
Suggested
An in-depth Guide to Automated Invoice Scanning Software
Automated Invoice Processing, a key back-office task that can lead to a great deal of time & cost savings if automated correctly.

Consider a scenario where you ask a search query—“Where was Albert Einstein born?”—using Google search. Figure 1 shows a screenshot of what we see before a list of search results.
To be able to show “Ulm, Germany” for this query, the search engine needs to decipher that Albert Einstein is a person before going on to look for a place of birth.

Deciphering Albert Einstein as a person from “Where was Albert Einstein born?” is a subdivision of IE called Named Entity Recognition (NER).
NER refers to the IE task of identifying the entities in a document. Entities are typically names of persons, locations, organizations, and other specialized strings, such as money expressions, dates, products, names/numbers of laws or articles, and so on. NER is an essential step in the pipeline of several NLP applications involving information extraction.
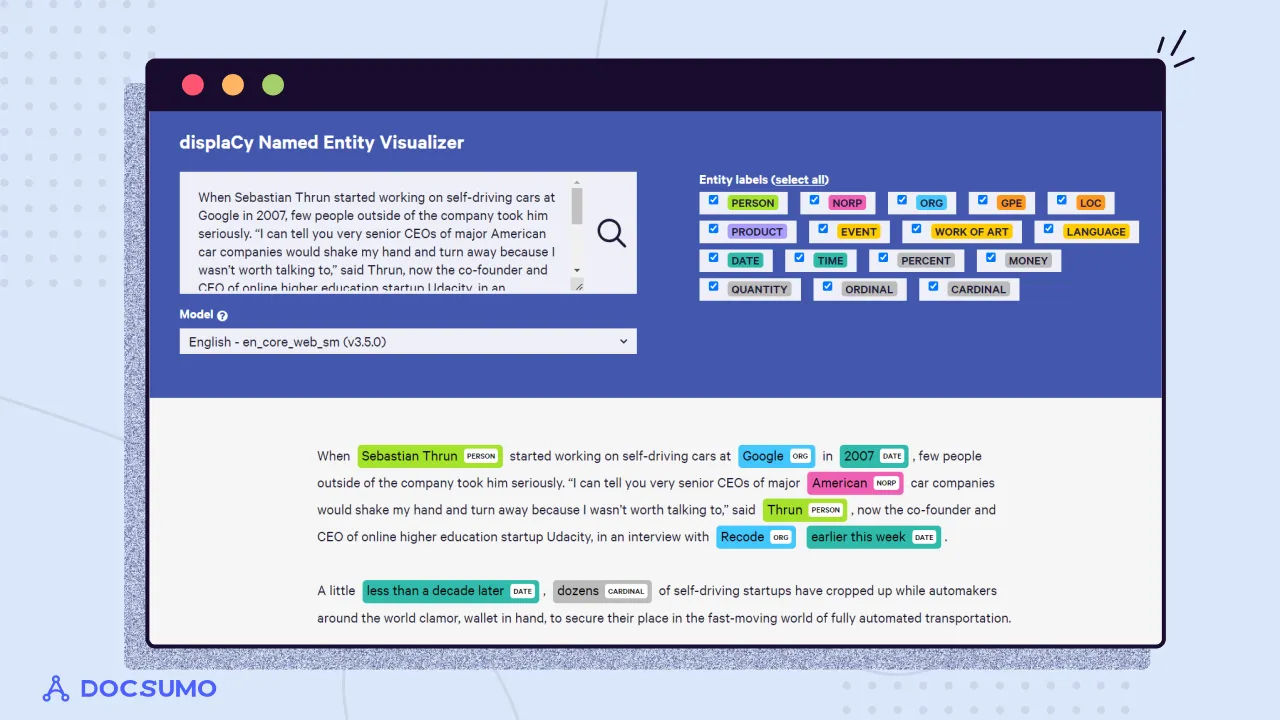
As seen in the figure, NER is expected to identify person names, locations, organizations, dates, and other entities for a given text. Different categories of entities identified here are some of the ones commonly used in NER system development. NER has several downstream utilities like relation extraction, event extraction, and machine translation (as names need not necessarily be translated while translating a sentence).
A simple approach to building a NER system is to maintain a large collection of person/organization/location names that are the most relevant to our company (e.g., names of all clients, cities in their addresses, etc.); this is typically referred to as a gazetteer. To check whether a given word is a named entity or not, just do a lookup in the gazetteer.
If a large number of entities present in our data are covered by a gazet‐ teer, then it’s a great way to start, especially when we don’t have an existing NER system available. A few questions to consider with such an approach:-
- How does it deal with new names?
- How do we periodically update this database?
- How does it keep track of aliases, i.e., different variations of a given name (e.g., USA, United States, etc.)?
You need a pattern-matching algorithm that can identify sequences of characters or words that match the pattern so you can “extract” them from a longer string of text. The naive way to build such a pattern-matching algorithm is in Python, with a sequence of if/then statements that look for that symbol (a word or character) at each position of a string.
For example, if you wanted to find some common greeting words, such as “Hi,” “Hello,” and “Yo,” at the beginning of a statement, you might do it as shown in the following listing.
Note: The GitHub repo for this article is Named-entity-recognition. You can try most of the code blocks by cloning the repo.
Listing 11.1. Pattern hardcoded in Python
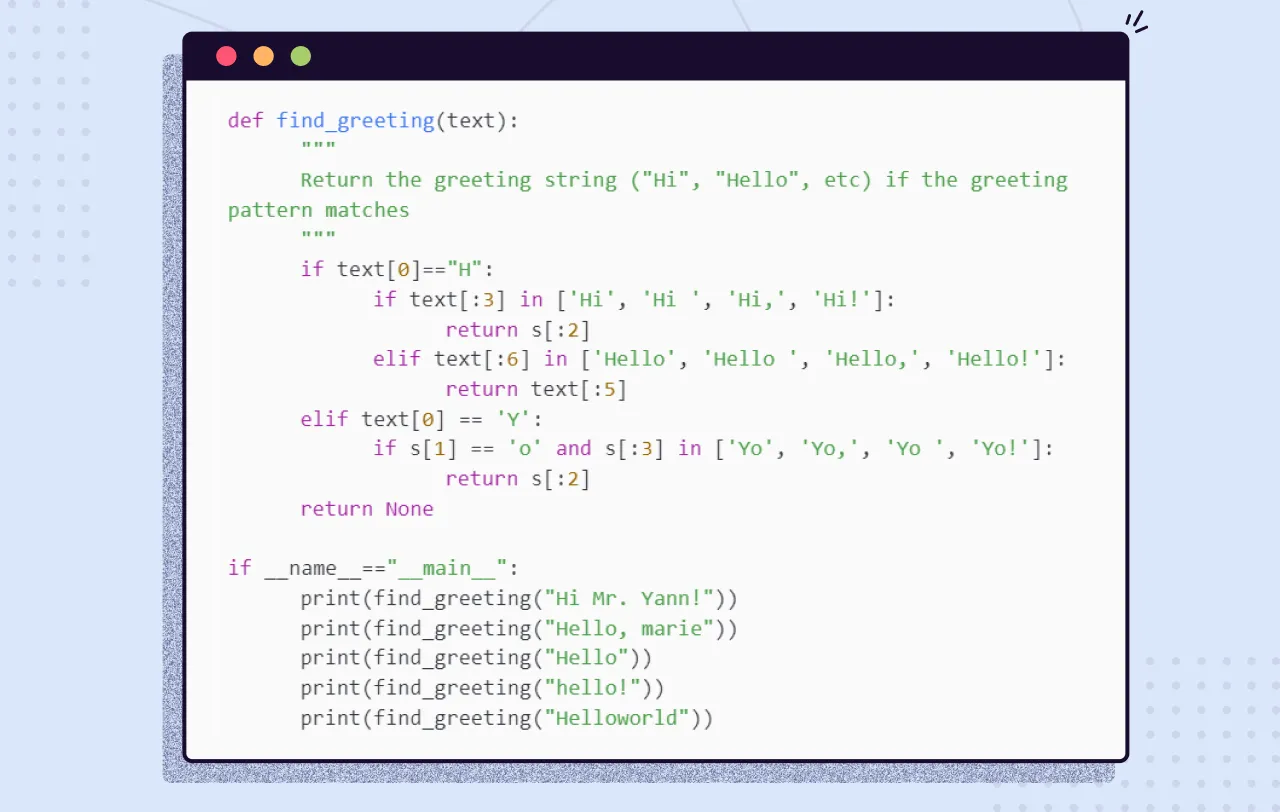
And the following listing shows the output:

You can probably see how tedious programming a pattern-matching algorithm this way would be. And it’s not even that good. It’s quite brittle, relying on precise spellings, capitalization, and character positions in a string. And it’s tricky to specify all the “delimiters,” such as punctuation, white space, or the beginnings and ends of strings (NULL characters) that are on either side of the words you’re looking for.
You could probably come up with a way to allow you to specify different words or strings you want to look for without hard-coding them into Python expressions like this. You could even specify the delimiters in a separate function. That would let you do some tokenization and iteration to find the occurrence of the words you’re looking for anywhere in a string. But that’s a lot of work.
Fortunately, that work has already been done!
A pattern-matching engine is integrated into most modern computer languages, including Python. It’s called regular expressions. Regular expressions and string interpolation formatting expressions (for example, " {:05d}".format(42)), are mini programming languages unto themselves. This language for pattern matching is called the regular expression language. Python has a regular expression interpreter (compiler and runner) in the standard library package re. Let's use them to define your patterns instead of deeply nested Python if statements.
Regular expressions are strings written in a special computer language that you can use to specify algorithms. Regular expressions are a lot more powerful, flexible, and concise than the equivalent Python you’d need to write to match patterns like this. So regular expressions are the pattern definition language of choice for many NLP problems involving pattern matching. This NLP application is an extension of its original use for compiling and interpreting formal languages (computer languages).
Let's find common greeting words using regular expressions.
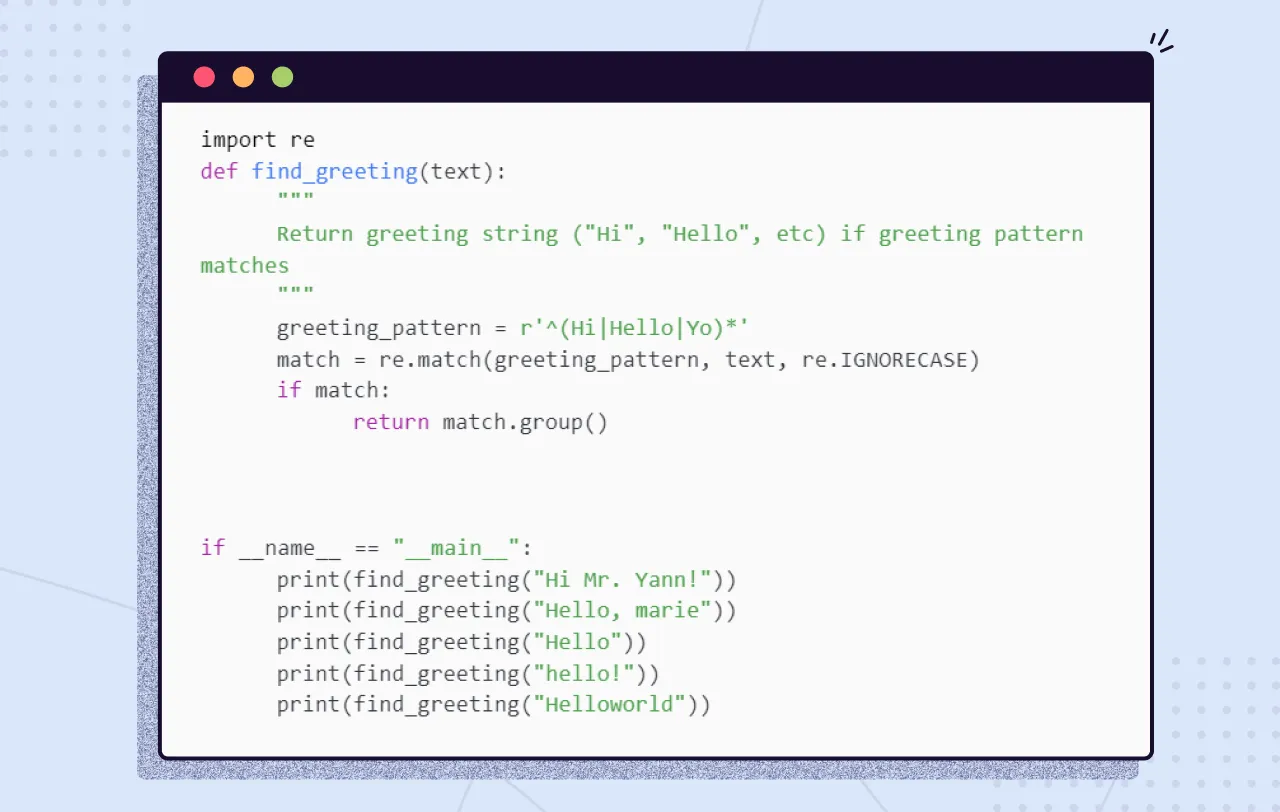
The following listing shows the output:

Pattern recognition is a strong way to find entities. It works great in input texts where the entities to extract are predefined ("Hi, Hello, etc". But we will soon realize its limitations when we try to extract entities like people's names, addresses, organizations, etc. The reason is that they can be any name, any address, or any organization.
An approach that goes beyond simple regular expressions is based on a compiled list of patterns based on word tokens and POS tags. For example, the pattern “NNP was born,” where “NNP” is the POS tag for a proper noun, indicates that the word that was tagged “NNP” refers to a person. Such rules can be programmed to cover as many cases as possible in order to build a rule-based NER system. Stanford NLP’s RegexNER and SpaCy’s EntityRuler provide functionalities to implement your own rule-based NER.
Let's write code for a simple spacy-based name extractor.
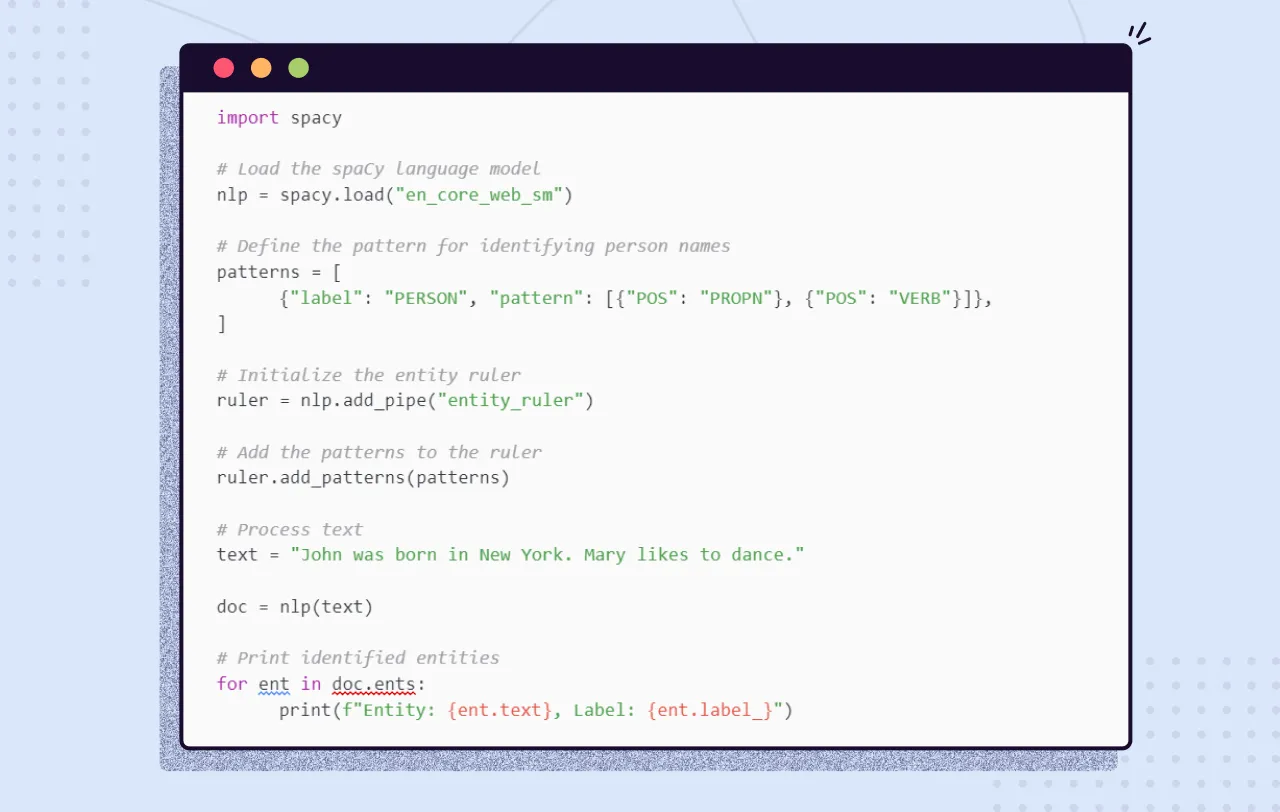
The following listing shows the output:
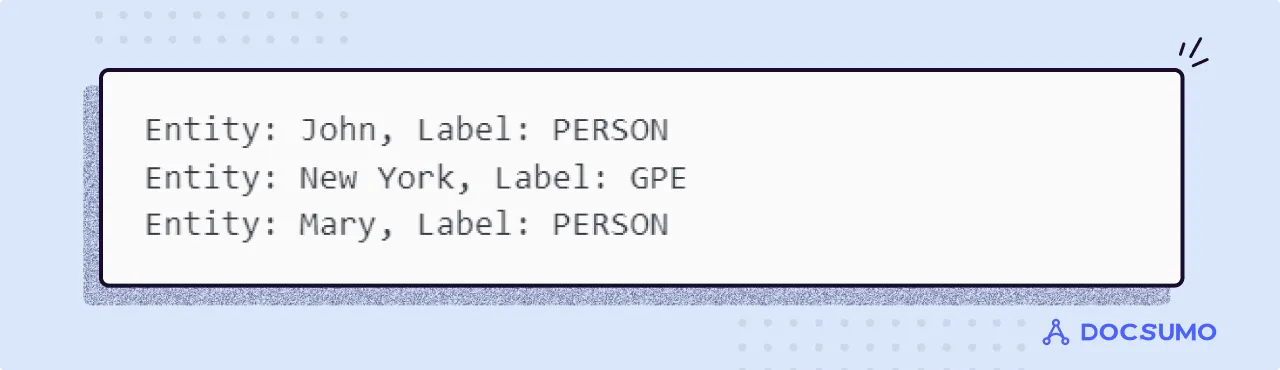
When it comes to Named Entity Recognition (NER), we enter the realm of machine learning, where the goal is to train models that can automatically identify and classify named entities within text. It's a bit like playing detective with words—for each word, we need to decide if it's a named entity and, if so, what kind of entity it represents. This task is commonly referred to as "sequence labeling."
To understand the concept of sequence labeling, let's draw a comparison with traditional text classification. In a typical text classification problem, like sentiment analysis for movie reviews, each sentence is treated independently. It doesn't matter what the previous or next sentence says; the classifier works its magic in isolation. However, NER is a different beast.
Imagine the sentence: "Washington is a rainy state." A regular classifier would look at the word "Washington" and might struggle to decide if it refers to a person (like George Washington) or the State of Washington. The context of the sentence matters here. To correctly classify "Washington" as a location, you need to consider the words around it.
This is where sequence classifiers shine. They take into account the words that precede and follow the current word. For instance, if the previous word indicates a person's name, there's a higher likelihood that the present word is also a person's name if it's a noun (e.g., a first or last name).
One of the popular methods for training sequence classifiers in NER is Conditional Random Fields (CRFs). CRFs are like the Sherlock Holmes of machine learning algorithms for NER—they're great at deducing the right labels by considering the surrounding evidence.
Please use this notebook in my Github repo (made for this article) to try training a CRF-based NER model yourself. We’ll use CONLL-03, a popular dataset used for training NER systems, and an open-source sequence labeling library called sklearn-crfsuite, along with a set of simple word- and POS tag-based features that provide the contextual information we need for this task.
To perform sequence classification, we need data in a format that allows us to model the context. Typical training data for NER looks like Figure 3, a sentence from the CONLL-03 dataset.

We will be following a typical process to train a sequence classification model:
1. Load the dataset
2. Extract the features
3. Train the classifier
4. Evaluate it on a test set
Loading the dataset is straightforward. I have added the preprocessed data in the GitHub repo. This particular dataset is also already split into a train/dev/test set. So, we’ll train the model using the training set and evaluate it on the test set.
Since this is a statistical machine learning model, we will be doing feature engineering.
What features seem intuitively relevant for this task? To identify names of people or places, for example, patterns such as whether the word starts with an uppercase character or whether it’s preceded or succeeded by a verb/ noun, etc., can be used as starting points to train a NER model. The following code snippet shows a function that extracts the previous and next words’ POS tags for a given sentence. The notebook has a more elaborate feature set:
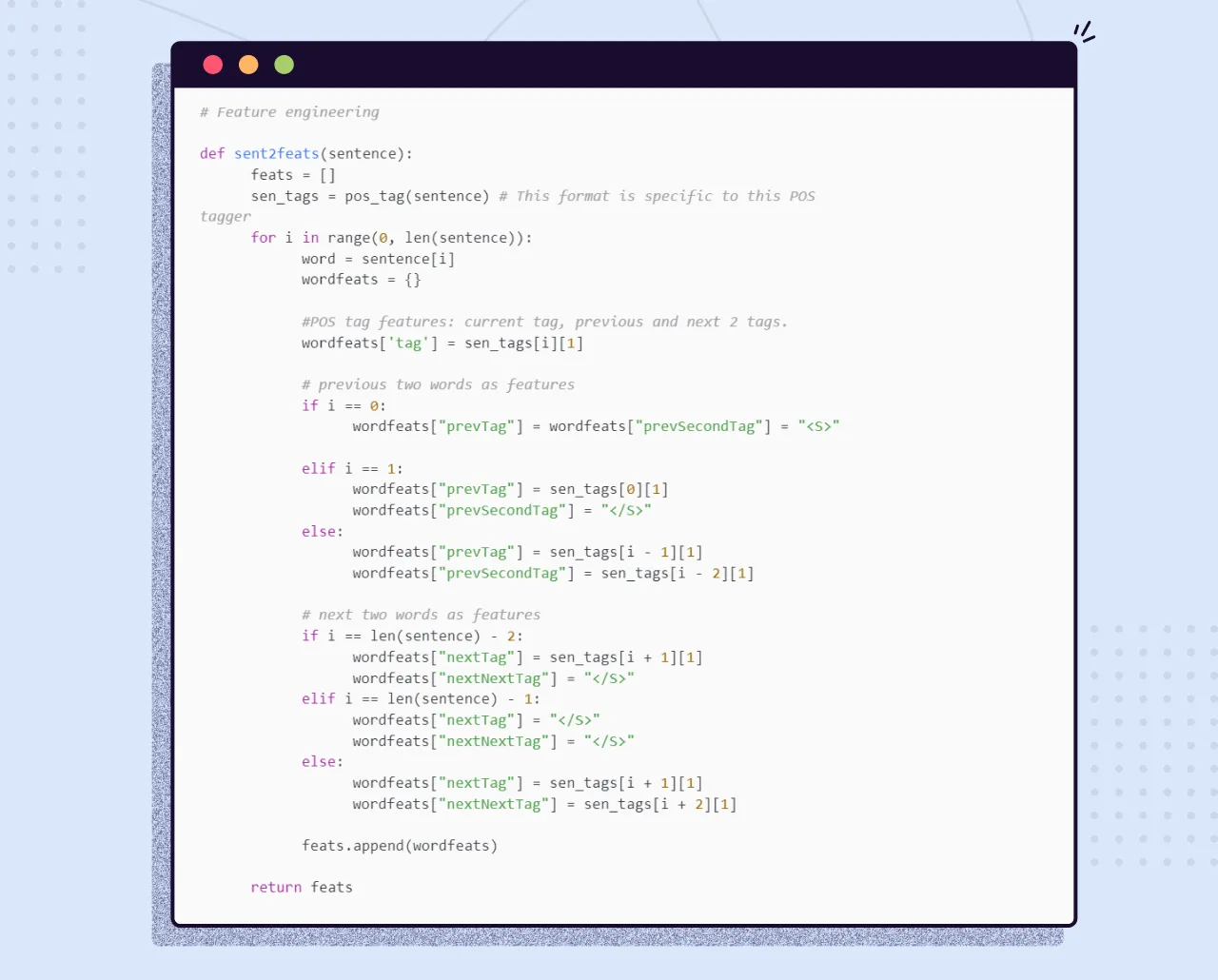
As you can see from the wordfeats variable in this code sample, each word is transformed into a dictionary of features, and therefore each sentence will look like a list of dictionaries (the variable feats in the code), which will be used by the CRF classifier.
The following code snippet shows a function to train an NER system with a CRF model and evaluates the model performance on the test set:
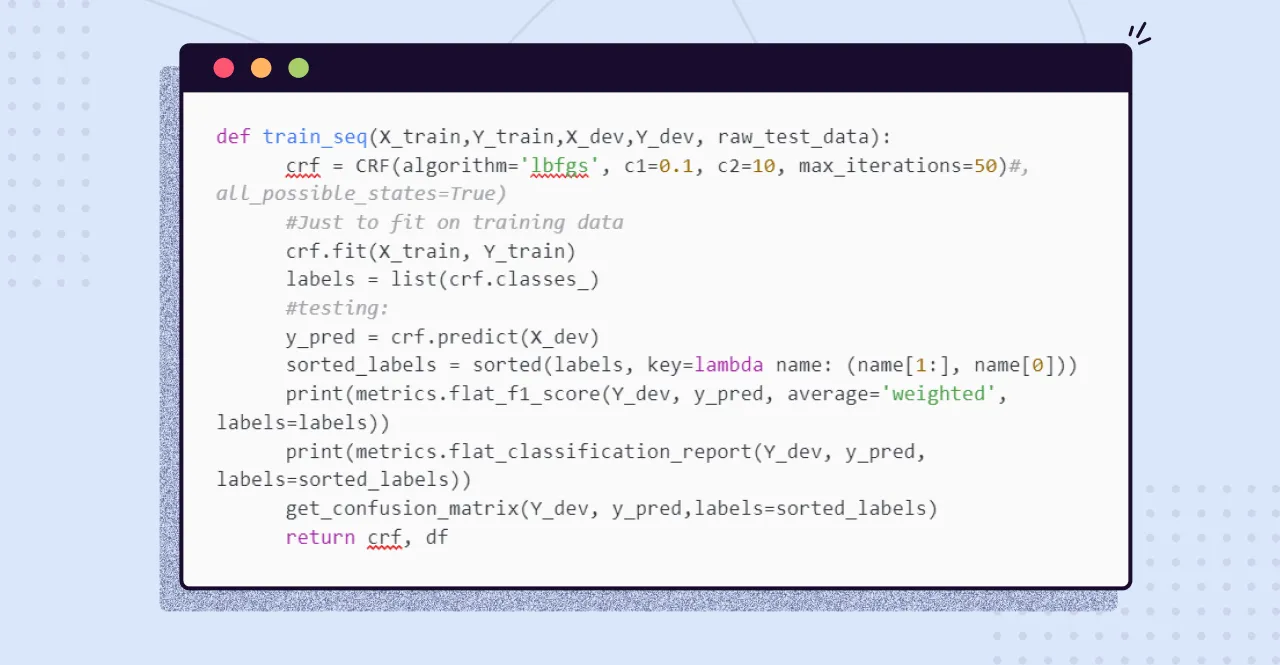
The model provides an F1 score of 0.93 on the test set. Below, I have attached the ground truth and predictions of some texts in the test set.
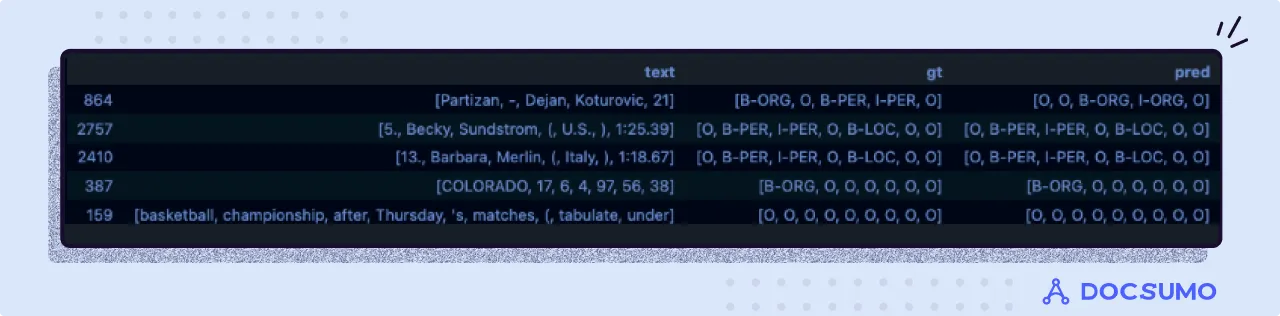
Not bad, huh, for a statistical model. Clearly, there’s a lot to be done in terms of tuning the model and developing (even) better features. Now, let's look at current SOTA deep learning models, where the model learns the features itself.
One of the main advantages of deep learning is its ability to learn word vectors, which provide contextual semantics. The better the contextual semantics, the better the language understanding, which leads to state-of-the-art results in entity extraction.
Often, the text sent to the model to extract entities is long. It may span multiple sentences or multiple pages. So, the ability to get accurate results also depends on the model’s ability to take into account the words that appear before and after the word that we are trying to find an entity for. A multilayered perceptron (MLP), as shown in the figure below, lacks this exact ability.
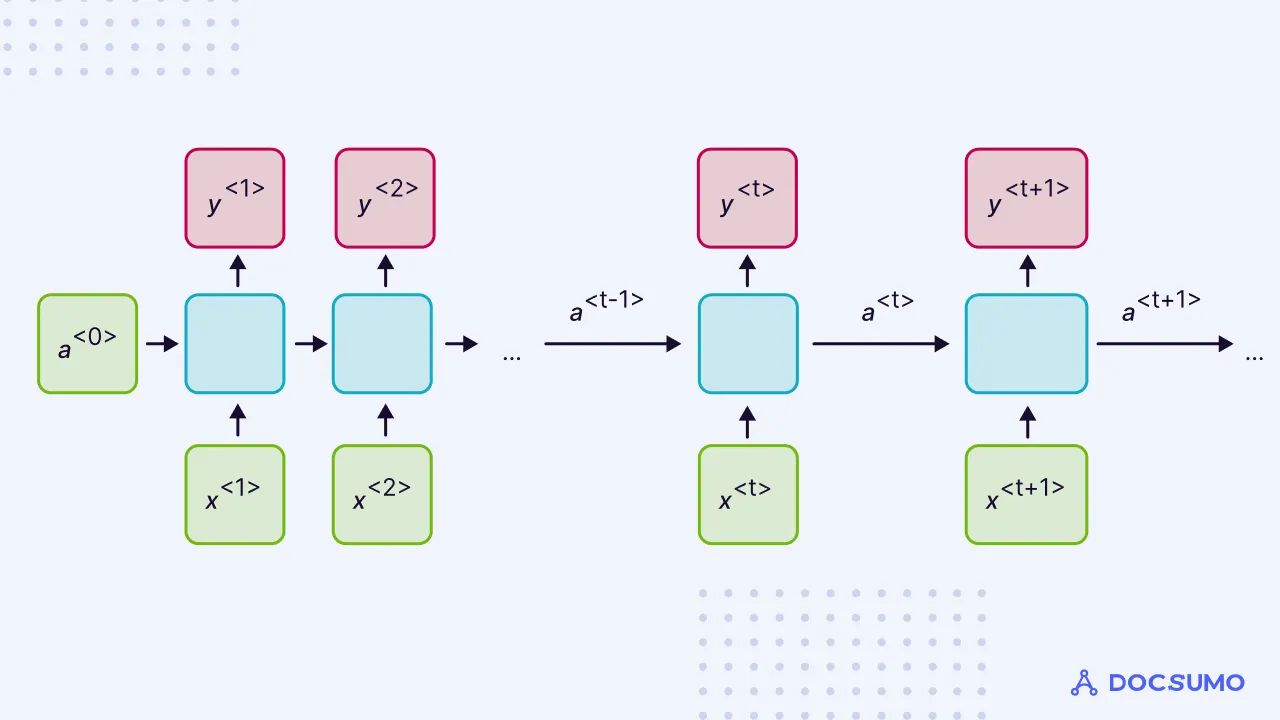
This is where Recurrent Neural Networks (RNNs) come into play. RNNs are designed to handle sequences of data and have a memory mechanism that allows them to consider the words that appear before and after the word being analyzed (a<0> as shown in the below image). However, RNNs face challenges known as vanishing and exploding gradients, especially when dealing with longer sequences. These issues hinder their ability to effectively capture contextual information over extended spans of text.
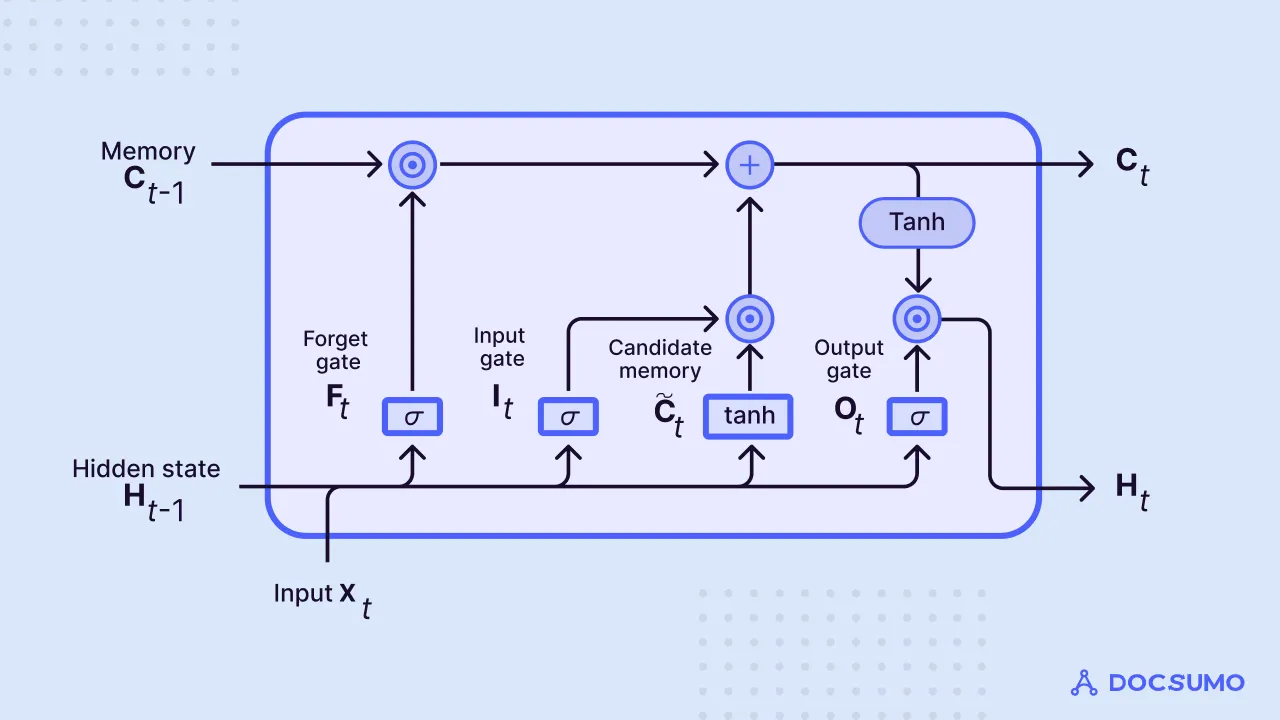
Long Short-Term Memory Networks, or LSTMs, address these gradient problems and have proven to be a game-changer in NER tasks. LSTMs are a type of RNN with a more sophisticated memory cell (C as shown in the below image), allowing them to capture long-range dependencies in text effectively. They are particularly well-suited for tasks where inputs span one or two sentences, making them a preferred choice for datasets like CONLL-03, which typically deal with sentences and short paragraphs.
While LSTM networks offer improvements, they still have limitations when it comes to handling extensive contextual semantics. LSTM networks can struggle with long-range dependencies and may not effectively capture the nuances of very lengthy text sequences.
Enter Transformers, a revolutionary architecture that has completely reshaped the landscape of Natural Language Processing (NLP). Transformers address the shortcomings of LSTM networks by introducing a novel attention mechanism that allows them to consider the entire context of a word, both preceding and following it (Encoders), simultaneously. A lot of NER use cases include input text that spans multiple paragraphs to pages. The transformer is perfect for that.
Now let's fine-tune BERT, a pretrained encoder architecture, on the CONLL-2003 dataset. We will observe how well this performs in comparison to CRF.
To load the CONLL-2003 dataset, we use the load_dataset method from the Datasets library:
from datasets import load_dataset
raw_datasets = load_dataset('conll2003')
This will download and cache the dataset. Inspecting the object shows us the columns present and the split between training, validation, and test sets:
DatasetDict({
train: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 14041
})
validation: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3250
})
test: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3453
})
})
In particular, we can see that the dataset contains labels for the three tasks we mentioned earlier: NER, POS, and chunking. We are focused on NER only for now.
Let's look at the results after you have finished fine-tuning:

Nice. These are great scores on the test/hold-out set
If your use case is basic, you can use pretrained models like the Spacy NER model and NLTK NER model. If they don’t work well on your dataset or provide low accuracy, then you will have to either write rules or train a deep learning or machine learning model. But today, with the advancement of generative AI, you have some other options. The most basic one is prompting.
Let’s look at an example of how you can get started.
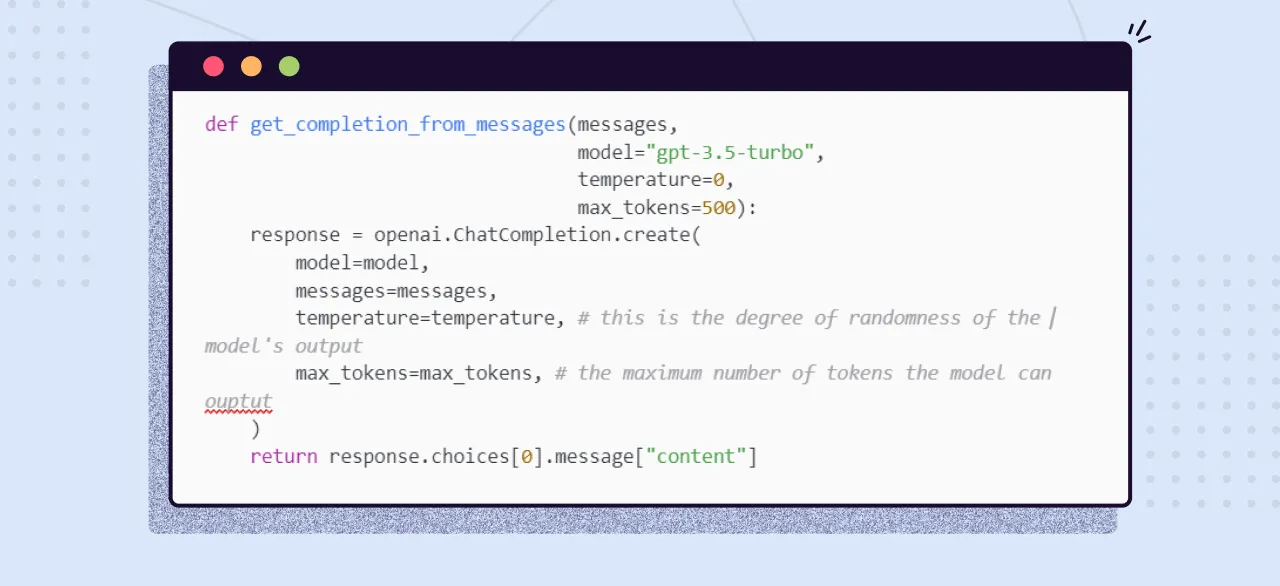
Remember, writing great prompts is an iterative task. You need to playground with it for a while
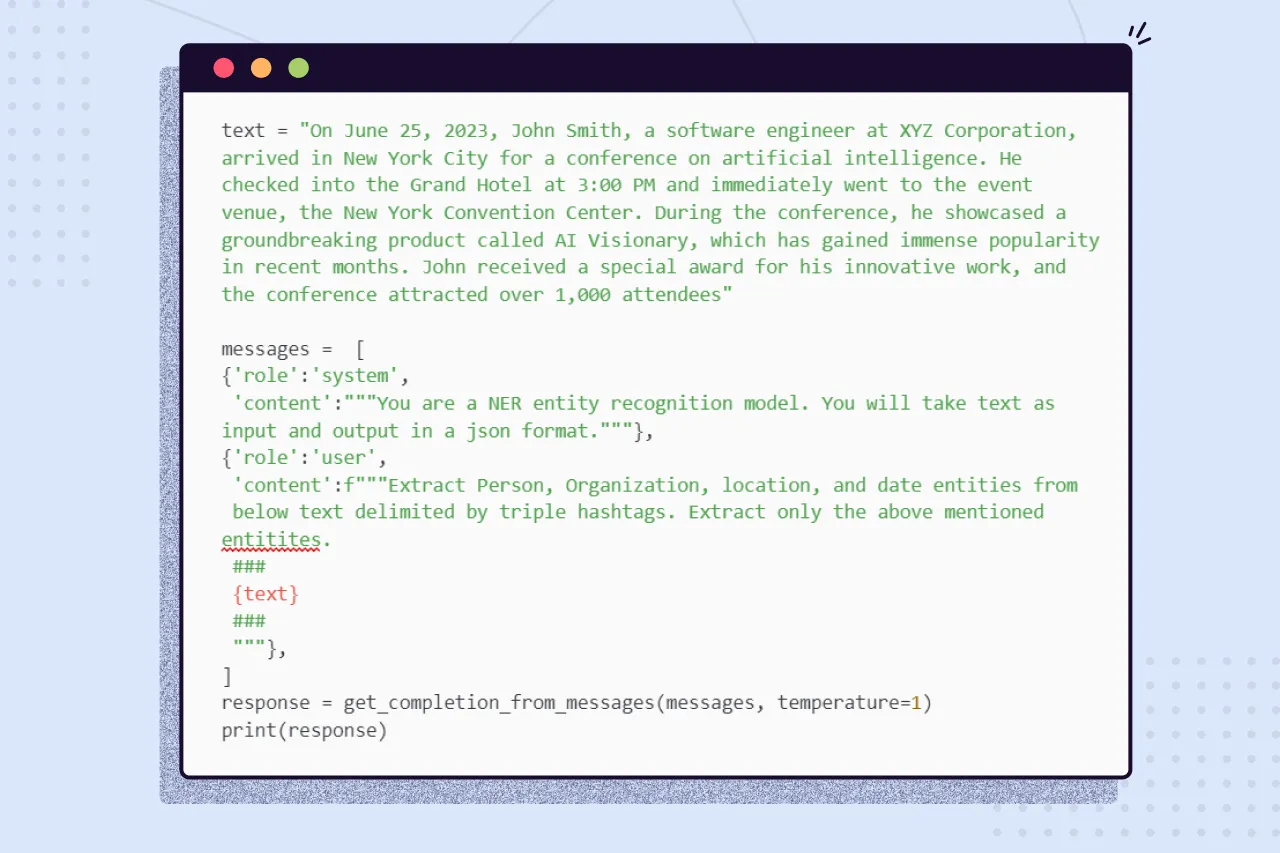
Output:

Not too bad. There are a lot of improvements we can make in terms of prompt to get better results, like defining the JSON structure to get uniform results every time, better prompt, better handling of edge cases, and so on. As I mentioned, it is an iterative process.
In my view, utilizing writing prompts is more likely to yield significantly higher accuracy compared to investing time in crafting intricate rules. Furthermore, the development cycle for employing prompts is notably shorter than the process of constructing a Machine Learning or Deep Learning model.
The above code example uses what's called "zero-shot prompting," which means no reference examples are given. If you want better results, you can switch to "few-shot prompting." If you find that you need even more accurate results, you can fine-tune models like BERT or Roberta using your own data. Importantly, you don't have to fine-tune massive models like GPT-3 for NER tasks, as they have many more parameters than needed for this specific task.
In conclusion, this journey through Named Entity Recognition (NER) has taken us from its fundamental building blocks, including Gazetteers, regular patterns, regular expressions, and rule-based NER, to the more advanced realms of machine learning-based NER. We delved into the power of deep learning, exploring techniques such as MLPs, RNNs, LSTMs, and transformer models like BERT, highlighting state-of-the-art innovations in the field.
Additionally, we unveiled the potential of generative AI for entity extraction, showcasing its adaptability to specialized use cases. NER continues to evolve, bridging the gap between language understanding and real-world applications and offering exciting possibilities for information extraction and analysis in various domains. With these insights, we've covered a comprehensive overview of the dynamic landscape of NER developments.
We deal with a lot of textual content daily, be it DMs, daily emails, or blogs (articles) we read for fun or at work (reports, bills, etc.) or to catch up on current affairs (news). Such text documents are a rich source of information for us. In various contexts, the term 'information' can encompass a wide range of elements, such as key events, people, or relationships between people, places, or organizations, etc. Information extraction (IE) is a field of NLP focused on the task of extracting relevant information from text documents.
