Oops! Something went wrong while submitting the form.
Optical Character Recognition (OCR) is a technology used to convert an image of text into machine-readable text. The OCR engine or OCR software works by using the following steps:
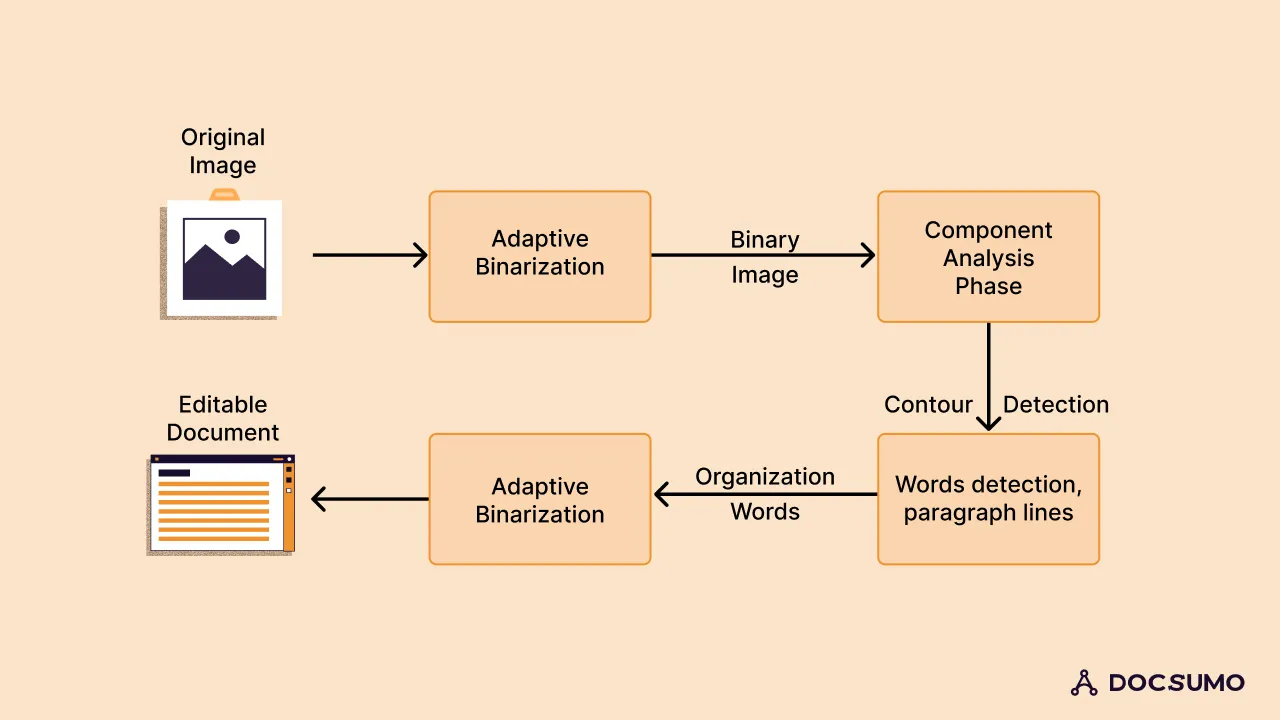
Preprocessing of the Image
Text Localization
Character Segmentation
Character Recognition
Post Processing
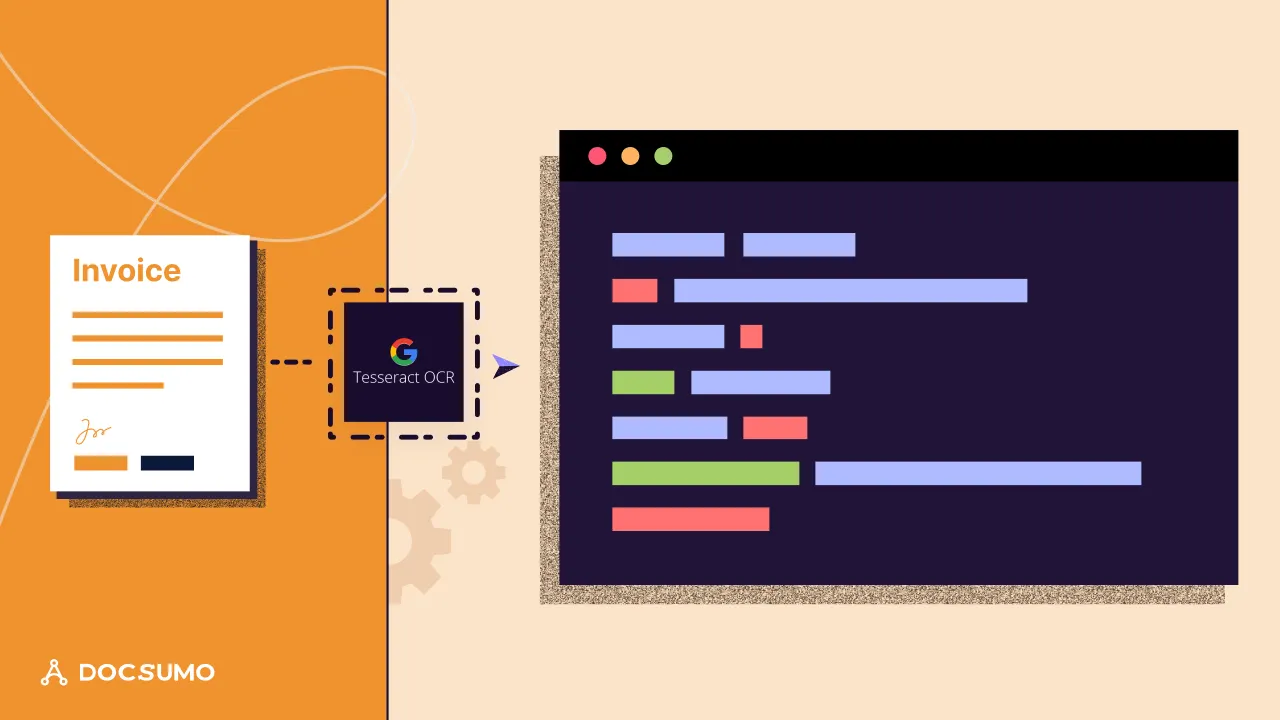
Extracting text from images or scanned documents is a fundamental requirement for various industries and applications. Whether it's converting scanned materials into editable formats, extracting data for analysis, or automating information retrieval, Optical Character Recognition (OCR) technology plays a pivotal role.
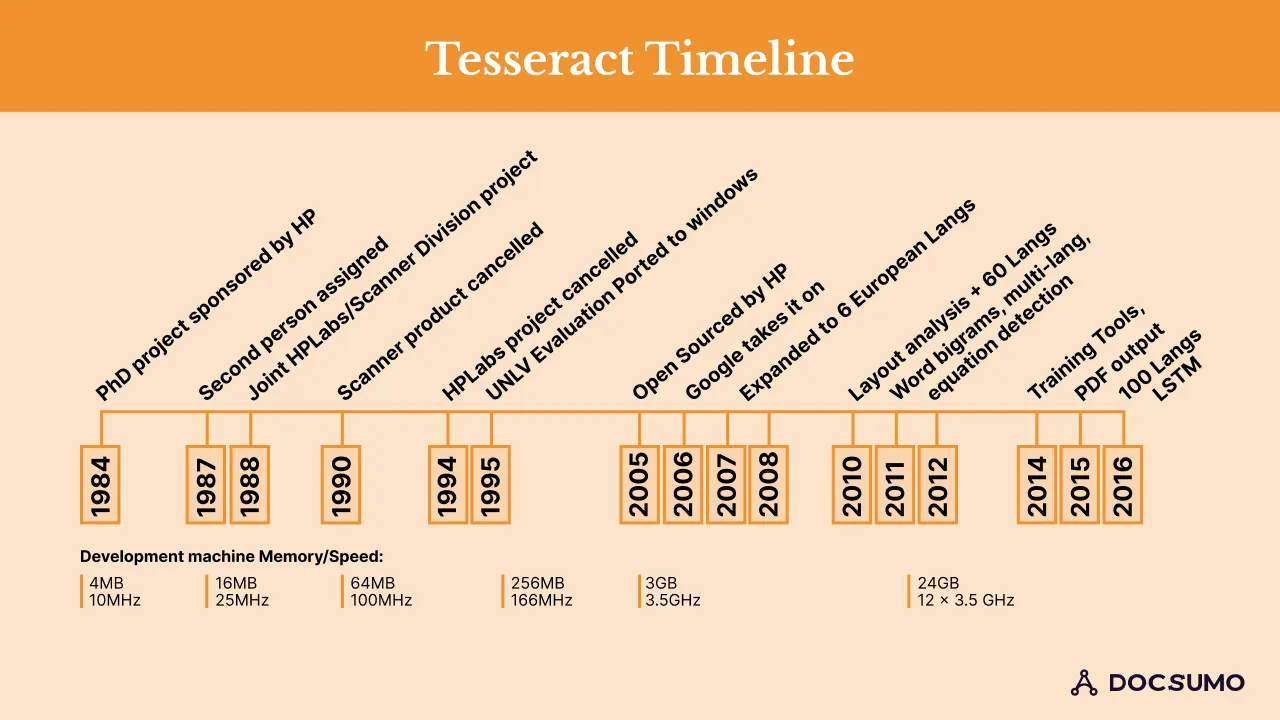
One powerful OCR solution that has been popular for a long time is Tesseract. Tesseract began as a Ph.D. research project at HP Labs in Bristol. It gained popularity and was developed by HP between 1984 and 1994. In 2005 HP released Tesseract as an open-source software. From 2006 until November 2018 it was developed by Google. Currently, it is maintained by open-source developers around the world.
Tesseract provides developers with a robust and versatile toolset for integrating OCR capabilities into their applications.
In this article, we will explore Tesseract for OCR in detail. We will delve into its benefits, understand how it works, and provide code examples to demonstrate its usage. Whether you are a seasoned developer or just starting your journey, this article will equip you with the knowledge to leverage Tesseract effectively.
Let's begin by highlighting the reasons why Tesseract stands out among other open-source OCR solutions in the market.
Why use Tesseract api?
Before anything, let's see why you could use Tesseract for your projects:-
1. Wide range of supported languages
One of the key advantages of Tesseract is its extensive language support. It can recognize text in over 100 languages. This multilingual capability makes Tesseract suitable for global applications and projects that involve diverse language requirements.
2. An open-source solution
Tesseract is an open-source OCR engine, available under the Apache 2.0 license. This means that the software is freely available for commercial use. For developers, it also means that they can access its source code, modify it to suit their needs, and contribute to its improvement. The open-source nature of Tesseract fosters a collaborative community that continuously enhances its capabilities and ensures compatibility with different platforms. Since Google stopped maintaining Tesseract api in 2018, it has been continuously maintained by open-source developers. The current major version of 5.0.0 was released on November 30, 2021.
3. Wrappers like Pytesseract
Various wrapper libraries and APIs have been built on top of Tesseract. The wrappers offer additional functionality and ongoing support. They simplify the usage of Tesseract by providing a more user-friendly and high-level interface in popular programming languages like Python, Java, GO, etc. Pytesseract, for example, enables developers to easily integrate Tesseract OCR functionality into their Python applications, reducing the learning curve and making OCR implementation more accessible.
By leveraging wrappers like Pytesseract, developers can utilize Tesseract's powerful OCR capabilities without dealing with the intricacies of low-level API interactions. This abstraction layer allows for quicker development and prototyping, making Tesseract more approachable for semi-technical users as well.
How does Tesseract work?
Tesseract Timeline
At the time of writing this article, Tesseract 5.3.2 is the latest version. From version 4.0.0 onwards, Tesseract uses LSTM-based architecture.
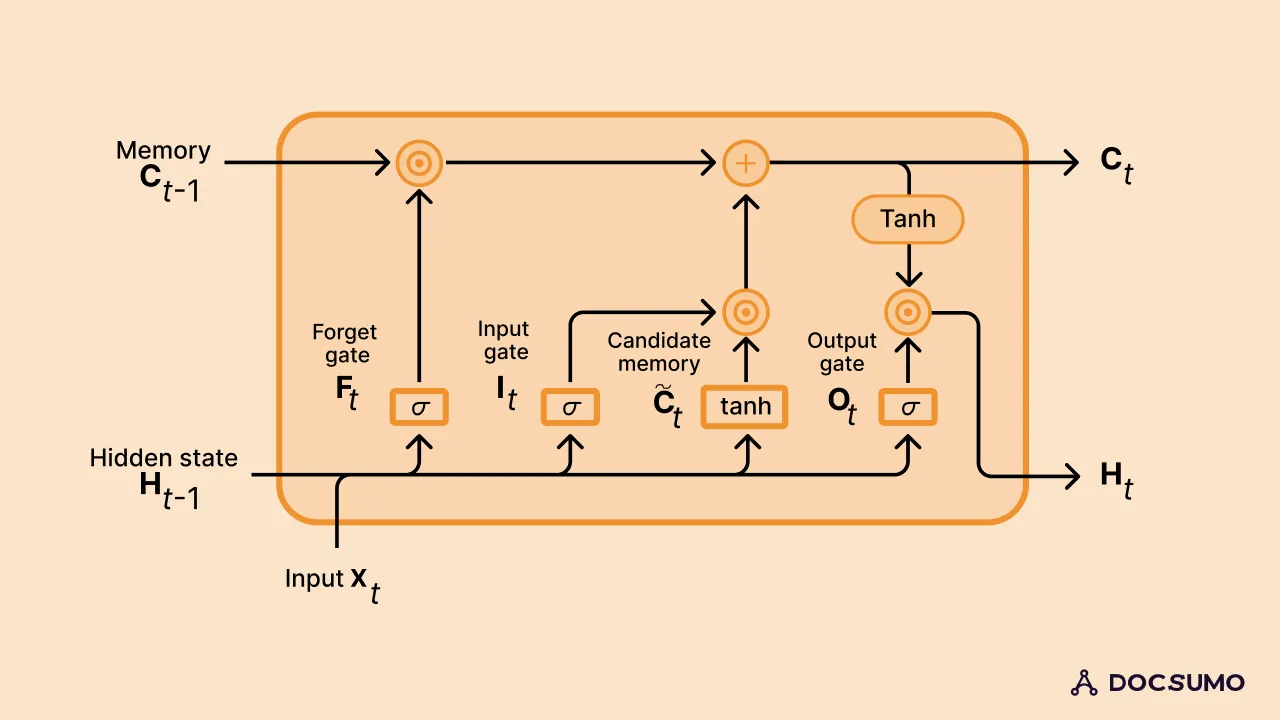
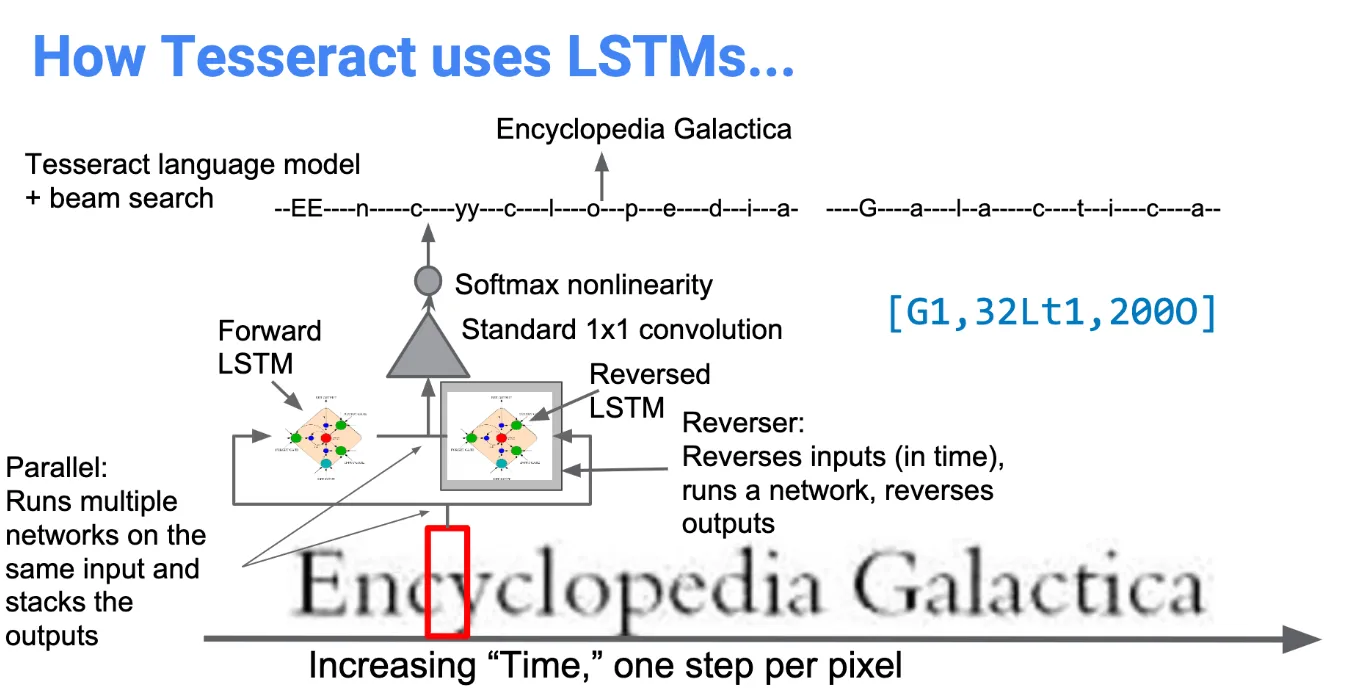
Long-Short Term Memory (LSTM) is a special type of RNN architecture capable of learning long-term dependencies. It provides a solution to the vanishing gradient problem that can occur when training traditional RNNs by using cell state and various gates.
LSTM Architecture
Legacy Tesseract 3.x was dependent on the multi-stage process where we can differentiate steps:
Input: Tesseract takes an image with words as input, assuming it's already prepared with clear text regions.
Connected Component Analysis: It breaks down the image into individual parts that make up letters and symbols.
Blobs and Lines: These parts are grouped into blocks called "blobs," and blobs are organized into lines of text.
Word Segmentation: Lines are split into separate words based on the spacing between characters.
Two-step Recognition: Tesseract tries to read each word in two steps. In the first pass, it does its best to recognize words. Words that are recognized become training examples for a smarter system in the second pass.
Correction Pass: In the second pass, Tesseract goes back to fix any mistakes it made in the first pass.
Final Adjustments: It fine-tunes spacing between words and looks for small capital letters.
In a nutshell, Tesseract 3.x takes an image of text, figures out where the words are, tries to read them twice to improve accuracy, and makes final adjustments for better results.
Modernization of the Tesseract tool was an effort on cleaning code and adding a new LSTM model. The input image is processed in boxes (rectangles) line by line feeding into the LSTM model and giving output. In the image below we can visualize how it works.
How to install the latest Tesseract
Installing Tesseract on Windows is easy with the precompiled binaries found here. Don't forget to edit the “path” environment variable and add the Tesseract path.
Now, you can install the python-wrapper for Tesseract using pip in your environment.
pip install pytesseract
How to use the Tesseract library
As mentioned earlier, we can use the command line utility or the Tesseract API to integrate it into our C++ and Python applications. In the fundamental usage, we specify the following:-
1. Input filename: We use test_image.jpg in the examples below
2. OCR language: The language in our basic examples is set to English (eng). On the command line and pytesseract, language is specified using the -l option. Languages supported.
3. OCR Engine Mode (OEM): Tesseract 4 onwards we have two OCR engines - 1) Legacy engine 2) Neural nets LSTM engine. There are four modes of operation to choose from using the –oem option.
Legacy engine only (0)
Neural nets LSTM engine only (1)
Legacy + LSTM engines (2)
Default, based on what is available (3)
4. Page Segmentation Mode (psm): By default, Tesseract expects a page of text when it segments an image. If you're just seeking to OCR a small region, try a different segmentation mode, using the --psm argument. There are 14 modes available which can be found here. By default, Tesseract fully automates the page segmentation but does not perform orientation and script detection. In the below examples, we will stick with psm = 3 (i.e. PSM_AUTO). When PSM is not specified, it defaults to 3 in the CLI and pytesseract but to 6 in C++ API.
Command Line Usage (CLI)
The example below shows how to perform OCR using Tesseract CLI. The language is chosen to be English and the OCR engine mode is set to 1 (i.e. Neural nets LSTM only).
Output to ocr_text.txt:
tesseract test_image.jpg ocr_text -l eng -oem 1 -psm 3
Output to terminal:
tesseract test_image.jpg stdout -l eng -oem 1 -psm 3
OCR with OpenCV and pytesseract
Pytesseract is a Python wrapper for Tesseract. It can read all image types supported by the Pillow and Leptonica imaging libraries, including jpeg, png, gif, bmp, tiff, and others.
The basic usage requires us first to read the image using OpenCV and pass the image to the image_to_string method of the pytesseract class along with the language.
# Install opencv and pytesseract in you python environment
pip install opencv-python pip install pytesseract
import cv2 import pytesseract
if __name__ == '__main__': img = cv2.imread("test_image.jpg")
# define config parameters # -l eng for using English language (the default language is eng) # -oem 1 sets LSTM only mode config = r'--oem 1 -l eng -psm 3' pytesseract.image_to_string(img, config=config)
Preprocessing for Tesseract
There are a variety of reasons you might not get good-quality output from Tesseract. You need to preprocess the image before sending it to Tesseract.
This includes rescaling, noise removal, binarization, deskewing, etc. You will find the full list here.
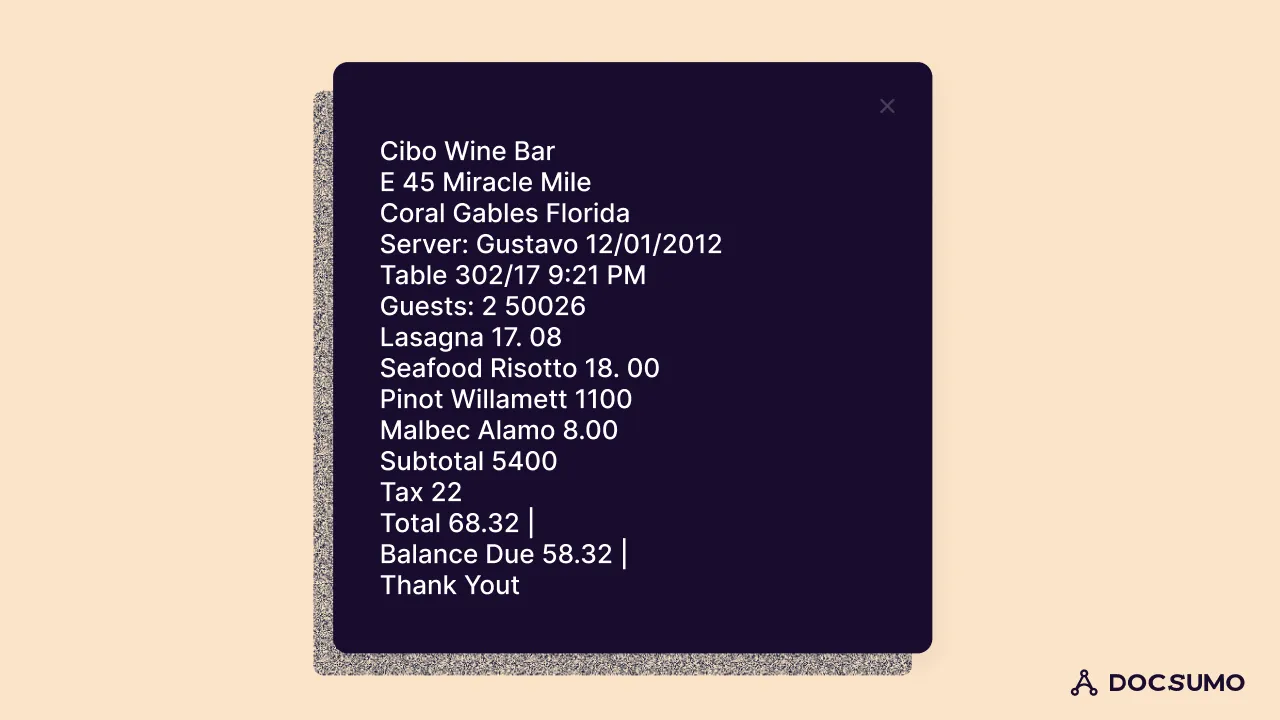
As you can see, without any preprocessing we already have a pretty accurate OCR extraction. Let’s do two simple preprocessing to try to improve accuracy- rescaling and converting to grayscale.
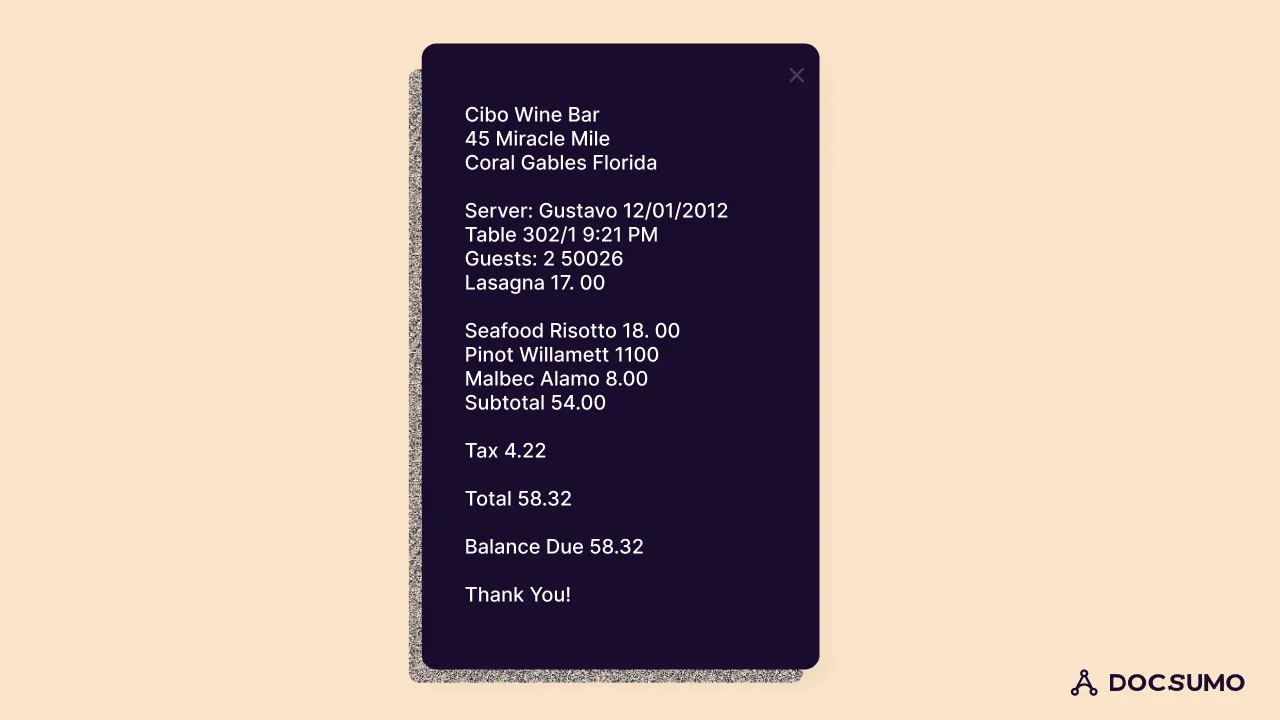
We now have a further improved ocr extraction.
Multi-language support
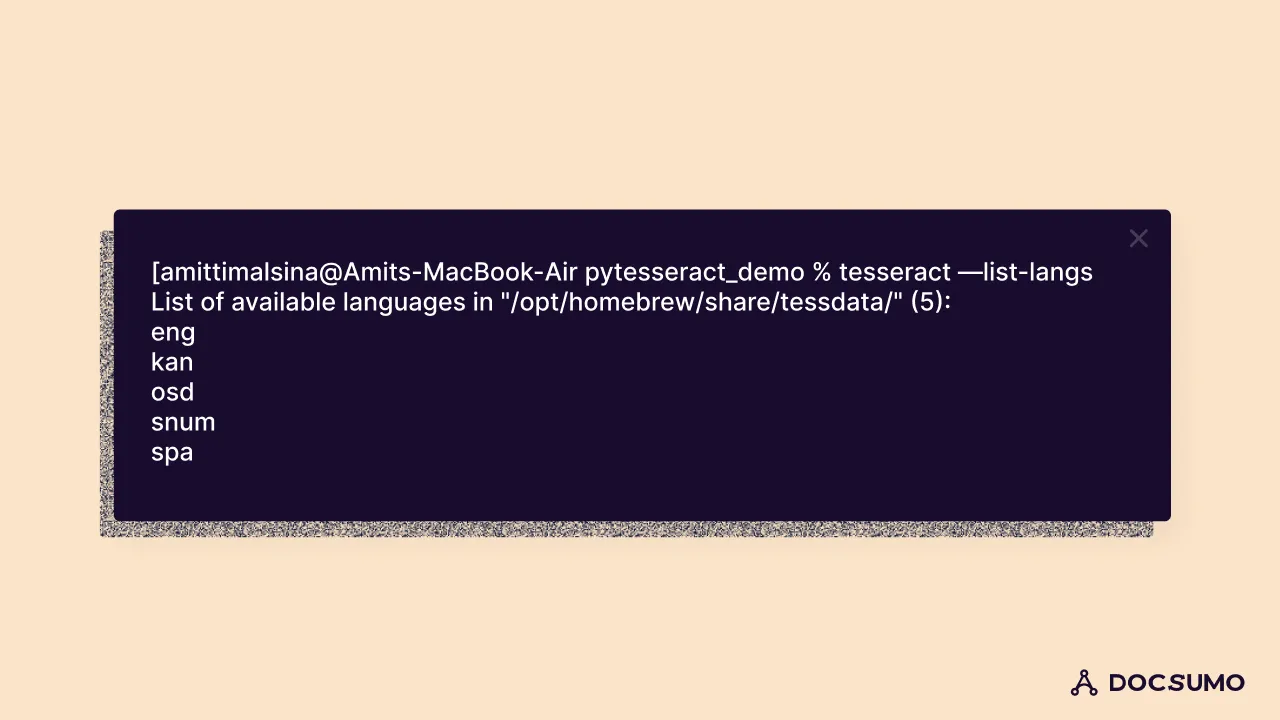
Let’s check the languages available by tying the following command in terminal
tesseract --list-langs
You can download the .traindata file for the language you need from here and place it in the/opt/homebrew/share/tessdata/ directory as shown in the above image (this should be the same as where the tessdata directory is installed) and it should be ready to use. You can export it:
config = r'-l kan+chi_sim --psm 6' text = pytesseract.image_to_string(kan_shi_im, config=config)
Output:
¡ಹಲೋ ವರ್ಲ್ಡ್! 你 好 世 界 !
Faster OCR extraction
If speed is a major concern for you, you can replace your tessdata language models with tessdata_fast models which are 8-bit integer precision versions of the tessdata models.
These models only work with the LSTM OCR engine of Tesseract 4.
This is a speed/accuracy compromise as to what offers the best "value for money" in speed vs accuracy.
For some languages, this is still best, but for most not.
The "best value for money" network configuration was then integrated for further speed.
Most users will want to use these trained data files to do OCR and these will be shipped as part of Linux distributions eg. Ubuntu 18.04.
Fine tuning/incremental training will NOT be possible from these fast models, as they are 8-bit integers.
When using the models in this repository, only the new LSTM-based OCR engine is supported. The legacy tesseract engine is not supported with these files, so Tesseract's oem modes '0' and '2' won't work with them.
To use tessdata_fast models instead of tessdata, all you need to do is download your tessdata_fast language data file from here and place it inside your $TESSDATA_PREFIX directory.
Extract boxes along with text
Till now, we have used the pytesseract.image_to_string() method which returns the ocr text. With pytesseract, we can also get the bounding box information for your ocr text.
The code block below will give you bounding box information for each character detected by Tesseract during OCR.
We will use left, top, width , and height data to create the box. All the other keys can be used for many other use cases.
for i, (left, top, width, height) in enumerate(zip(data["left"], data["top"], data["width"], data["height"])): if int(data["conf"][i]) > 70: (x, y, w, h) = (left, top, width, height) img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2) cv2.imshow("img", img) cv2.waitKey(0)
Output:
Limitations of Tesseract
Tesseract comes with certain limitations that should be taken into consideration when evaluating its performance for various tasks. As a Machine learning engineer who has worked with both Tesseract and commercial OCR engines like Google Vision AI and Amazon Textract, I have encountered several limitations of Tesseract that are important to highlight.
Preprocessing Dependency: Tesseract requires meticulous preprocessing to optimize results, varying with image quality and conditions. Tesseract works best when there's a clean segmentation of the foreground text from the background. In practice, ensuring these sorts of setups is often extremely challenging.
Scanned Images: It's less effective with scanned documents due to issues like artifacts and skewed text.
Complex Layouts: Tesseract has problems with reading the order of the page. Hence, it struggles with intricate layouts, multi-column text, and unconventional arrangements.
Handwriting Recognition: Handwritten text is a challenge, as Tesseract is tailored for printed text.
Language and Fonts: Performance fluctuations are observed with less common languages and fonts.
Gibberish Output: Tesseract may generate gibberish and report it as OCR output, affecting data accuracy.
Customization Complexity: Customizing Tesseract requires understanding its parameters, involving trial and error.
Resource Intensive: Processing demands are high, impacting speed and resource consumption.
In summary, Tesseract excels in text extraction but demands preprocessing, and has limitations with scanned and complex content.
Conclusion
The evolution of Optical Character Recognition (OCR) technology is truly remarkable, with its roots tracing back as early as 1914 with the invention of the OPTOPHONE; a device that employed the unique conductive properties of selenium in light and darkness. Over the passage of time, OCR has experienced a significant transformation, shifting from the utilization of elements like selenium to harnessing the power of advanced deep learning techniques.
Tesseract performs well when document images adhere to specific guidelines: clean foreground-background segmentation, proper horizontal alignment, and high-quality images without blurriness or noise.
Tesseract API, with its rich history and constant development, shines as a versatile solution for Optical Character Recognition (OCR). Its latest LSTM engine has been trained in over 100 languages. This makes it one of the best open-source OCR solutions. I hope this article has provided you with a clear understanding of how you can use Tesseract.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.