Suggested
8 Best Automated Data Entry Software: Features, Pricing, and Review
In this blog, learn how top automated data entry software can streamline your workflows, improve data quality and business processes.


Data is a business's most valuable asset. Managing it efficiently is crucial to staying competitive in the market. Today, one of the main bottlenecks of any data capture system is the management of manual data entry. Automated data entry software, in particular, has become the perfect tool.
It helps you with automated data processing, saving your company precious time and money. This blog explores the top 8 automated data entry software solutions of 2025, providing insights into their features, benefits, limitations, and everything you need to know about automated data entry software.
Let’s start by understanding what data entry software is.
Data entry software is a digital tool designed to automate the process of capturing, processing, and storing information. It completes the entire process from various sources, such as forms, documents, and databases.
It uses technologies like Optical Character Recognition (OCR), Artificial Intelligence (AI), and Machine Learning (ML) to extract data from structured formats like spreadsheets and unstructured formats like scanned images or handwritten forms.
By automating these tasks, data entry software reduces manual effort, minimizes errors, and ensures the information is accurately stored in a centralized database or system for easy access and integration.
For example, these tools can read text from images via OCR, use AI to interpret the data and automate interaction to simplify it.
To understand the value of data entry software, let's first examine the challenges associated with traditional manual data entry methods.

An average typist types at the speed of 70 WPM (words per minute), and many invoices issued to businesses are done on paper. Tax receipts, building documents, accounts payables, and sales documents are forwarded to the accounts for document processing.
Many businesses do not use automated processing and hire employees to convert these data into electronic formats. There are also standards to be followed, which can vary from country to country, such as the European VAT Invoicing Regulations.
However, manual data entry presents its own set of challenges. Below is a list of how the costs add up for businesses by manually entering data:
A human being can manually enter data at a consistent speed for so long. It’s impossible to perform at peak productivity round the clock or maintain the average keystroke per hour without taking breaks. Employees are prone to fatigue, and when you add in sick leaves or days, there are delays in document processing.
Employees are paid by the hour for doing manual data entry tasks in organizations. However, the hours add up, and in the long run, it becomes expensive for businesses to maintain their upkeep.
Nobody likes to revisit forms and redo their data entry work. But with manual data entry this is a reality as employees aren’t perfect at entering data. There is an element of human error, and no matter how well-trained employees are, they make mistakes. Furthermore, if details in documents get updated and they’re notified later, they have to re-enter the data and start over
Assigning blank values, missing fields, discrepancies in data output, etc., all lead to delayed turnaround time. This leads to hidden charges, and sometimes, employees don’t know how to verify the accuracy of the information being entered. Businesses can lose up to 18 million EUR a year due to mistakes made by employees in organizations, and that’s a big number!
To fully appreciate the benefits of automation, it's crucial to compare and contrast the key differences between manual and automated data entry methods. Let’s understand the differences in the next section of the blog.
Manual data entry is used for all kinds of paper-based documents, while automated data entry adds flexibility since the technology is capable of reading a variety of data formats. Mistakes inevitably happen due to the monotonous nature of manual data entry work, while automated data entry makes it easy to read or organize information.
Here are the primary differences between manual and automated data entry.
Building upon the advantages of automated data entry, let's explore how leveraging Machine Learning (ML) can further revolutionize data entry processes and drive significant business growth.
Organizations can reap enormous benefits in the following areas by leveraging ML-based data entry automation.
Data entry automation tools incorporating ML algorithms help organizations analyze data for decision-making. Data is critical to business success because within these large and complex datasets lie the answer to emerging trends and investment opportunities in the market. Harnessing this data helps assess risks better and avoid overestimations. ML-based data entry tools capture and process large amounts of data significantly faster and more accurately.
Quality data is a critical component of predictive analytics. ML-based data entry improves data quality by reducing errors, filling in missing data points, and providing accurate datasets. It analyzes past data to provide accurate predictions and runs multiple what-if scenarios to design financial revenue models and improve growth.
ML-based tools enable faster and more efficient fraud detection. Banks are keen on detecting potential fraudsters based on their transaction data. For that, the bank needs to automatically extract data from various sources, such as bank statements, checks, and financial statements, and classify them. By processing the data and classifying transactions, they can use insights gained from the analysis to prevent possible fraud.
According to an E&Y report, Risk management is the domain with the highest AI implementation rates (56%). ML algorithms are sought after because they can improve mitigation by analyzing large amounts of information and making predictions based on historical data. For example, it considers attributes such as credit history and loan repayment patterns to predict the likelihood of default or late payments.
During an SEC (Securities and Exchange Commission) investigation in 2021, leading financial services company JP Morgan failed to produce adequate written communication about business transactions and security matters.
The SEC penalized the firm with a whopping 125 million dollars for failing to implement compliance controls. Due to inadequate record-keeping, the employees could not access relevant information on time and could not comply with the investigations relating to a potential violation of federal security laws.
The cost of ineffective compliance is hefty, especially if there are inadequate records and data discrepancies relating to financial transactions. ML-based data entry creates a detailed audit trail documenting all data entry and processing activities. It extracts, classifies, and stores them in a centralized system you can access whenever needed. It further helps you demonstrate compliance with regulatory requirements and provide evidence in case of audits or investigations.
ML-based tools help reduce labor costs, improve accuracy, and free up your resources to focus on more strategic tasks. They are also more flexible. You can scale them as your data increases and becomes more complex.
To fully understand the implementation and impact of ML-based data entry, let's examine the typical lifecycle involved in this transformative process.
Imagine a healthcare company that needs to record critical information such as patient demographics, diagnoses, lab tests, and medications. Extracting and processing this information from various documents is error-prone and time-consuming.
Let us examine how an ML-based document data entry tool automatically organizes and cleans raw data, transforms it into a machine-readable form, trains a model, and helps the healthcare firm generate real-time predictions.
Healthcare information such as claims data, medical imaging data, electronic health records, genomic data, etc., are sourced from disparate systems. Thus, they tend to be messy and complex. You can clean and transform data into a format easily recognized and processed by machine algorithms through preprocessing.
It ensures cohesion of entry types, making them suitable for a machine learning model while increasing the accuracy and efficiency of the model.
(i) Data Cleaning
This technique involves removing or handling missing or erroneous data, such as duplicates, missing values, or outliers. For instance, in a diabetes diagnosis dataset of 1000 patients, you can impute the missing values for the BMIs of 20 patients with the mean or median of the corresponding feature.
(ii) Normalization or standardization
It involves scaling data such as age and glucose levels. The former (age) has values ranging from 20 to 80, and the latter (glucose levels) ranges from 60 to 40. Through standard normalization techniques such as min-max scaling, z-score normalization, or log-transformations, you can scale the features to a range of 0 to 1.
(iii) Data Labeling
In this stage, you assign predefined labels or categories to a data set. These labels are used to train an ML model to recognize patterns and make predictions based on new or unseen data. For example, you are assigning a label (i.e., "diabetic" or "non-diabetic") to each patient's data record in the dataset, with "1" typically indicating a diabetic patient and "0" indicating a non-diabetic patient.
(iv) Feature Engineering
It involves selecting, extracting, and transforming relevant features from the data to enhance the accuracy and performance of the model. For example, age, BMI, blood pressure, glucose, and cholesterol levels are the most suitable features for diabetes diagnosis.
This stage aims to select a machine learning algorithm that performs well against various parameters. In the context of diabetes diagnosis, you can train ML models on a labeled dataset containing features such as blood glucose levels, BMI, blood pressure, insulin levels, and diabetes pedigree function.
These models evaluate the relationship between these features and the expected outcome. Later, they are given a fresh set of unseen data, and the best-performing model is selected for further training.
Training involves using the algorithm to learn patterns or relationships in the data by adjusting its parameters until it achieves the best possible performance on a training set.
(i) Ensemble methods
Ensemble methods combine multiple models to improve the overall performance. You can use techniques such as bagging, boosting, and stacking, including Random Forest, a popular ensemble learning method that combines multiple decision trees for accurate and stable prediction.
(ii) Deep learning
Deep learning algorithms typically involve multiple layers of neural networks, which enable the model to identify complex patterns and relationships in data. These models are used for various applications, including computer vision, natural language processing (NLP), speech recognition, and decision-making.
One example of deep learning in diabetes diagnosis is using convolutional neural networks (CNNs) to analyze retinal images and detect diabetic retinopathy (DR), a common complication of diabetes that can lead to vision loss.
Every algorithm requires input parameters from observed data. However, Hyperparameters are the parameters of a machine learning model that are not learned from the data during training but rather set before training.
These parameters control various aspects of the learning process, such as the complexity of the model, the learning rate, regularization, and so on.
The values of hyperparameters significantly impact the performance of a machine learning model, and hyperparameter tuning is the process of selecting the optimal values for these parameters.
Once you identify optimal hyperparameters, you can train the deep learning model on the entire dataset to obtain the final model. In deep learning, hyperparameters include settings such as learning rate, batch size, number of epochs, dropout rate, and regularization strength.
For a diabetes test, these settings are tuned for various ML-based models, such as a medical image for retinal imaging or blood glucose monitoring via EHR. Doing this can improve the model's accuracy in predicting patient outcomes and identifying potential health risks.
(i) Grid Search
Grid search is a technique to tune the hyperparameters of a model by testing a range of parameter values and selecting the combination that yields the best performance. It is ideal for a small number of hyperparameters or when you know which hyperparameter values are likely to perform well.
(ii) Random Search
On the other hand, random search samples hyperparameter values from a defined search space. It only covers some possible combinations of hyperparameters, but it can be more efficient when the search space is enormous.
(iii) Bayesian Optimization
This technique uses a probabilistic model to guide the search for optimal hyperparameters. In Bayesian optimization, we begin with a prior belief about the distribution of possible hyperparameters, often based on past experiments. It uses the results of previous evaluations to guide the search toward regions of the search space that are more likely to contain good hyperparameters. It is ideal for complex and high-dimensional search spaces like healthcare data sets.
Now that you have trained your model, assessing its precision is crucial. Model evaluation is the stage where you split the data into a training set and a test set for testing purposes.
Once you are done evaluating, only then can it be deployed into production. Deployment involves integrating the trained model into a larger system, such as a web or mobile application or your CRM.
(i) Cross-validation
Cross-validation is a powerful technique commonly used in healthcare. It involves training several machine learning models on subsets of the available input data and testing them on the complementary subset of the data.
(ii) Confusion matrix
It helps with evaluating the performance of a classification model. The confusion matrix is a table that shows the number of true positives, true negatives, false positives, and false negatives in the predictions made by a classification model. You can calculate various metrics such as accuracy, precision, and recall from these results.
(iii) Sensitivity analysis
This technique evaluates a model's sensitivity to changes in input parameters. In the context of diabetes diagnosis, it shows whether the model's predictions change when you vary the threshold for defining features such as high glucose levels, blood pressure, BMI, etc.
Python Libraries for Model Evaluation
Now that we understand the lifecycle of ML-based data entry let's explore the key benefits that automated data entry solutions, particularly those powered by ML, can deliver to businesses.
In a world where data is king, enterprises and organizations around the world are increasingly relying on automated data entry solutions. Schools, universities, banks, and hospitals process a massive number of documents on a yearly basis and simply don’t have the time to go through huge volumes manually.
Migrating to automated data entry solutions gives these organizations a stable footing and helps make the job of data entry and document management much easier.
Here are the top benefits of using automated data entry solutions for all users-
There is no need to host physical spaces for storing documents when companies switch to automated data entry solutions. Intelligent OCR data entry tools make it easy for organizations to sort and save their documents online. All this data is not lost due to proper file backups, and these files can be easily shared with others
Data capture solutions use intelligent machine learning algorithms to read and process documents. There are no human errors since these models use past data to fact-check and verify sources of information.
Clients are turning to businesses that use automated data capture and entry solutions because of the credibility of software. Intelligent document processing solutions like Docsumo are compliant with legal, and regulatory standards and trusted by clients worldwide.
Automated data entry takes a simple drag-and-drop approach where users upload a variety of documents and let APIs do their job. Users don’t have to worry about what category their documents belong to since the algorithms take care of it. They can feed APIs data entry examples for reference and the software is able to learn from sample structures.
When businesses remove manual labor and focus on more productive tasks, they automatically save money. It takes hours to scour through billions of documents and organize data according to different types. Automated data extraction and entry solutions speed up the document processing workflow, thus helping businesses focus on what matters most to them.
With a clear understanding of the benefits, the next crucial step is to determine the most suitable data entry software for your specific needs.
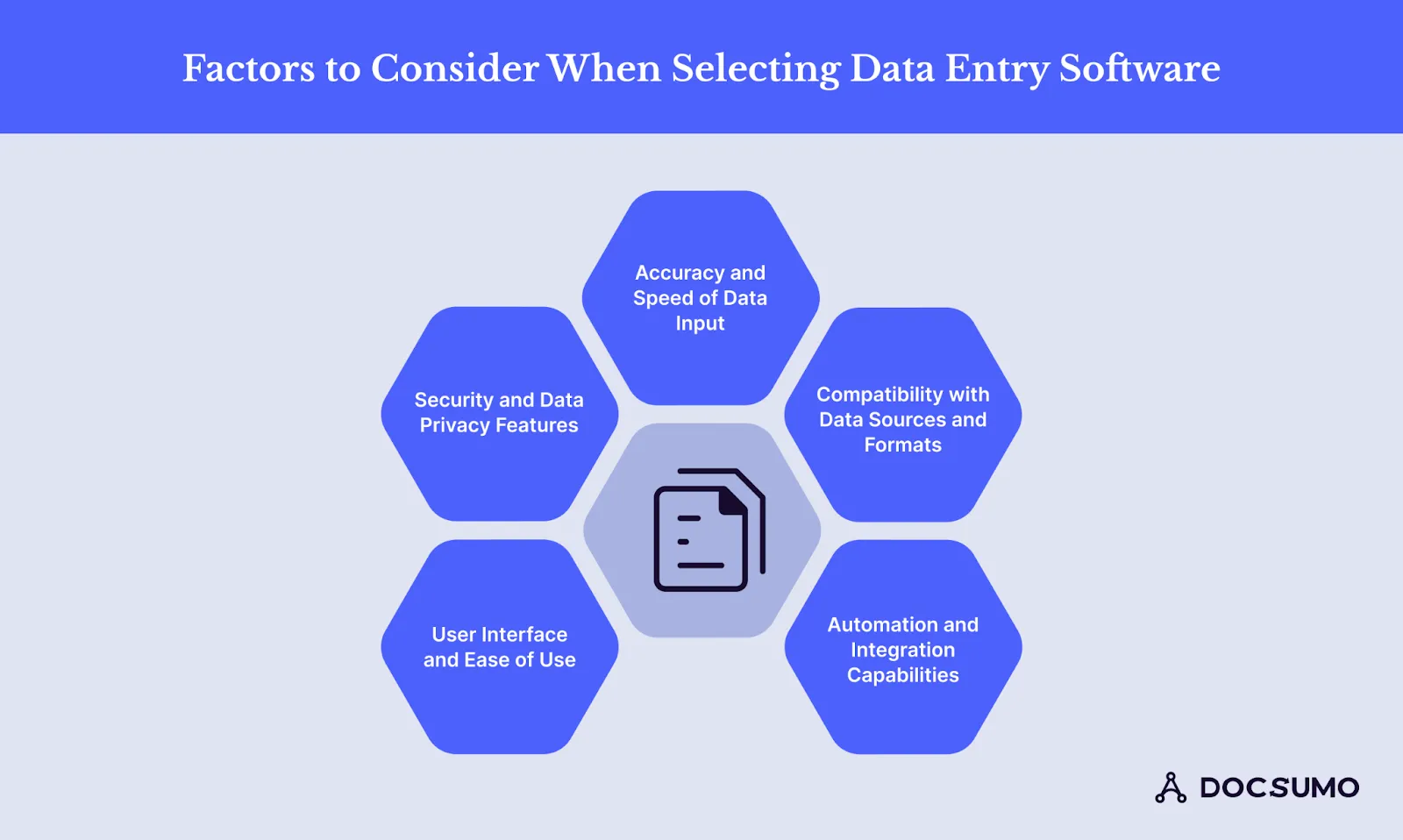
Choosing the right data entry software for your business involves evaluating several vital factors. Here are some critical considerations:
One of the most critical aspects of choosing data entry software is its precision and speed. It must employ integrated technologies such as OCR and AI to extract data accurately.
Furthermore, its speed should handle a large volume of data within a concise time frame. Thus, businesses can save costs and time and enhance their productivity and scope.
Compatibility with data sources and formats is another important factor. The chosen software must integrate with your existing data sources, such as documents, spreadsheets, databases, or APIs. It should also support a range of formats, including CSV, Excel, and PDF.
Data entry software should have strong automation and integration capabilities. Automation reduces the need for manual effort by managing repetitive tasks and simplifying manual data collection across multiple online sources.
Regarding integration, look for software that works well with commonly used business applications and systems.
The software should offer an intuitive design, simple navigation, and easily accessible support resources. The associated training and onboarding process should be as streamlined and explicitly accessible as possible to help minimize and offset the associated downtimes and enhance the adoption process.
User-friendly software can lead to a more positive user experience and boost productivity.
Ensure the data entry software has comprehensive security measures, where the information stored and shared is encrypted. Also, ensure your software provider has a strong record of keeping up with industry standards.
This includes regulations (like GDPR or HIPAA) and security best practices.
Now that we know what to look for let's examine some of the leading data entry software options that are highly regarded in the industry.
Docsumo is AI data entry automation software designed to process information from invoices, receipts, GST bills, medical records, and other forms. Docsumo extracts data from documents with increased accuracy using OCR and ML technology.
Docsumo offers flexible pricing plans to cater to various business sizes and requirements.
Amazon Relational Database Service (RDS) is a cloud-based database service provided by Amazon Web Services (AWS). It helps set up, operate, and scale relational databases in the cloud, automating tasks like hardware provisioning, database configuration, software patching, and backups.
Amazon RDS pricing varies based on several factors, including the database engine, instance type, storage, and data transfer. Some key pricing components include:
Backup Storage: Free up to the total size of all databases for a region, with additional storage costs.
JotForm is an easy-to-use online form builder that lets you create and manage custom forms for data collection and entry. Its drag-and-drop interface means you don't need any coding skills, making it perfect for businesses, schools, and non-profits.
JotForm offers a freemium model with various pricing tiers:

Microsoft Power Automate, formerly called Microsoft Flow, is a cloud service that lets you automate workflows between different apps and services. It helps you streamline tasks and processes by connecting various systems, boosting efficiency and productivity for both personal and business use.
Microsoft Power Automate offers several pricing tiers to suit different needs:

Formstack is an easy-to-use tool for building and managing forms, surveys, and data collection. It helps you create customized forms, automate data collection, and integrate with various apps to make workflows smoother and improve data management.
Formstack offers various pricing plans:

Zoho Forms is an easy-to-use online form builder that helps you create and manage forms and surveys.
It offers a complete platform for collecting data, seamlessly integrating with other Zoho apps and external services to streamline workflows and improve data management.
Zoho Forms offers various pricing plans to suit different needs:

Talend is a top-notch platform for data integration and quality management designed to make handling, transforming, and analyzing data from various sources easier. It offers a full suite of tools for data integration, quality, and governance, helping businesses keep their data accurate and accessible for better decision-making.
Talend offers various pricing options to fit different needs:

WinAutomation is a desktop automation tool designed to make repetitive tasks easier and boost productivity by automating routine operations. It helps users automate data entry, file management, and other everyday tasks, streamlining workflows and reducing manual work.

Here are some reasons why you should integrate data entry solutions:
Deciding on the best automated data entry software is very important, irrespective of the size of your organization. The choice of automated data processing must not be random, but it should depend on what need the software must meet.
From advanced OCR and AI capabilities to scalable solutions and seamless integrations, this data automation software can significantly streamline data entry processes, reduce manual errors, and drive cost savings.
As businesses embrace automation, investing in the right data entry software will improve operational efficiency and support informed decision-making and growth. Go through this table and decide for yourself why Docsumo stands ahead of its competitors.
Sign up to see how Docsumo can help you enhance the data extraction process.
Automated data entry software is designed to streamline the process of inputting large volumes of data accurately and efficiently. It minimizes human error and significantly reduces the time spent on manual data entry tasks.
Yes, most data entry software can integrate with various data sources such as PDFs, spreadsheets, databases, and APIs. This versatility allows for seamless data management across different platforms.
Data entry software typically includes encryption, access controls, and compliance with data privacy regulations to protect sensitive information. Features like audit trails and user authentication ensure data integrity and security.
Consider the software's ease of use, intuitive navigation, and available support resources. An effective user interface can significantly reduce the learning curve and improve user productivity.
Integration with other business applications allows for seamless data flow, reducing the need for manual data transfers and improving overall efficiency. It ensures data consistency and enhances the accuracy of business processes.
