
Suggested
Reinforcement Learning Optimization in Document AI: How Models Learn From Feedback
Exception handling typically means try-catch-finally blocks that intercept runtime errors before they crash a program. The system monitors code execution, catches specific error types when they occur, and runs cleanup logic regardless of whether an exception was thrown.
In document processing, the concept extends beyond code errors. Exception handling becomes the structured process of identifying documents or data fields that fall outside expected parameters, then routing them for resolution before bad data reaches downstream systems.
Think of it like a quality checkpoint on a factory line. When a product doesn't meet specifications, it gets pulled aside for inspection rather than shipped. Document processing exceptions work the same way - a low-confidence extraction or a validation mismatch triggers a diversion from the automated path.
The key difference from traditional software exceptions? Document processing exceptions are often expected at scale. You're not trying to prevent all exceptions. You're designing systems that handle them gracefully while maintaining throughput.
A single unhandled exception in a high-volume document pipeline can cascade into hours of manual cleanup. Consider a lending operation processing thousands of loan applications daily. If even a small percentage contains extraction errors that slip through undetected, those applications carry potentially incorrect data into underwriting decisions.
The cost compounds in several ways:
Exception handling transforms reactive firefighting into proactive workflow management. Instead of discovering problems after they've caused damage, you catch them at the point of origin.
Traditional software exceptions follow a predictable pattern. Code throws an error, a handler catches it, and execution either continues or terminates. The exception types are finite and well-defined: null pointer, division by zero, and file not found.
Document processing exceptions are messier. They emerge from uncertainty rather than clear-cut errors.
For example, an OCR engine might extract text from a smudged invoice with 60% confidence. That's not an "error" in the traditional sense - the system did its job. But the uncertainty creates an exception that requires human judgment to resolve.
The fundamental difference is that document exceptions often require interpretation, not just error recovery. A reviewer might need to decipher a handwritten signature or reconcile conflicting dates across pages.
Effective exception handling follows a predictable lifecycle. Each stage has distinct inputs, outputs, and ownership.

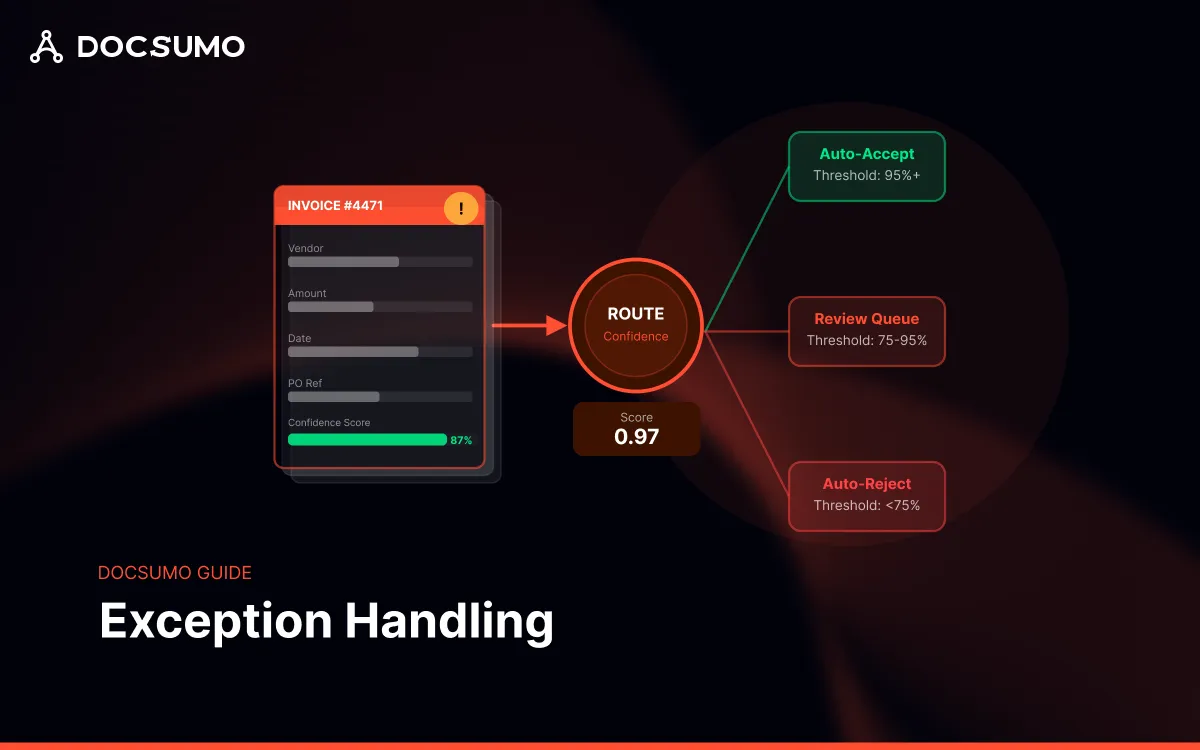
Exceptions surface through two primary mechanisms: confidence scoring and validation rules.
Confidence scores reflect model certainty. A field extracted with 65% confidence might warrant review, while 95% confidence level passes automatically. Validation rules, on the other hand, check extracted data against business logic. Does this invoice total match the sum of line items? Is this date in the future when it shouldn't be?
For example, A bank statement extraction returns an account balance of $1,234,567.89 with 92% confidence. The confidence passes the threshold, but a validation rule flags it because the value exceeds the customer's historical maximum by 10x. Both mechanisms caught different potential issues.
Once detected, exceptions route to appropriate queues based on type, severity, and required expertise.
A missing signature routes to document intake for customer follow-up. A complex table extraction failure routes to a specialist reviewer. A downstream API timeout routes to an integration retry queue.
Routing logic typically considers:
Resolution varies by exception type. Some resolve automatically through retries or fallback logic. Others require human intervention - a reviewer corrects the extracted value, confirms the classification, or approves an override.
The key is capturing what was changed and why. Without that audit trail, you lose the ability to trace decisions back to their source.
After resolution, the corrected data passes through validation again. This step prevents human errors from introducing new problems. If re-validation fails, the exception cycles back for additional review.
Resolved exceptions sync to downstream systems with full audit trails. The exception record closes only after successful delivery confirmation - not before. Marking something "handled" without proof of delivery is how silent failures happen.
Several architectural patterns appear across mature document processing implementations.
Rather than a single pass/fail threshold, many systems use three zones:
This approach balances automation rates against accuracy requirements. Tightening thresholds increases review volume but catches more errors. Loosening them improves throughput but accepts more risk.
Some documents repeatedly fail processing. Corrupted files, unsupported formats, or edge cases that crash extractors all fall into this category. Dead letter queues (DLQs) isolate these "poison pill" documents so they don't block the main pipeline.
A separate process handles DLQ items with different retry logic or manual intervention. Without this isolation, one bad document can stall an entire batch.
Integration exceptions often involve partial failures - the primary record was created successfully, but related records failed. Idempotent sync patterns use unique keys to ensure retries don't create duplicates.
For example, if a retry finds an existing invoice record with the same key, it updates rather than inserts. This prevents the receiving system from seeing two invoices instead of one.
Even well-designed systems encounter failure modes worth anticipating.
Enterprise document workflows require additional infrastructure beyond basic try-catch patterns.
Tip: Start with conservative confidence thresholds and loosen them as you gather production data. It's easier to reduce review volume than to recover from accuracy problems that reached customers.
Docsumo's validation layer implements cross-document checking and confidence-based routing with configurable thresholds per field type. The case management interface groups related documents for a 360° review context, while audit trails capture every correction for compliance reporting. Get started for free.
Exception handling in document processing isn't about eliminating exceptions - it's about making them visible, manageable, and auditable. The goal is a system where exceptions flow through structured channels rather than accumulating in email threads or spreadsheets.
Three principles guide effective implementation:
The difference between a prototype and a production system often comes down to exception handling maturity. Systems that handle the happy path are easy to build. Systems that handle everything else - gracefully, auditably, at scale - require deliberate architectural investment.
