Oops! Something went wrong while submitting the form.
A scanned loan application arrives with a handwritten income figure, a signature that overlaps the date field, and notes scrawled in the margin. The OCR engine that handles printed text flawlessly returns gibberish for the handwritten portions - or worse, confident-looking wrong numbers that slip into downstream decisions.
Handwriting recognition (HWR) is the technology that interprets handwritten input and converts it into machine-readable text, combining optical character recognition with neural networks trained to handle the natural variation in how people write. This guide covers how the technology works under the hood, where it reliably fails, and what separates consumer-grade tools from enterprise-ready document automation.
What is handwriting recognition
Handwriting recognition (HWR), sometimes called handwritten text recognition (HTR), refers to software that interprets handwritten input and converts it into machine-readable text. The technology combines optical character recognition (OCR) with machine learning - typically neural networks - to handle the natural variation in how people write.
Two modes exist. Offline recognition processes static images: scanned forms, photographed notes, faxed documents. Online recognition captures pen movements in real time on touchscreens or tablets. Most enterprise document workflows deal with offline recognition, since the handwriting already happened on paper before anyone scanned it.
The fundamental difficulty is variability. Printed text looks the same every time. Handwriting doesn't. Letter shapes differ between people, spacing is inconsistent, and cursive connections blur where one character ends, and another begins. A model trained on neat block letters often struggles with a rushed signature or a doctor's prescription.
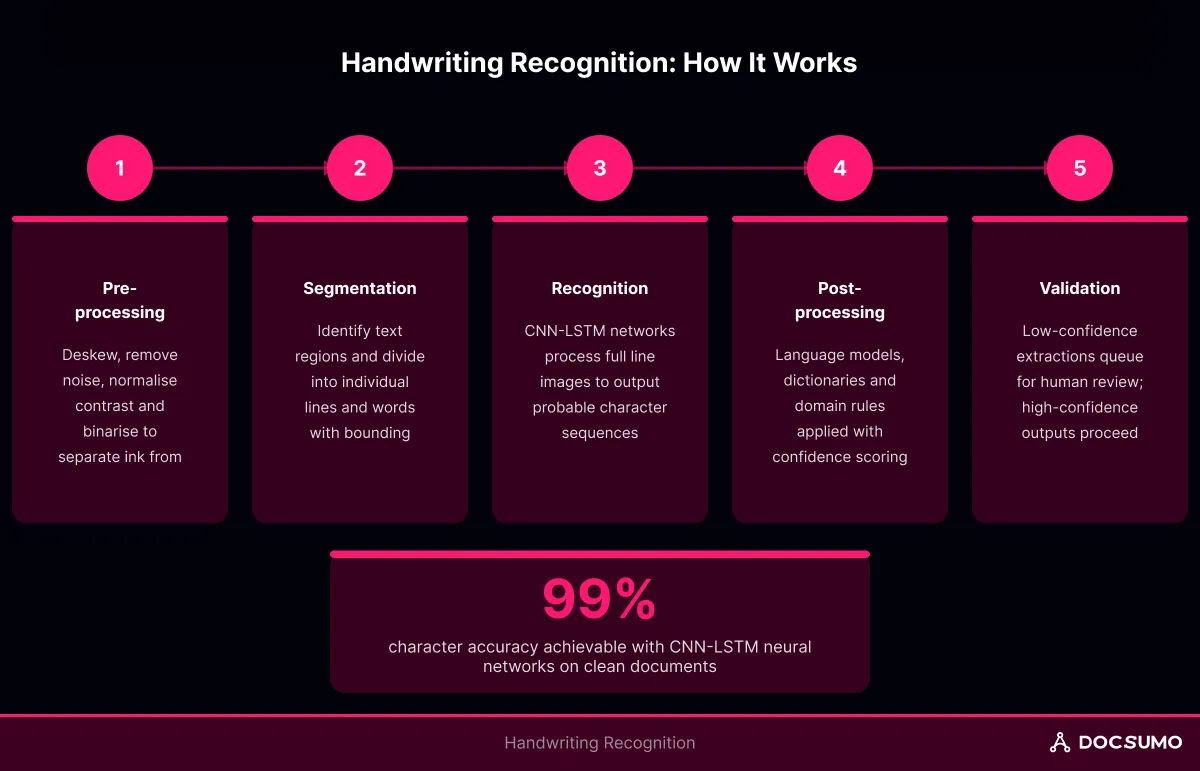
How handwriting recognition works
The process moves through four stages. Each stage has distinct inputs, outputs, and failure modes.
Pre-processing and image cleanup
Raw scans arrive in unpredictable condition. The system first corrects skew (pages scanned at an angle), removes noise (specks, shadows, scanner artifacts), and normalizes contrast so faint ink becomes visible. Binarization then converts the image to black-and-white, separating ink from background.
For example, A faxed insurance form might arrive at 150 DPI with uneven lighting across the page. Preprocessing upscales the resolution, applies adaptive thresholding to handle the lighting variation, and filters out background texture before any text detection begins.
This stage is often underestimated. Poor preprocessing cascades into every downstream step.
Line and word segmentation
Before recognizing characters, the system identifies where text exists on the page. Layout analysis detects text regions, then segments those regions into individual lines and words.
Segmentation is surprisingly fragile. Handwriting that drifts across ruled lines, crowds into margins, or overlaps with printed text confuses algorithms trained on cleaner layouts. The system outputs bounding boxes - coordinates marking where each text segment lives - along with a reading order.
Think of it like highlighting text before copying it. If the highlighting is wrong, the copy will be wrong too.
Character and sequence recognition
Modern systems skip letter-by-letter recognition. Instead, a neural network (often a CNN-LSTM architecture) processes entire line images and outputs probable character sequences. The model learns to handle connected letters, variable spacing, and stylistic quirks by training on large handwriting datasets.
The approach resembles reading a word as a whole shape rather than sounding out each letter. Context from surrounding characters helps resolve ambiguous ones - a squiggle that could be "a" or "o" becomes clearer when the surrounding letters spell "c_t" (probably "cat").
Each output comes with a confidence score indicating how certain the model is about its interpretation.
Post-processing and confidence scoring
Raw model output gets refined through language models, dictionaries, and domain-specific rules. A date field might be constrained to valid date formats. A name field might be checked against a customer database.
Confidence thresholds: Outputs below a certain confidence level get flagged for human review rather than flowing directly into downstream systems.
Format validation: Extracted values are checked against expected patterns (phone numbers, dates, ID formats).
Cross-field checks: The system compares related fields - does the birth date make the person a plausible age for the loan they're applying for?
Low-confidence outputs route to exception queues. High-confidence outputs proceed automatically. The threshold calibration determines how much human review the workflow requires.
Offline versus online handwriting recognition
Aspect
Offline Recognition
Online Recognition
Input source
Scanned images, photos
Stylus or finger on touchscreen
Available data
Pixel patterns only
Stroke order, pressure, timing
Typical accuracy
Lower (less signal)
Higher (richer signal)
Common use case
Form processing, document digitization
Signature capture, note-taking apps
Offline recognition is harder because it works with less information. Online systems know how someone wrote - the sequence of strokes, the speed, the pressure changes. Offline systems only see the final result.
The difference is like reconstructing a conversation from a transcript versus having the original audio recording. The transcript loses tone, pacing, and emphasis. Similarly, a static image loses the temporal information that makes handwriting easier to interpret.
Enterprise document processing almost always involves offline recognition, since paper forms get scanned after the fact.
Where handwriting recognition fails
Even well-trained models break down in predictable scenarios. Knowing the failure modes helps set realistic expectations.
Degraded image quality: Faded ink, low-resolution scans (below 200 DPI), or heavy JPEG compression destroy the visual signal the model depends on.
Overlapping characters: Cursive writing where letters merge, or cramped handwriting where characters physically touch, defeats segmentation.
Non-standard layouts: Handwriting that ignores form fields, wraps around printed text, or runs vertically confuses layout analysis.
Mixed scripts: A form with English names and Chinese addresses requires multi-language model support, which many systems lack or handle poorly.
Genuinely ambiguous characters: Even humans struggle with "1" versus "l" versus "I", or "0" versus "O". Without strong context, some ambiguities are unresolvable.
For example: A delivery confirmation with a signature scrawled across the "received by" field, a date written sideways in the margin, and a phone number where the 7s look like 1s. Each problem individually is manageable. Together, they cascade into extraction failures that require human intervention.
The practical implication: handwriting recognition works best on forms designed for it - clear fields, adequate space, instructions to print rather than write cursive.
Accuracy metrics and what they actually measure
Two metrics dominate handwriting recognition benchmarks:
Character Error Rate (CER): The percentage of characters incorrectly recognized, inserted, or deleted compared to ground truth.
Word Error Rate (WER): The same calculation at the word level.
Here's the catch. A 5% CER sounds impressive until you realize that in a 10-field form, errors might appear in half the fields. A single wrong digit in a date or amount can invalidate the entire extraction.
Field-level accuracy - did the system get the complete "Date of Birth" field correct? - matters more for operational workflows than aggregate character statistics. A system with 95% CER but poor field-level accuracy creates more rework than one with 90% CER concentrated in non-critical fields.
Vendor benchmarks often reflect controlled test conditions: clean scans, legible handwriting, standard layouts. Production documents are messier. Testing on your own documents, with your own quality variation, gives a more realistic picture.
Enterprise use cases for handwriting recognition
Handwriting recognition becomes valuable wherever paper forms persist despite digitization efforts.
Lending and banking: Loan applications, account opening forms, and signature verification on checks still involve handwritten elements mixed with printed text.
Healthcare: Patient intake forms, consent documents, and physician notes contain handwritten data that feeds into electronic health records.
Insurance: Claims forms, accident reports, and policy applications mix printed and handwritten sections across multiple pages.
Logistics: Proof-of-delivery confirmations, customs declarations, and warehouse receiving logs capture handwritten signatures, dates, and notes.
The common thread is high-volume, time-sensitive workflows where manual transcription creates bottlenecks. A lending team processing hundreds of applications daily can't afford to manually key every handwritten field.
What makes handwriting recognition enterprise-ready
Consumer handwriting apps and enterprise document platforms solve different problems. Enterprise readiness involves several capabilities beyond basic recognition.
Confidence-based routing: Low-confidence extractions automatically queue for human review rather than silently passing bad data downstream.
Cross-document validation: The system checks extracted values against other documents in the same case - does the name on the application match the name on the ID?
Audit trails: Every extraction, review, and correction gets logged with timestamps and user IDs for compliance and quality monitoring.
Integration APIs: Extracted data flows into CRMs, ERPs, loan origination systems, or claims platforms through structured outputs (JSON, XML, webhooks).
Security and compliance: SOC 2, HIPAA, and GDPR alignment for handling sensitive documents, with configurable data retention and access controls.
Docsumo's platform treats handwriting recognition as one component in a controlled workflow. Extraction feeds into validation rules. Validation routes exceptions to review queues with confidence thresholds. Clean data syncs to downstream systems with full audit visibility. The architecture assumes errors will occur and builds controls around them.
How to evaluate handwriting recognition tools
Before committing to a vendor, testing on representative documents from your own workflows provides more useful information than vendor-supplied demos.
Build a representative test set: Include best-case, typical, and worst-case samples. Stratify by document type, handwriting legibility, and image source (scanner, phone camera, fax).
Establish ground truth: Have humans transcribe the test set. For ambiguous handwriting where humans disagree, document the disagreement - if people can't agree, the system won't either.
Measure field-level accuracy: Track whether each field extracted correctly, not just aggregate CER or WER.
Map accuracy to operational impact: Calculate rework time, error cost, and automation rate. A 90% accurate system with good confidence routing might outperform a 95% accurate system that doesn't flag uncertain outputs.
Tip: Request a sandbox environment to test with production-representative documents before signing contracts. Vendors confident in their accuracy typically accommodate this request.
Red flags during evaluation include vendors who only demo on their own sample documents, accuracy claims without methodology details, or reluctance to provide test environments.
When handwriting recognition becomes essential
Three triggers typically push organizations from manual transcription to automated recognition:
Volume thresholds: Processing more than a few hundred handwritten documents per day makes manual entry unsustainable from a staffing and cost perspective.
Speed requirements: Same-day or real-time processing SLAs can't accommodate transcription queues that back up during peak periods.
Error cost: When a misread date or amount creates compliance violations, fraud exposure, or customer harm, automation with validation controls becomes safer than fatigued humans making transcription errors.
The goal isn't eliminating human review. It focuses human attention on genuinely ambiguous cases while automating the clear ones. A well-tuned system handles routine extractions automatically and surfaces only the difficult cases for review.
Summary
Handwriting recognition converts handwritten text into structured, machine-readable data through preprocessing, segmentation, neural network recognition, and post-processing with validation. Accuracy depends on image quality, handwriting legibility, and layout complexity. Enterprise implementations require confidence scoring, validation rules, exception routing, and audit trails to prevent extraction errors from becoming decision errors.
For organizations processing high volumes of handwritten documents, the technology shifts the bottleneck from data entry to exception review - a meaningful operational improvement when paired with proper workflow controls.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.