growth and innovation. For example, you can track customer reviews, engagement, and online interactions using semi-structured data.
This information can be used to provide them with more personalized experiences. The right tools, techniques, and strategic approach can help you extract insightful information from the semi-structured data.
Docsumo can accurately extract data from complex documents in just a few minutes. It eliminates the manual effort of data entry, reducing the chances of human error. Ultimately, this leads to an increase in operational efficiency and overall productivity.
Use Docsumo to Extract Data From All Complex Documents


Semi-structured data provides flexibility in data storage, enables the analysis of diverse data types, and facilitates the extraction of real-time insights for informed decision-making.
Unlike structured data with rigid schemas and unstructured data lacking schema, semi-structured data contains varying degrees of structure, allowing for schema evolution over time and supporting nested or hierarchical elements.
Essential tools for managing and analyzing semi-structured data include data integration platforms (e.g., Apache NiFi), big data processing frameworks (e.g., Apache Spark), NoSQL databases (e.g., MongoDB), and specialized query languages (e.g., JSONPath, XPath).


