Unstructured Data Processing Using Intelligent Document Processing (IDP)
Learn how Intelligent Document Processing (IDP) transforms unstructured data into actionable insights. Explore its applications in automating data extraction, improving accuracy, and enhancing efficiency across various industries.

.webp)
From texts and emails to receipts and invoices, most business data flowing through your organization lacks structure, making it difficult to process and analyze.
Intelligent Document Processing (IDP) is an automation technology that structures large amounts of data from several sources (images, PDFs, and invoices among many others) into neatly organized formats, saving you the burden of manual data entry.
In this article, we decode how IDP converts unstructured and semi-structured data into organized, structured data that helps you enhance your business efficiency, reduce dependence on manual data entry, and make wiser business decisions.
Understanding Unstructured Data & Intelligent Document Processing (IDP)
What is unstructured data?
Unstructured data refers to any data that is not arranged into a pre-defined data model or schema. In other words, it is data that is not categorized neatly into rows and columns, as in a spreadsheet or other database management systems.
Think of emails, invoices, bank receipts, PDFs, or images—they all contain data but it’s not categorized as such into a classified format.
Considering only 18% of organizations in a survey by Deloitte reported being able to take advantage of such data, you must be able to automate unstructured document data extraction to become an insights-driven organization.
Also, factoring that the majority of data (80-90%) according to multiple estimates is unstructured information from different sources, there’s a huge untapped potential for companies to automate unstructured data extraction for further use.
What is Intelligent Document Processing (IDP)?
Intelligent Document Processing is a workflow automation technique that uses technologies like artificial intelligence (AI), machine learning (ML), optical character recognition (OCR), and computer vision (CV) combined with robotic process automation (RPA) to scan, read, interpret, clean, and organize large sets of data from various sources into coherent information that can be organized into databases for easy processing and analysis.
An IDP software eliminates the need to enter data into systems manually, provides over 99% accuracy in several cases, and reduces the time it takes to extract and process data. It also flags low-confidence data that human agents can later verify.
The main benefit of using intelligent document processing software is that it reduces the dependency on human agents to process large amounts of data manually.
Challenges in processing unstructured data
.webp)
1. Lack of structure
Structured data is often organized in a tabular format under different attributes in relational database management systems. For instance, you may have a structured database with attributes like customer name, contact number, address, and email. You can easily use this data in different aspects of your business and load it into your CRM or other business software.
In contrast, unstructured data lacks a predefined format and is not organized under specific attributes, making it difficult to organize and categorize using data mining systems.
2. Heterogeneity
Unlike structured data, which is mostly in text-based formats, unstructured data comes in several file formats, including multimedia, like images, videos, and audio. It may even contain multilingual textual elements.
Unstructured textual data can come from diverse sources, each with its own writing styles, conventions, and formats. Similarly, images and videos can be coded in different formats and metadata.
The heterogeneity of unstructured data makes it difficult to process as each element requires specific approaches to be extracted, and manual data extraction is time-consuming and error-prone.
3. Volume and velocity
Unstructured data in organizations is typically much larger in size than its structured counterpart, contributing to a high data volume. For many organizations, storing this data isn’t a big challenge, but storing it and analyzing it as quickly as soon as it arrives in real-time is a far-fetched dream.
In an ideal situation, you want extremely fast data ingestion along with fast and real time analysis.
4. Quality and accuracy
Unstructured data has noise, ambiguity, duplication, or errors which make extraction challenging.
Docsumo, one of the most widely used IDP software, lets you bring all your data files in various formats for faster processing. Book a free demo now and see how Docsumo quickly processes tons of data floating around in your organization.
5. Semantic ambiguity
Semantic ambiguity indicates how the meaning of the data can be unclear or open to interpretation due to linguistic nuances, context, or subjective factors.
Homonyms and polysemous words, for instance, could introduce ambiguity into textual data. Ambiguity also arises when data lacks enough context, and it is hard to understand its meaning in isolation.
6. Regulatory compliance and privacy
Since unstructured data is scattered and unmonitored, compliance with data protection laws like the GDPR, CCPA, or HIPAA may be difficult.
Unstructured data also contains customers’ personally identifiable information (PII), and data breaches or mishandling can cause reputational or legal consequences. IDP for unstructured data makes it more manageable and easier to visualize, so you are in control of what data flows into your organization.
Document Processing Made Easy with AI
.png)
The Role of Intelligent Document Processing in Structuring Unstructured Data
Let’s examine the techniques IDP platform use to structure large volumes of data as accurately as possible.
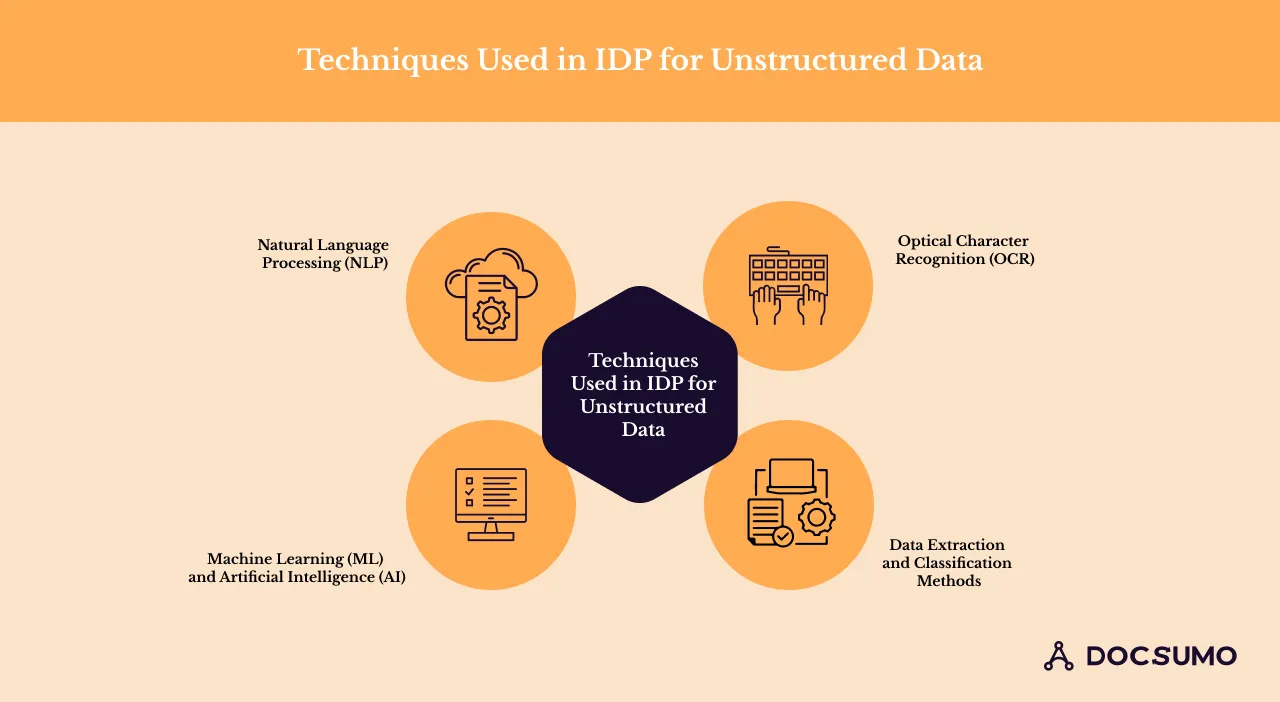
1. Natural Language Processing (NLP)
NLP is a subset of AI focusing on interactions between computers and human language. In IDP systems, NLP techniques are used to understand, interpret, and extract meaning from unstructured text data. Common techniques used for NLP driven data extraction include:
- Tokenization: Segments a text document into smaller units called tokens, which can be words, phrases, symbols, or other meaningful elements
- Part-of-Speech (POS) Tagging: Assigns a grammatical category (e.g., noun, verb, adjective, adverb) to each token in a text. Methods include Rule-Based Tagging, which uses linguistic rules and dictionaries, and Statistical tagging with Hidden Markov Models (HMMs) or Maximum Entropy Markov Models (MEMMs) to model the probability of a tag sequence given a word sequence
- Sentiment analysis: Locates the subjective information (e.g., opinions, emotions, attitudes) expressed in the unstructured data and is typically classified as positive, negative, or neutral
2. Optical Character Recognition (OCR)
Optical Character Recognition (OCR) converts printed or handwritten text in images or scanned documents into machine-readable text. In IDP systems, OCR digitizes physical documents and makes them accessible for further processing and analysis.
3. Machine Learning (ML) and Artificial intelligence (AI)
ML and AI enable IDP systems to learn from data and improve their performance over time. ML algorithms are usually trained on labeled datasets to recognize patterns and make predictions or decisions.
For instance, in email categorization, ML models can be trained to automatically classify incoming emails into different categories like "urgent," "important," "promotional," or "spam."
4. Data extraction and classification methods
Data extraction and classification methods are essential for organizing and categorizing the unstructured data extracted from various sources. Common data extraction methods use rule-based approaches, pattern matching, or ML algorithms to identify and classify relevant information.
For instance, rule-based approaches rely on predefined rules or patterns to identify specific information within unstructured data.
In the legal domain, IDP systems are tied deeply to contract analysis. They employ the aforementioned techniques to automatically identify and classify specific clauses within contracts, such as "indemnity," "termination," or "confidentiality." Doing so significantly speeds up the legal review process and ensures that critical clauses are not overlooked.
How Intelligent Document Processing structures unstructured data
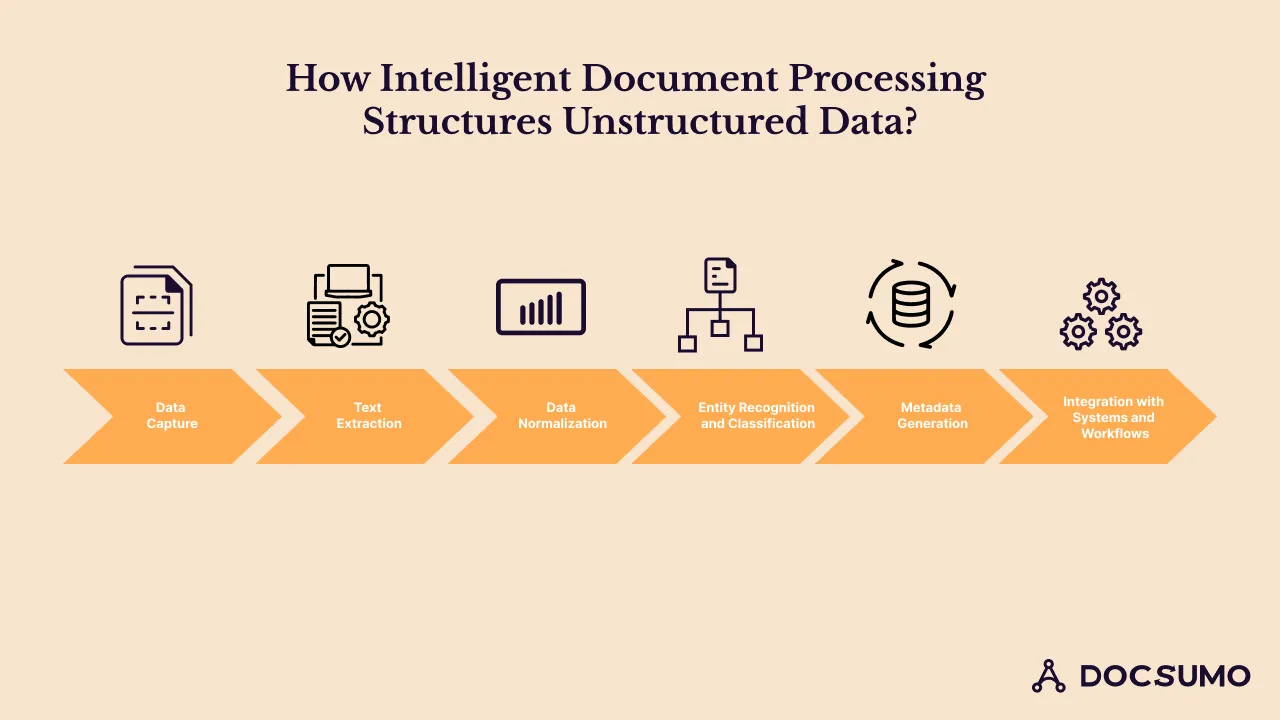
1. Data capture
Intelligent Document Processing (IDP) software has pre-built APIs you can integrate into your existing systems to ingest varied forms of data into the IDP software. Once ingested, IDP begins the process of capturing ingested data from different files.
For instance, it processes image data with techniques like noise reduction, cropping, or deskewing before classifying and extracting information for various fields.
2. Text extraction
IDP systems use entity recognition or text localization technologies to extract meaningful data from huge text files by understanding their textual and visual layouts.
It can also recognize checkboxes, signatures, etc., to ensure the most relevant text is always picked up. Once the text is extracted, relevant fields like names, addresses, and invoice numbers are identified before being refined for spelling or formatting issues.
3. Data normalization
Data normalization involves removing duplicate textual entries and organizing data into standardized formats to ensure that processed data is clean and coherent. IDP uses normalization to ease data analysis by converting inconsistent data from several sources in different formats into a singular format.
For instance, different date formats across documents can be converted to one standardized format of DD-MM-YYYY.
4. Entity recognition and classification
Powered by NLP, entity recognition and classification involve identifying names of persons, organizations, locations, or dates from huge volumes of unstructured data.
Named Entity Recognition (NER) works in two steps: entity detection (which involves tokenizing or breaking down a sentence's strings into tokens and understanding their semantic significance) and classification (which involves classifying recognized entities into specific categories such as name, place, or date).
5. Metadata generation
It typically includes attributes like creation date, file size, and file type. IDP identifies and generates metadata to provide additional context and information about extracted data to facilitate organization and retrieval. IDP can also extract custom metadata tailored to an organization's or industry's specific needs.
6. Integration with systems and workflows
Once data is extracted and validated, it can be used in workflows and integrated into systems like your CRM or ERP. Scalable solutions like Docsumo turn unstructured data into organized records, so you don’t need to worry about handling data as your business grows.
Real-World applications of unstructured data handling using IDP
Let’s explore some of the different use cases of IDP for unstructured data handling across a few industries.
1. Finance and banking sector
The financial services sector usually deals with a lot of paperwork, including several types of forms, invoices, receipts, loan applications, and more. IDP can automate the task of quickly organizing data from these disparate documents with substantial accuracy, thus decreasing the load on human agents.
IDP streamlines the processing of invoices and documents for accounting teams and provides structured data for further automation in other processes.
Docsumo, helped PayU streamline data extraction from 7 different types of unstructured documents, reducing their dependency on 500+ underwriters processing 100,000+ applications every week, opting for manual intervention only in exceptional cases. They could analyze bank statements with 100+ layouts from 100+ banks with 95%+ accuracy.
2. Healthcare industry
Unstructured data handling with IDP can make it easy to process and analyze patients’ medical records from various documents. It can speed up patient care by storing patient information in neat databases, saving healthcare staff from manually reading multiple patient reports.
It can help expedite loan or insurance processing and make analyzing and maintaining financial records easier.
3. Legal and compliance departments
Legal documents contain tons of data and are often lengthy and time-consuming to manually read and process.
Automation techniques like IDP can organize and retrieve key legal data in minutes, such as obligations, terms and conditions, or important dates. IDP can also help with legal research by analyzing large volumes of legal literature, cases, or judgments.
4. Government and public sector
IDP automates manual data entry and can quickly convert data from paper-based documents into digital, tabular formats.
The National Archives and Records Administration has cleared a pandemic-era backlog of over 600,000 requests for veteran records, facilitated by increased funding and modernization efforts. This success highlights the necessity of efficient data processing systems like Intelligent Document Processing (IDP), which can help government sectors handle large data volumes.
Conclusion
An IDP platform combines several technologies to extract, organize and process unstructured data. If you need an IDP solution for large-scale unstructured data extraction,sign up on Docsumo.
Docsumo’s highly customizable IDP solution easily ingests any kind of document via emails, API, cloud drive, or local machine and then captures and structures their data with over 99% accuracy.
Create Excel-like rules to validate extracted data within your document, across documents, or against a database and pre-configured APIs help you get started quickly and easily, regardless of your industry.
Automate processes like data entry and extraction, building 10X efficiency for your teams and business processes. Try Docsumo for free now!
Frequently Asked Questions
What are the unstructured data extraction methods?

1. NLP uses sentiment analysis or opinion mining to determine the tone of data using emotion detection, graded and multilingual analysis 2. NER classifies identifiers in predefined categories using ML 3. Topic modeling with Latent Dirichlet Allocation (LDA), summarization, and text classification are other methods to extract unstructured data
What are the key benefits of implementing IDP for unstructured data?
When you implement IDP, 1. Unorganized data is scanned, read, cleaned, and organized regardless of the size and complexity of the dataset 2. You no longer need to sort unstructured data into coherent, usable data blocks manually 3. You cut back on the time and resources needed to process data
How does AI process unstructured data?
AI processes unstructured data with technologies like deep learning, NLP, computer vision, and OCR to ensure it accurately captures large amounts of data from several sources.
How do you extract data from unstructured data?
To extract data from unstructured data, you must follow these steps: 1. Clean the acquired unstructured data to maintain data quality 2. Use feature extraction to convert unstructured data into structured features that ML systems can understand 3. Train ML models using the preprocessed data 4. For text-based NLP techniques, use OCR 5. Apply NLP methods for the segregation of the unstructured data 6. Extract the structured data and implement it with existing databases for analytics