Future of Intelligent Document Processing: How Will Automation Reshape Document Processing?
Learn about the advancements and possibilities shaping the future of Intelligent Document Processing (IDP). Read the blog to see how businesses handle these trends with efficiency and precision.

%20Look%20Like_.webp)
Managing documents is a huge part of every office worker's daily tasks. From invoices and purchase orders to contracts, reports, and more, paper piles up quickly. It's estimated the average employee handles over 10,000 sheets annually.
This endless paperwork has drawbacks - time spent searching for information buried among documents, duplicating effort, and reduced efficiency as high as 30-40%. However, a solution exists to tackle this productivity drain—intelligent Document Processing (IDP). Leveraging artificial intelligence and machine learning,
IDP helps streamline information access, remove duplicates, and simplify approval processes. This blog will examine IDP's future prospects.
What is Intelligent Document Processing?
Companies are streamlining some of their tedious office tasks through intelligent document processing, or IDP. IDP allows businesses to automate various intelligent document processing workflows, including the data entry process from paper documents and scans into their digital systems.
In addition to data entry, IDP can handle more complex tasks like document classification and data validation. For example, IDP can classify invoices, receipts, claims forms, and other documents based on their structure and content. It can also validate data by ensuring fields like amounts, dates, and codes are in the expected format.
For example, let’s say a company has an automated inventory system. When a stock gets low, it automatically generates orders to suppliers. But shipments can't go out until payment is received. Suppliers will email over invoices, but someone on the accounts team has to manually input all those details before paying up. This introduces human errors and bottlenecks that can slow things down.
With IDP, the technology can extract key information like prices and totals directly from digital invoice files. It plugs that data straight into the accounting software in the proper format, eliminating tedious manual data entry by employees.
The Evolution of Intelligent Document Processing
Document processing dates back to the earliest days of human civilization. However, document management became recognizable only after Edwin Sebels conceptualized the filing cabinet in the late 19th century.
His innovative creation was a game-changer for organizing and retrieving documents, becoming an indispensable tool for medical, law, and finance professionals. Introducing computers and early automation technologies reshaped document management practices entirely, ushering in the era of Intelligent Document Processing (IDP).
1. Traditional Document Processing Methods
Older document processing systems have some limitations compared to newer AI-based approaches. These traditional methods rely heavily on predefined rules and automation programmed by people.
The process typically starts with scanning paper documents to make them digital. The software straightens crooked pages and converts the colors to black and white.
It then tries to identify the document type, such as an invoice or contract. You usually do this with simple keyword spotting or looking at the layout. It is not as sophisticated as modern machine learning techniques.
Once the type is known, it pulls out specific data like names, dates, numbers, etc. This often involves recognizing text with optical character recognition (OCR). Then, rules are applied to find the right fields in typical places.
There are challenges, though. It can need help with complex layouts that don't follow expectations. Moving data to other teams involves printing or using couriers, which is not as seamless as uploading a digital file.
2. Emergence of Automation and AI
Advances in automation and artificial intelligence (AI) are gradually overcoming the limitations of traditional processes. Soon, machines might handle document processing from start to finish with minimal human input.
AI-based document processing are getting better at understanding documents, extracting info, and making decisions based on their findings.
We're already seeing this shift with platforms like ChatGPT, which uses natural language processing and advanced algorithms. As they get more training, platforms more accurately recognize, summarize, translate, and create content.
AI tech is also highly adaptable, allowing processes to change quickly to keep up with the fast-changing market. AI algorithms can analyze data from different sources, like customer behavior and market trends, to provide valuable insights allowing businesses to make smart, strategic decisions in real time.
3. Transition to Intelligent Document Processing
In the early 1900s, people first figured out how to make copies of printed words with machines. It allowed businesses to start organizing all their paper trails, but handling documents was still lots of grunt work.
Technology helped pick up some slack step-by-step. Early programs let people type information directly instead of writing it out. Storing information in computer filing cabinets also reduces errors. While it might seem straightforward today, those early pioneers initiated the shift toward change. Information could flow within the office without passing papers hand to hand.
As more programs joined forces, efficiency boomed. Multi-step tasks that dragged on for hours shrank to minutes. Behind the curtains, the software tools were soaking up user habits and learning patterns to handle chores independently.
This is how IDP emerged. By integrating machine intelligence, such as artificial intelligence and document processing, its capabilities were enhanced.
Today, intelligent document processing fuels automation everywhere. Hospitals, banks, and law offices benefit from digitizing mounds of paper instantly. The technology gets documents to pluck out significant bits immediately, saving hours of data entry grunt work. Plus, machine learning lets it self-improve forever without extra coding.
Learn more about how Docsumo's IDP platform can help your business.
Automate Manual Work. Unlock Human Efficiency
.png)
Key Components of Intelligent Document Processing
Let's delve into its key elements, from OCR to machine learning. IDP uses advanced technologies to automate and streamline data extraction, processing, and analysis from various document formats.
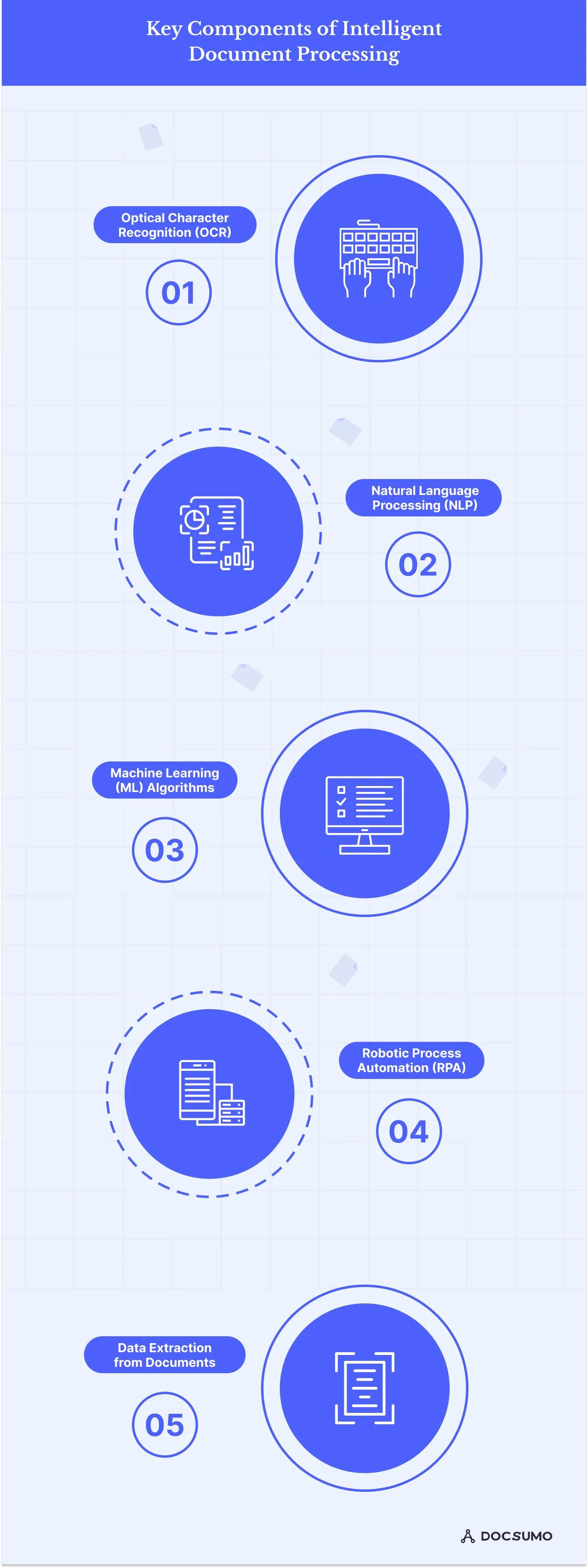
The key components that form the backbone of IDP solutions are:
1. Optical Character Recognition (OCR)
Optical character recognition (OCR) is essential for intelligently analyzing documents because it allows companies to convert unstructured text-based documents like images and PDFs into editable, searchable digital text files.
However, OCR is still prone to errors, especially regarding messy or degraded documents. Digitization is the first major step before more advanced natural language processing and machine learning techniques can be applied.
2. Natural Language Processing (NLP)
Natural language processing involves applying named entity recognition, part-of-speech tagging, and sentiment analysis to understand written content's meaning, entities, and structure. Using NLP on digitized text from documents enables useful applications such as automatic data extraction, document classification, and summarization.
This removes much of the manual work typically required. However, NLP algorithms still face challenges with ambiguity, context, nuance, and other language complexities.
3. Machine Learning (ML) Algorithms
Machine learning algorithms play an important role as well. Different ML models, such as document classifiers, topic models, and similarity analysts, are trained in large collections of documents to discover patterns and insights humans may miss.
The models can then be applied to new incoming documents to determine attributes, categories, and key topics without explicit rule programming. This results in an intelligent and automated classification process.
Despite the benefits, training high-quality ML models can be challenging due to data bias, lack of labeled examples, and overfitting.
4. Robotic Process Automation (RPA)
Robotic process automation, or RPA, complements the other techniques by automating repetitive document tasks through software robots.
RPA streamlines processes such as ingesting large volumes of documents, extracting specified data fields, and routing documents appropriately based on attributes. This benefit allows you to massively scale their document processing capabilities while freeing employees to focus on more strategic work than manual data entry and form filling.
Combined with other technologies, RPA enables truly end-to-end intelligent document processing. However, RPA requires clearly defined processes to be automated, and complex decision-making tasks may require more work for software robots to handle.
By integrating key parts, IDP allows you to fully utilize the information within their document collections. This allows for new ideas, improved customer interactions, and faster modernization efforts in many business areas.
How Does Intelligent Document Processing (IDP) Work?
As the capabilities and benefits of IDP become more widely recognized, the global market for these solutions is experiencing rapid growth. According to recent forecasts by Markets, the intelligent document processing market size is expected to increase from $1.9 billion in 2023 to an estimated value of $17.8 billion by 2032.
%2520Work_.webp)
This represents a strong compound annual growth rate of 28.9% as companies increasingly invest in AI-powered systems to unlock value from their documents and records.
1. Data ingestion
Data comes from various sources, such as documents, files, and other content. The information needs preparation before you can properly examine it. You may need to combine or separate documents and fix poorly scanned or copied pages. Some programs let humans help review and label parts of the data, working together with the technology.
Once gathered, the content is imported into the analysis system. It first uses optical character recognition (OCR) to convert images into searchable text.
Noise reduction and alignment corrections also process the data, improving readability and legibility for downstream understanding. With these capture and processing techniques, the information is cleaned, organized, and formatted to be readily studied by advanced computational models.
2. Document classification
The next phase involves organizing the information into categories,i.e., Document Classification. The content gets analyzed to determine its type, layout, and structure. Natural language processing techniques, which mimic how humans comprehend written works, are used to interpret the text in context. The process lets you uncover essential details.
Through classification, related materials are clustered together, establishing a company that supports deeper understanding in later stages of review.
3. Data extraction
Once you've organized your documents, how intelligent document processing software extracts data depends on how well it understands the content. The intelligence of artificial intelligence (AI) relies heavily on its training, so the system needs to be adaptable enough to find and categorize all the expected information in a document.
The process involves identifying parts of the text written in everyday language and extracting specific details like dates, names, and numbers. The software achieves this using machine learning (ML) models trained to recognize patterns.
These models help the software locate and retrieve relevant data, such as names, addresses, and numerical figures. Over time, ML continuously improves the software's performance, making the extraction process more accurate and efficient.
As the volume and variety of documents continue growing across organizations, intelligent data extraction has become imperative for efficient document processing at scale.
Validate how Docsumo streamlines document workflows with pre-trained and customizable AI models by signing up for a free trial today.
3. Data Validation
Any errors in the gathered data are marked for inspection. Human reviewers look over discrepancies and make adjustments to streamline the model's selection process. This speeds up how quickly it learns from past outputs.
The finalized information is then imported into other databases or workflows for additional review.
4. Data Insights
Decision-makers use the insights extracted from the program's analyzed data to enhance organizational processes. Examining the data explains mistake frequencies and document handling speeds and standardizes information for easier use. The refined data allows for analyzing patterns, generating reports, or automatically starting specific workflows.
The Future Of Intelligent Document Processing (IDP) Solutions
As the volume of electronic documents grows exponentially, organizations will struggle to keep up with manual review and data extraction processes. Companies must spend countless employee hours processing paperwork, from onboarding new hires to complying with industry regulations.
To help address this problem, information analysis software providers are advancing intelligent document processing (IDP) capabilities. Future product improvements in this area will centralize on a few key aspects, such as:
1. Documents integrate deeper into workflows
Managing unstructured data effectively is more crucial than ever as businesses deal with ever-growing amounts of paperwork and data. Platforms for intelligent document processing (IDP) offer an answer by integrating easily into current workflows to improve productivity and collaboration.
2. Training models are the new gold standard
Finding new ways to streamline processing workflows is crucial for companies managing large volumes of documents. Traditional rules-based approaches need help to keep pace with growing complexity.
Meanwhile, machine learning models are uniquely positioned to drive the future of intelligent document processing because they can learn and improve continuously. Constant self-improvement lies at the heart of machine learning. Models examine incoming documents, extracting patterns to help you improve your algorithms.
Each parsed document offers a chance to understand different structural or semantic clues better and further optimize classification. This continuous training allows models to handle increasingly complex use cases.
3. Machine learning models tackle new forms of media
Machine learning models are advancing to process different unstructured data beyond documents. Advances in computer vision, natural language processing, and multimodal learning allow models to understand diverse content like videos, images, and audio.
Looking at the future of intelligent document processing, the technologies powered by image recognition and video analysis can automatically index and summarize visual content. Language models can intelligently answer questions across all formats.
For example, a user could ask, "What products are shown in the marketing webinar from last quarter?" and receive a precise timestamped response after intelligently processing video, audio, and text.
Looking to the future, the technologies powered by image recognition and video analysis can help automatically index and summarize visual content across various formats.
4. Improved accuracy in document organization
As the volume of documents organizations must process grows exponentially, ensuring high accuracy has become increasingly crucial. Thankfully, advances in machine learning are empowering intelligent systems with a richer understanding of the context that drives unprecedented accuracy gains.
Language models are developing a more nuanced grasp of situational awareness through extensive pre-training on textual data. This enables them to comprehend the situational context of documents and discern subtle relationships between concepts.
If current trends continue, intelligent document processing has the potential to automate most routine paperwork tasks and free up employees to focus on more strategic work. Great leaps in machine comprehension are poised to transform how we interact with information.
Conclusion: Using Docsumo for Intelligent Document Processing
Important operational processes in industries like insurance and finance often rely on intensive manual document processing. Sifting through paperwork to extract key data points can take time and effort. This wasteful process hinders organizations' ability to make timely decisions. Without streamlined document workflows, companies across industries struggle to keep pace with growing volumes and regulatory demands.
That's where Docsumo's intelligent document-processing solutions come in. Using powerful machine learning and AI, Docsumo can automatically extract structured data from complex insurance documents and financial forms with over 95% accuracy. This dramatically reduces manual handling times and allows organizations to refocus resources on more strategic work.
Docsumo provides pre-built APIs configured for common document types, eliminating lengthy model training. Customers simply upload their documents to immediately leverage Docsumo's intelligent extraction and validation capabilities.
Learn how you can pre-process documents using Docsumo.

Frequently Asked Questions
What is the need for intelligent document processing?

Intelligent Document Processing reduces overhead costs, and helps automate tasks, thereby eliminating the burden of repetition. You don't even have to worry about errors anymore, as IDP is known for being accurate.
How does AI contribute to making IDP more efficient and autonomous?
AI elevates the efficiency of IDP by making the best use of NLP, machine learning, and advanced algorithms.
What security measures can we expect in future IDP solutions to protect sensitive information?
In the future of intelligent document processing, you can expect innovative encryption methods and multi-factor authentication. You can even expect secured access limitations to protect important and sensitive data.
What is the CAGR of intelligent document processing?
The compound annual growth rate is expected to be 28.9% from 2023 to 2032. Currently valued at USD 1.38 billion, the IDP market is projected to expand at a CAGR of 30.12% and reach USD 11.34 billion by 2030.