Oops! Something went wrong while submitting the form.
Today, optical character recognition (OCR) plays an instrumental role in extracting data from digital documents and scanned images. Pattern recognition technology took shape almost 100 years ago. Many iterations later, it evolved into optical character recognition solutions that are now being used.
Fast-forwarding to the present, this technology is used by organizations to digitize their archaic physical records and convert structured, semi-, and unstructured data from documents, PDFs, and images into machine-readable text.
In this article, we cover the history of OCR technology: how it began, its evolution over the years, and where it is today.
So, let’s jump right into it:-
Early Concepts (1920s-1930s)
OCR technology has ties to telegraphy. Around the time of the First World War, typewriters and telegraphs were already in use. Physicist Emanuel Goldberg invented a machine that could read characters and convert them into telegraph code.
What happens next?
Statistical Machine
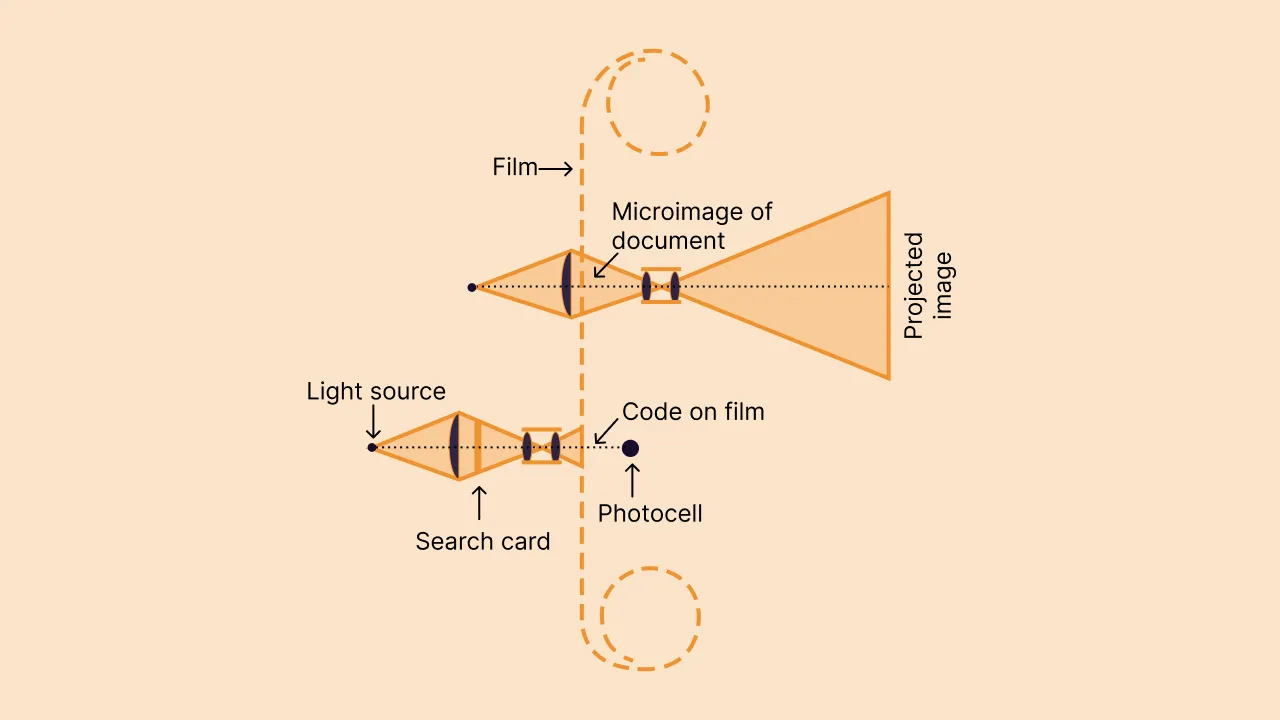
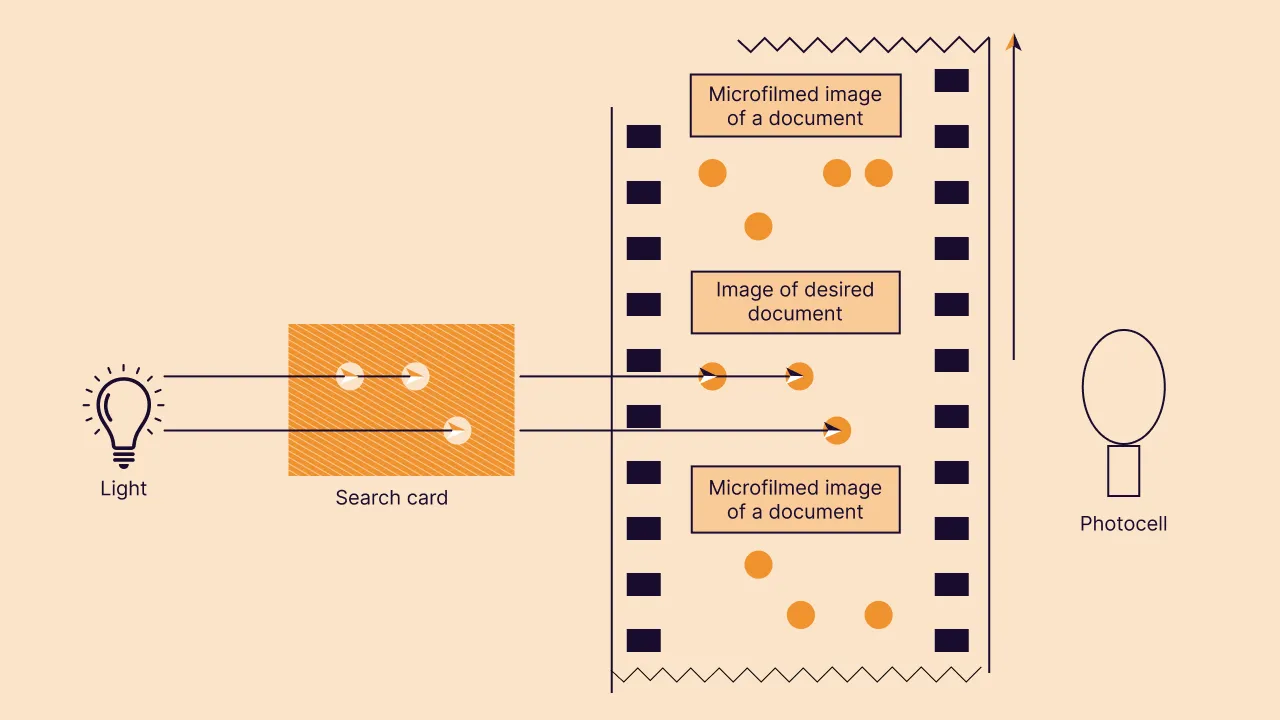
In the 1920s, he went further and created the first electronic document retrieval system. While businesses were microfilming financial records at that time, retrieving specific records from films was still impossible. To overcome this shortcoming, Goldberg used a photoelectric cell for pattern recognition using a movie projector, and this machine was called “The Statistical Machine.”
The machine could sort mail and decipher bank checks through patterns that were unseen by the human eye.
Analog Reading Machine
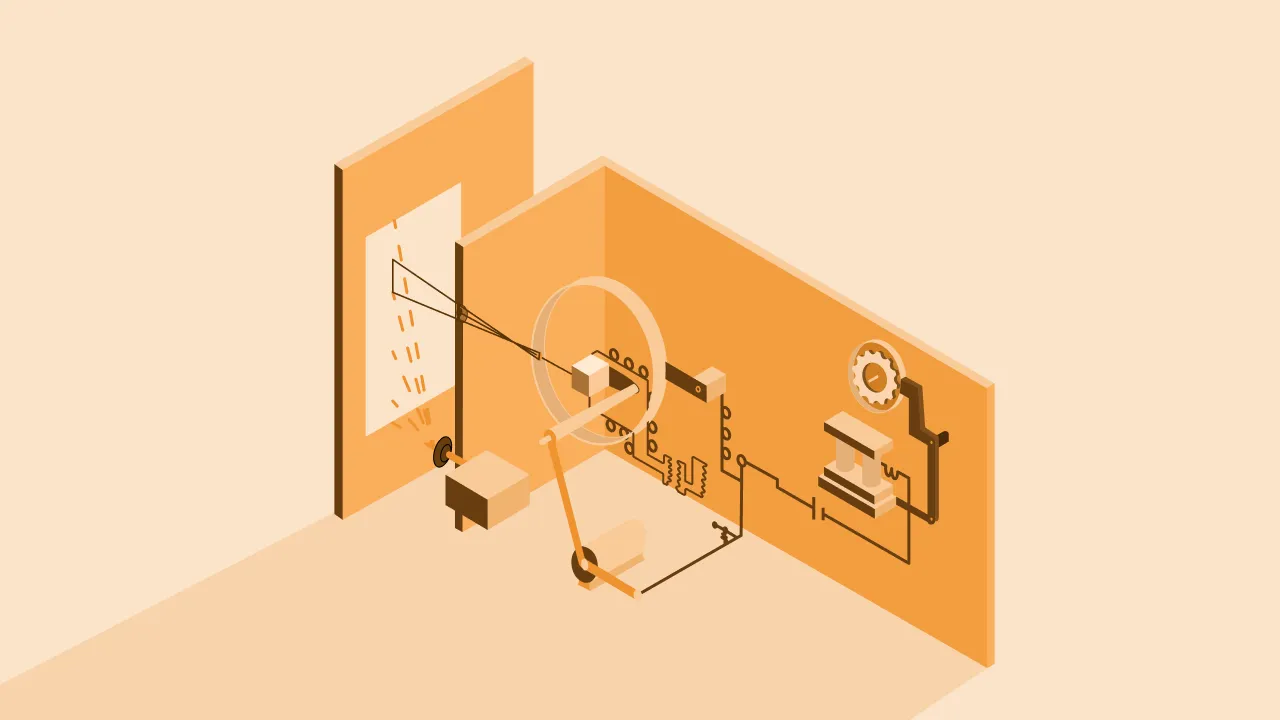
In 1929, Gustav Tauschek, a self-taught Austrian inventor, used the template of Goldber’s photoelectric detector to create Tauschek’s Analog Reading Machine.
The Reading Machine had a small window to scan the images with text. Whenever the image passed in front of the window, a small disk would start turning behind it. This disk had small cutouts in the shape of numbers and alphabets.
Anytime there was a match, the machine would automatically trigger the printing drum for the corresponding letters. And, finally, the text was printed onto a piece of paper.
First OCR Machine (1950s)
The 1950s marked a time of rapid growth in the technology sector. The exponential growth in data volumes increased the need for efficient data processing platforms. The traditional reading machines failed here, as they couldn’t convert the scanned texts into machine-readable language.
GISMO
Like Gustav and Emanuel, David Shepard and Harvey Cook Jr. created a contraption called the GISMO which was labeled as the “Analyzing Reader'' during the patent filing procedure. It was capable of converting printed texts into machine language or code, thus starting the revolution in automated data capture techniques.
First Official Optical Character Recognition Machine
David, along with his colleagues Harvey and Willian Lawless Jr., established Intelligent Machines Research Co. (IMR) in 1952 with the hopes of commercializing the product to recoup their investment costs.
The American magazine publisher Reader’s Digest bought the machine for commercial use, and soon others, including the National City Bank, AT&T, banking, and major oil companies, also adopted the machine.
After a year of unparalleled prosperity, IBM obtained the license for all of IMR’s patents along with a long-term contract to work on a developmental machine. In 1959, IBM introduced a brand new system for capturing data from documents and named the machine Optical Character Recognition (OCR), making it the standard terminology in this industry.
Pattern Recognition Advancements (1960s-1970s)
By the 1960s, MIT had already established a research group to enhance the software capabilities of these machines and streamline the data capture and storage process. A few of the researchers branched out to create a sophisticated algorithm that would continue to analyze data and learn how to adapt to changing document formats.
However, they could not proceed with the algorithm as they were limited by their workstation’s computational power. Little did they know, they were on the brink of introducing machine learning algorithms to OCR, but we’ll cover this later.
Hough's Transform Technique
At the same time, another group of researchers developed the Hough Transform Technique. The invention of this data capture technique was considered phenomenal as it enabled the OCR machines to capture geometric shapes along with all the letters of the English language.
ICR and MICR (1960s-1970s)
Amid the evolving landscape of OCR technology in the 1960s and 1970s, two notable technologies emerged - Intelligent Character Recognition (ICR) and Magnetic Ink Character Recognition (MICR).
ICR technology
As the demand for handwritten text recognition grew, researchers came up with the ICR technology. MIT's pioneering research group refined OCR's capabilities to decipher handwritten characters, marking the birth of the ICR algorithm. This laid the foundation for future machine learning-driven advancements, set to revolutionize OCR technology.
MICR technology
In the banking industry, the need for efficient check processing led to the development of MICR technology. By embedding magnetic ink characters in checks, automated systems can rapidly read and process these documents. This innovation streamlined financial operations and illustrated OCR's practical applications beyond traditional text.
From deciphering handwritten scripts to simplifying financial transactions, the emergence of ICR and MICR technologies highlighted OCR's adaptability and its transformative potential across diverse sectors.
Advancements in Digital OCR (1980s-1990s)
In the 1980s and 1990s, the OCR technology started getting applied in the digital domain and the shift to digital imaging amplified OCR's potential.
Improved algorithms tackle diverse fonts and layouts, enabling companies to automate parts of their data entry processes. Advanced machine learning algorithms improved the handwriting recognition capability of OCR machines. The newer algorithms also increased the accuracy rate of the extracted data.
In other words, the advancements in OCR technology were slowly making the use of ICR solutions redundant.
Document layout analysis discerning structures, leading to better data extraction from tables and graphs. Furthermore, multilingual support catered to the global needs of multinational corporations.
Lastly, the advancements during the 1980s allowed companies to focus more on the software side of optical character recognition technology as opposed to making constant improvements to the hardware. Desktop software transformed OCR technology from experimental to practical, paving the way for the present-day more powerful commercial systems.
Commercial OCR Software (1990s)
The 1990s marked a pivotal era in the history of this technology, with the widespread availability of commercial OCR software bringing it within reach for businesses and individuals.
Prominent players like ABBYY, Adobe, and Nuance bridged the gap between the paper and digital worlds. These tools empower users to convert scanned documents into editable text, fueling efficiency and productivity.
Businesses can now digitize archives, streamline workflows, and harness the power of searchable electronic documents. Paper and document-heavy industries could now extract information from printed material without employing manual labor, catalyzing the transition toward a more interconnected information landscape.
Tesseract OCR (2005)
The early 2000s did not witness any gigantic leaps in either the hardware or software aspects of the OCR technology, but with the open-source resurrection of Tesseract OCR in 2005, it experienced a significant revival.
Originally developed by Hewlett-Packard in the 1980s, Tesseract was released as an open-source project under Google.
Tesseract OCR incorporated advancements in machine learning and computer vision. It is free to use either directly or using an API (application programming interface). This version showcased remarkable capabilities and demonstrated exceptional accuracy in text extraction from various sources.
Tesseract's open-source nature facilitated community collaboration and accelerated its growth. As a result, it became one of the most widely used and respected OCR engines globally.
Deep Learning Revolution (2010s)
Introducing neural networks, particularly Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), marked a transformative leap forward in OCR technology during the 2010s.
Deep learning's intricate architectures brought about a paradigm shift and drastically increased the accuracy of OCR software to nearly 99%. CNNs excelled in image feature extraction, deciphering complex fonts, and handling diverse layouts with remarkable precision. RNNs further refine contextual understanding and enhance recognition in varying languages and handwriting styles.
This combination of deep learning and OCR platforms brought a significant change. Handwritten text interpretation, once a tedious challenge, improved significantly, while complex document structures posed fewer obstacles.
Integration of OCR technology in everyday life (Present-day)
OCR software has become an indispensable part of all industries that involve document processing, like real estate, financial lending, banking, insurance, and healthcare, among many others. Organizations use these solutions for automated document processing with minimal human intervention.
Unlike in the past, they do not have to invest in bulky OCR machines. A simple subscription to an OCR platform is more than enough to get the digitization process started. Let’s look at some of its industry-wise applications.
Logistics
The logistics industry is paperwork dependent. The shipping company has to manage invoices, fuel bills, insurance documents, inventory lists, and car registration papers, among other things.
OCR-powered intelligent document processing platforms help prepare these documents for processing, analysis, and data extraction. The ML algorithm manages these custom documents and enables the organization to keep track of all the shipments.
The software extracts the data from these documents and populates the Excel sheets with the relevant data.
Insurance
The insurance sector uses OCR-powered intelligent document processing (IDP) software to streamline operations such as form processing to information verification and claim settlement. Automated insurance form processing minimizes errors whereas automated data extraction and analysis speeds up claim assessment. The software integrates with third-party systems for further processing of the information and stores data in a centralized database hosted in the cloud.
Banking
Banking is another paper-first industry that benefits extensively from the integration of OCR platforms for several processes such as:
Automatic creation of customer profiles based on extracted information from sign-up forms.
Automated bank statement data extraction and verification.
Loan and mortgage documents are automatically re-routed for necessary approval.
AI-powered pattern recognition for fraud and scam detection.
Real Estate
Real estate documents are highly sensitive and need to be processed under scrutiny to avoid any conflicts in the future.
The company’s internal systems are automatically updated with leases, rental agreements, and sale deeds.
Categorizes and sorts scanned documents and improves searchability and accessibility.
The IDP system automatically extracts the data from different documents and validates them downstream for final approvals.
Conclusion
Now that you know the entire history of OCR technology as well as the importance of this technology in extracting data from unstructured, structured, and semi-structured documents, it is time to introduce Docsumo.
Document AI platform Docsumo is trusted by global data-driven businesses and has the following key offerings:
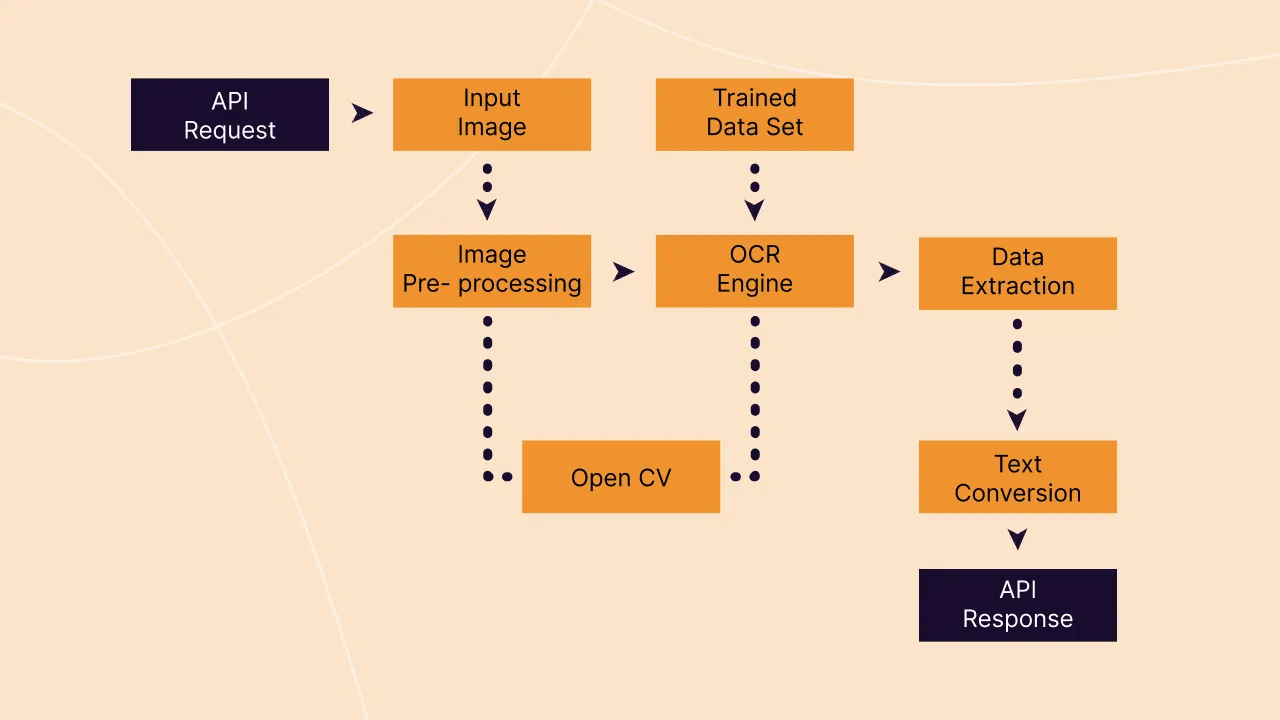
Ingests, classifies, and pre-processes documents with powerful APIs
Intelligent AI accurately captures key values and tables from even unstructured documents
Native Excel-like formulas validate extracted data within the documents
Directly integrates data with downstream systems
End-to-end data encryption
Try Docsumo’s advanced OCR features with our 14-day free trial, and make us part of your company’s future.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.




.webp)