
Suggested
Reinforcement Learning Optimization in Document AI: How Models Learn From Feedback

Schema mapping is the process of creating correspondences between fields in a source schema and fields in a target schema, along with any transformations that make the data compatible. Think of it as a translation layer: the source system speaks one language (its own field names, data types, and structures), while the target system speaks another.
A schema, in this context, is simply the structure that defines what data looks like. That includes field names, data types, whether fields are required or optional, and how fields relate to each other. When you extract data from an invoice, you get a source schema (the extracted fields). When you want to load that data into your ERP, you're working with a target schema (what the ERP expects).
The mapping itself is a set of rules. Some rules are straightforward one-to-one correspondences: invoice_date maps to INV_DATE. Other rules involve transformations: converting "$1,234.56" to a decimal 1234.56, or concatenating first_name and last_name into FULL_NAME.
For example: An invoice extraction system outputs {"vendor": "Acme Corp", "total": "$5,000.00", "date": "12/15/2024"}. Your ERP expects {"SUPPLIER_NAME": "ACME CORP", "AMOUNT": 5000.00, "INVOICE_DATE": "2024-12-15"}. The schema mapping defines three rules: rename and uppercase the vendor, strip currency symbols and convert to decimal, and reformat the date from MM/DD/YYYY to ISO 8601.
People often conflate schema mapping and schema matching, but the two solve different problems. Schema matching identifies that two fields are semantically related—it answers "do these mean the same thing?" Schema mapping goes further by defining how to actually transform data from one field to another.
Matching is typically a precursor to mapping. You might use ML-based matching to suggest that PO_NUM and purchase_order_number refer to the same concept, then define the actual mapping rule afterward (rename, no transformation needed).
The mechanics vary by context, but the core workflow follows a predictable pattern across four stages.
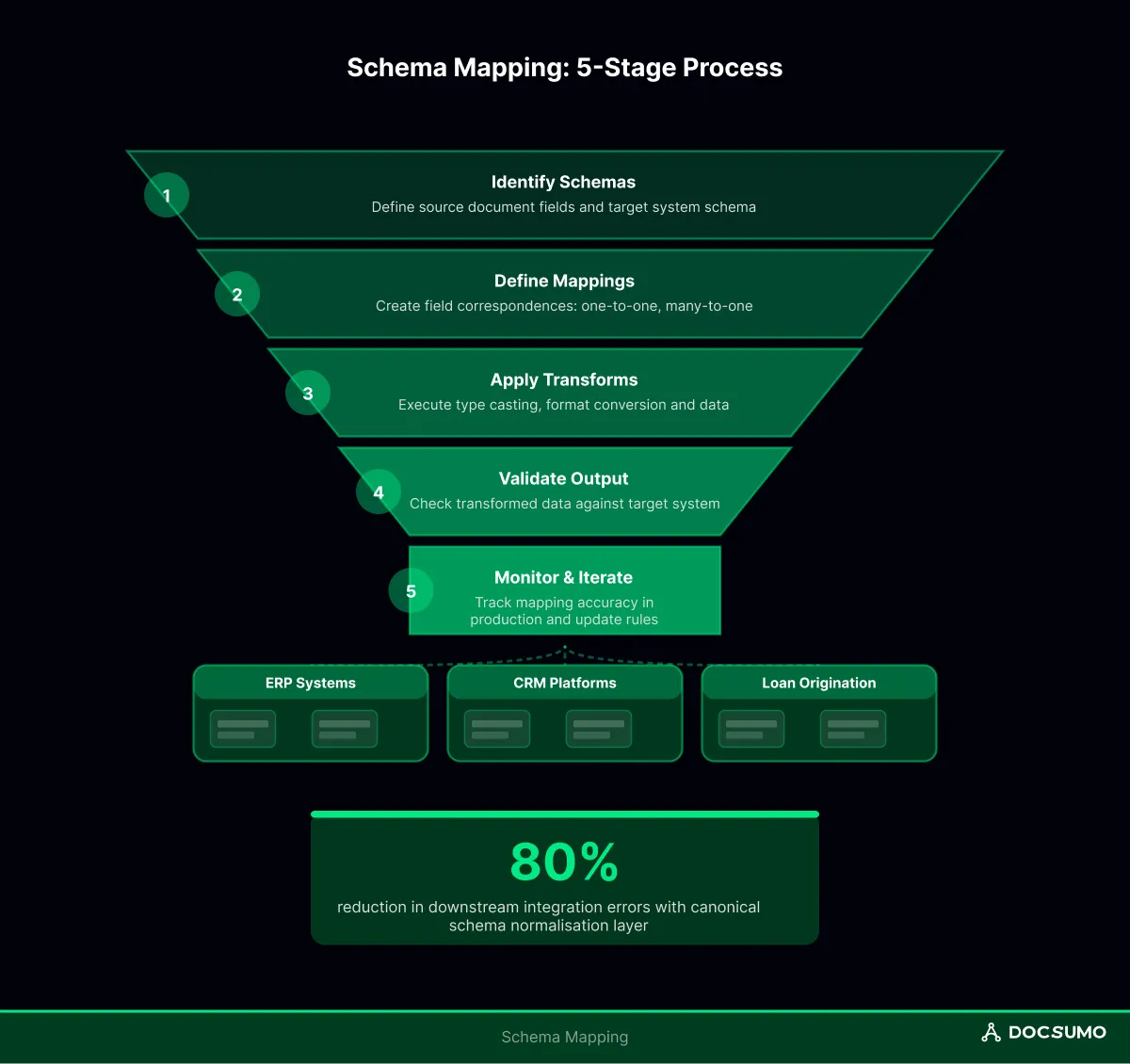
First, you define what you're working with. The source schema describes incoming data—field names, types, and nesting structure. The target schema describes what the destination system expects.
For structured database-to-database scenarios, both schemas are explicit and documented. For unstructured document workflows, the source schema is often implicit: it's whatever your extraction model outputs, which can vary by document type or even by vendor.
Next comes the actual mapping logic, where you specify which source fields connect to which target fields. Simple cases are one-to-one. Complex cases involve different patterns:
Raw field correspondence rarely suffices on its own. Transformations handle the messy reality of data format differences:
Before data reaches the target system, validation confirms that the mapping produced usable results. Validation includes checking that required fields aren't null, that types match expectations, and that values fall within acceptable ranges.
Document processing adds a wrinkle: the "source schema" isn't fixed. An invoice from Vendor A has different field names and layouts than one from Vendor B, yet both invoices need to land in the same ERP table.
The reliable approach uses an intermediate canonical schema. Extraction outputs get normalized to a standard internal format first, then mapped to the target system. This two-phase architecture (Extract → Normalize → Map) isolates document variability from integration logic.
For example: Your extraction model pulls Amount Due, Total, or Balance depending on the invoice. The normalization step maps all three variants to a canonical invoice_total field. The final mapping then translates invoice_total to your ERP's INV_AMOUNT—one rule instead of three.
Docsumo's workflow follows this pattern: extraction models handle document variability, validation rules enforce the canonical schema, and configurable mappings handle the last mile to downstream systems.
Tip: When designing a canonical schema, include fields that are stable across document types (invoice number, date, total) and handle vendor-specific fields as optional extensions. This approach reduces mapping churn when new document formats appear.
Line items on invoices, procedures on medical claims, shipment details on bills of lading—nested data is everywhere in document processing, and nested structures are where mappings frequently break.
The challenge is preserving parent-child relationships. An invoice header has one set of fields; each line item has another. The target system might expect a flat structure (one row per line item with header fields repeated) or a hierarchical one (header record linked to child records by key).
Several patterns work reliably for nested data:
Nested mapping fails when tables are split across pages, and extraction produces two separate arrays that require merging. Mapping also fails when line items have inconsistent columns (some rows have a discount, others don't). Robust mappings include null-handling rules for optional nested fields.
A mapping that "works" in testing can fail silently in production—the job runs, data lands in the target system, but values are wrong, truncated, or missing. Validation catches mapping issues before they become reconciliation nightmares.
A practical pre-production checklist covers several areas:
Testing against a representative corpus matters more than testing against happy-path samples. Include edge cases: the longest vendor name, the invoice with 200 line items, and the document with missing optional fields.
Get started for free with Docsumo's sandbox environment to validate mappings against production-identical conditions before deployment.
The job ran. No errors appeared in the logs. Yet downstream, totals don't reconcile, and approvals stall. Here's what typically went wrong:
The common thread across all five failure modes: they don't throw errors. They produce plausible-looking but incorrect data. Monitoring null rates, parse error counts, and reconciliation deltas catches drift before it compounds.
For high-volume, compliance-sensitive workflows, schema mapping requires more than field-to-field rules:
Docsumo provides configurable validation logic, comprehensive audit trails, and role-based permissions specifically for enterprises running document workflows at scale.
AI can assist with schema matching—suggesting likely field correspondences based on names and sample values—but fully automated mapping without human review introduces risk. Semantic similarity doesn't guarantee correct transformation logic, especially for edge cases. Most enterprise deployments use AI-assisted suggestions with human approval for production mappings.
Update frequency depends on upstream volatility. If source documents or systems change frequently (new vendors, updated forms, API version upgrades), expect quarterly or monthly mapping reviews. Stable integrations might run unchanged for years. Drift monitoring helps identify when updates become necessary rather than relying on fixed schedules.
ETL mapping typically works with structured sources (databases, APIs) where schemas are explicit and stable. Document schema mapping deals with semi-structured or unstructured sources where the "schema" is inferred from extraction and varies across document types. Document schema mapping requires an additional normalization layer to handle variability before standard mapping logic applies.
