Oops! Something went wrong while submitting the form.
Extracting data, especially tables from documents, and storing it digitally is a tedious task. A typical employee uses 10,000 sheets of copy paper every year and spends 30-40 percent of their time looking for information locked in email and filing cabinets. Artificial Intelligence has enabled us to rethink how we integrate information, analyze data, and use the resulting insights to improve decision making.It has done wonders for data extraction in semi-structured as well as unstructured documents—including manually written forms.
In this article, we discuss how different technologies help us capture data from unstructured documents. Amongst other elements, we're focussing on table extraction from pdf and images.
So, let's jump right into it:-
What is table extraction?
With the rise in volume, velocity, and variety, the need for automatically extracting the information trapped in unstructured documents such as retail receipts, insurance claim forms, financial documents, and many other countless documents is becoming more acute. A major hurdle to this objective is that these documents often contain information in tables and extracting data from tabular sub-images presents a unique set of challenges.
This includes accurate detection of the tabular region within an image and subsequently detecting and extracting information from the rows and columns of the detected table. While great progress has been made in table detection, extracting the table contents still possesses some challenges since this involves more fine-grained table structure(rows & columns) recognition.
Overall, Table extraction involves two preliminary tasks (in the order presented):
i) Table detection, and
ii) Table structure recognition.
Let’s discuss both of them:-
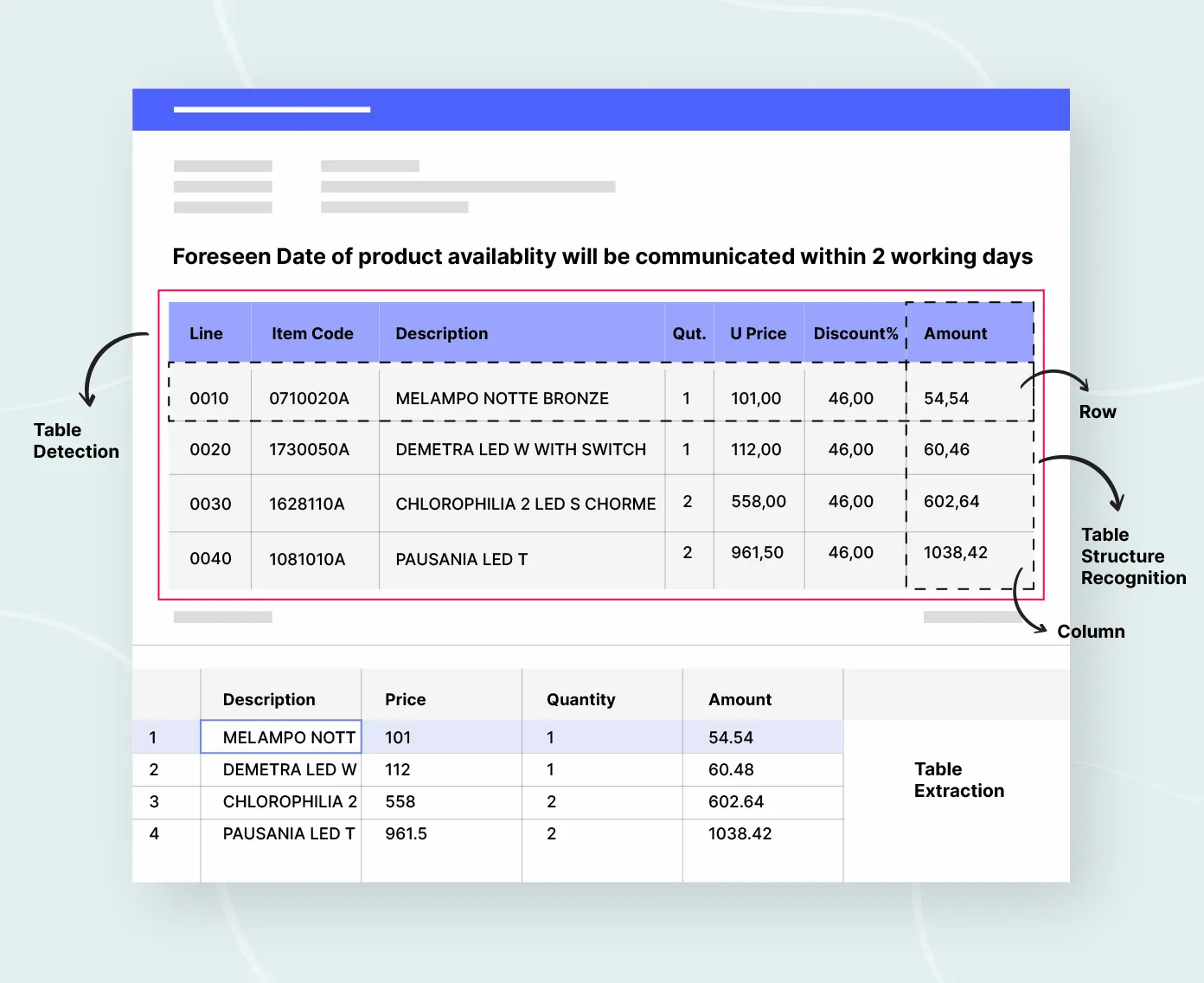
Table detection
Table detection is the task of detecting the image pixel coordinates containing the tabular sub-image.
In this image, the table detection algorithm has identified the table and highlighted it in red. This is the first step in the table extraction process, which involves identifying the table region so that further processing can be focused on that specific area.
Table structure recognition
Table structure recognition is the task of identifying the rows and columns.
The rows and columns are highlighted in red in the above image. The intersection of these rows and columns identifies the table cells, which contain information about table content.
Table extraction techniques
Because of the different document types and variety of document layouts, detecting and extracting images or document tables is challenging.
Table extraction has been studied for an extended period. Researchers used different methods that can be categorized as follows:
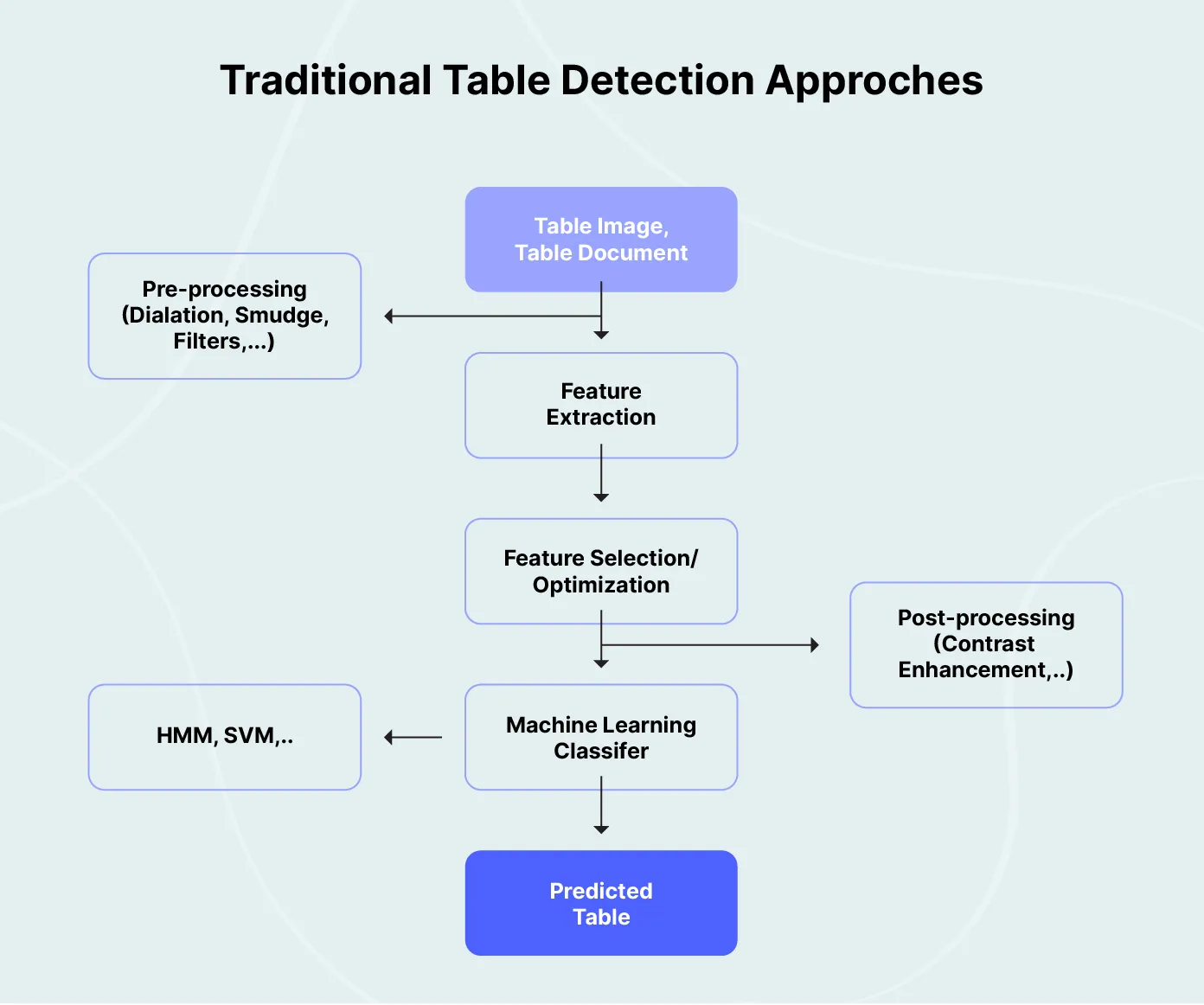
1. Rule-based table extraction
Table detection
The layout and content analysis of documents are used to detect tables. They employ different visual cues like lines, space features, etc. to detect tables. Usually, a combination of OCR text and visual cues is used for table detection. There are multiple techniques within rule-based approaches.
Let’s look at one of the techniques below:
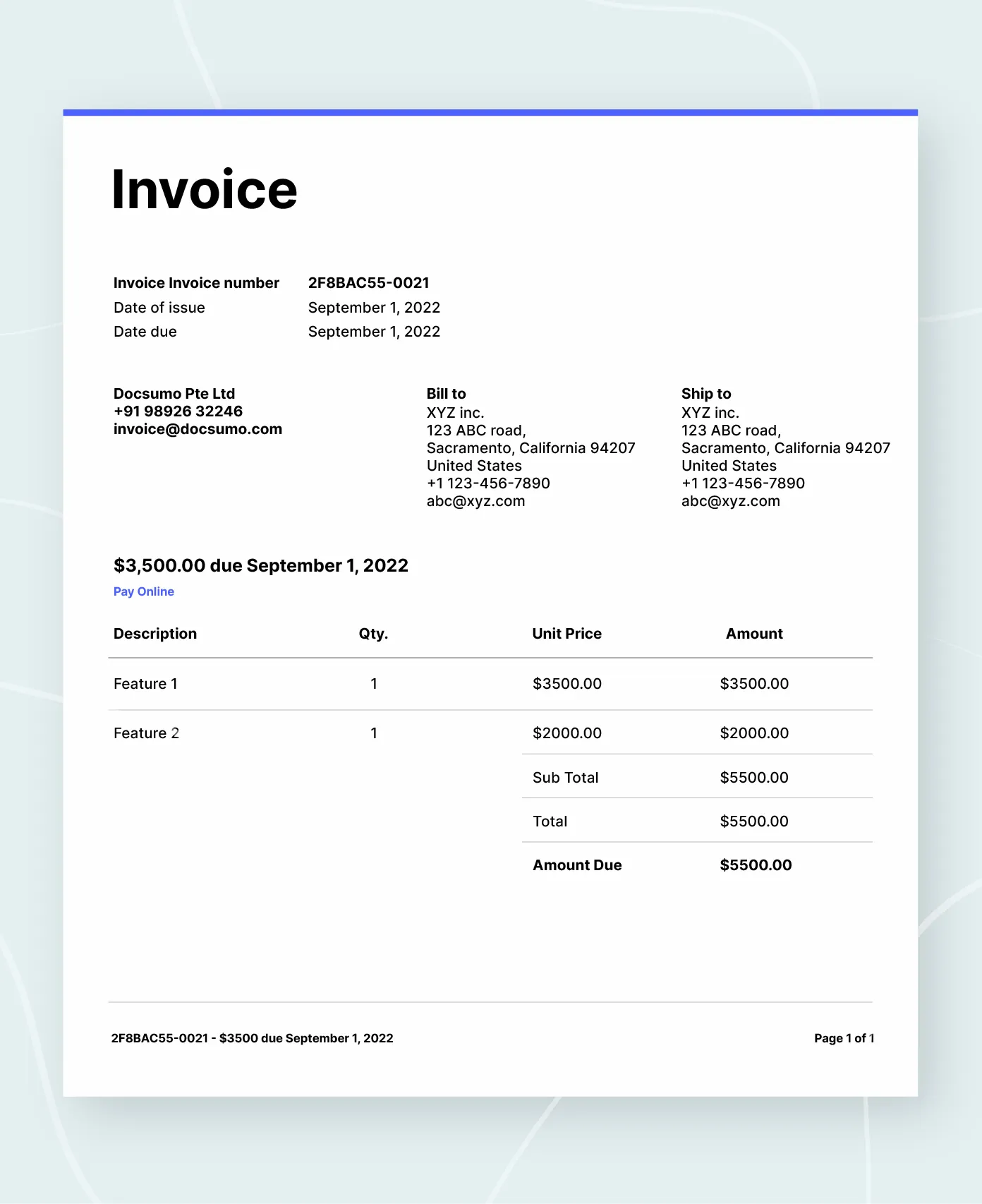
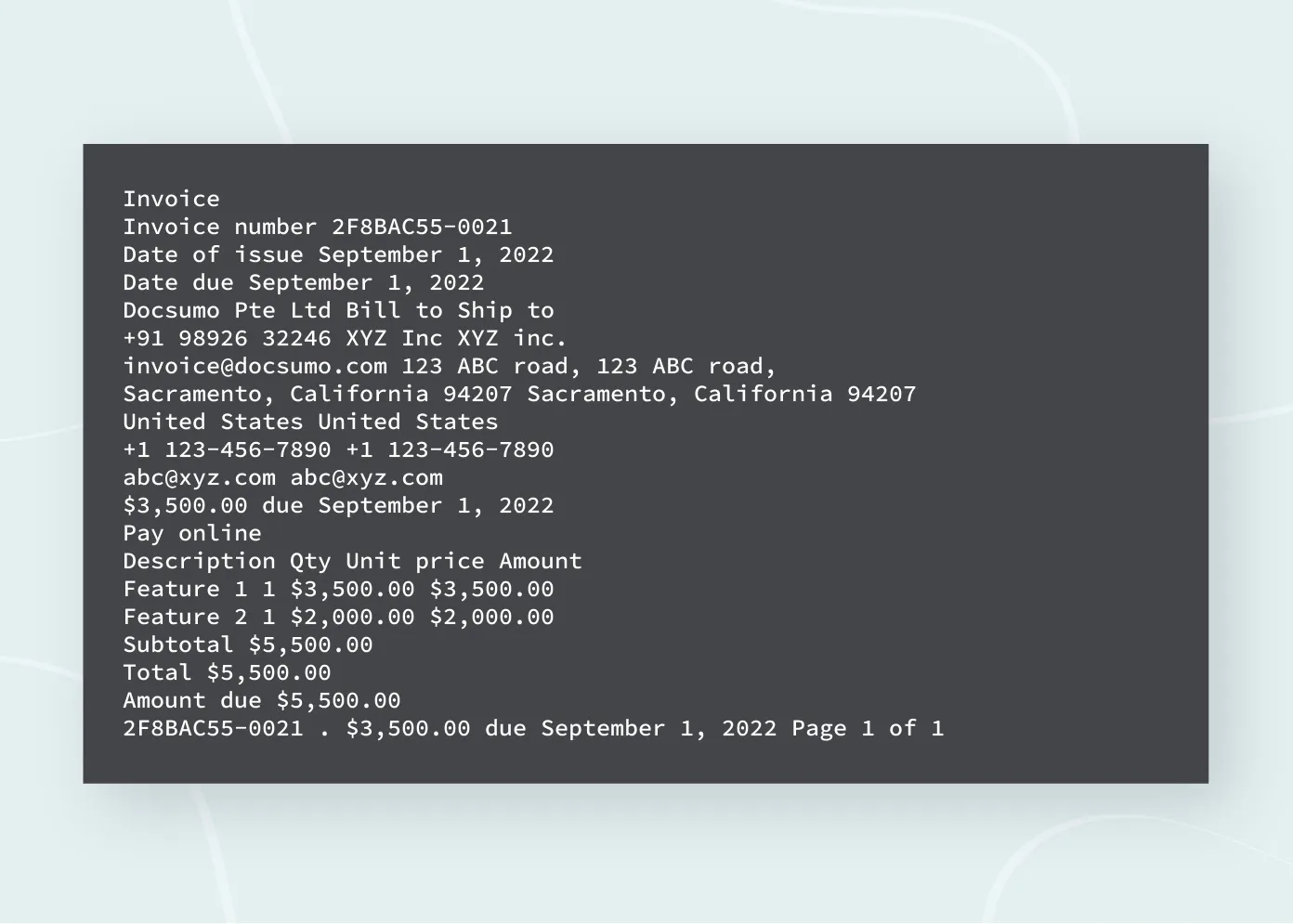
Step 1 - OCR
Apply the OCR engine to extract text and bounding box information from the above image. Convert it into the line-like format shown below:
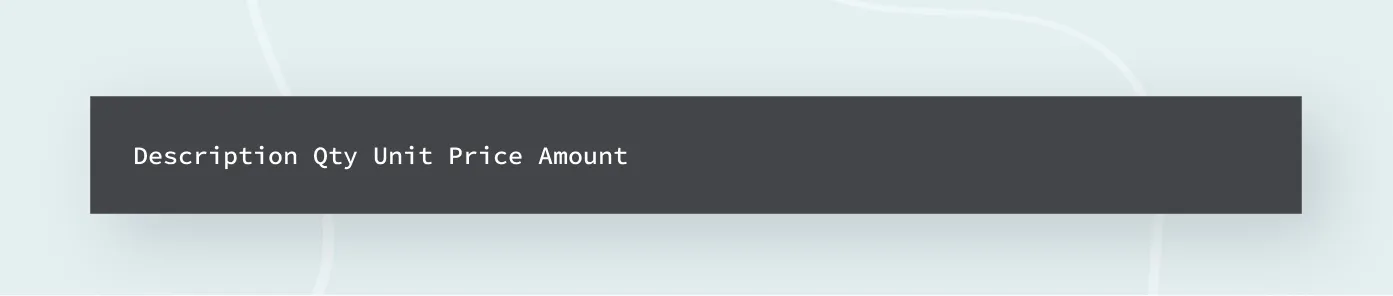
Step 2 - Detect header line
The table header line consists of column names that have a pattern and provide a unique table start. As seen in the figure, the header line has words description, qty, unit price, and the amount which are common across multiple invoice documents. Writing a rule-based pattern using regex will help you extract the header line.
Step 3- Detect table line items
The table line items also have a pattern ending with $X,XXX.XX which helps us filter them. But the subtotal and amount also have that. So, an additional filter for ignoring lines with those words will help you extract line items from the table.
Step 4: Bounding box
Get the bounding box based on the bounding box of the filtered header line and table line items. The bounding box is highlighted in red color below:
Table structure recognition
Intersections of horizontal and vertical lines are computed to recognize table formations.
The Hough transform is a prominent approach in computer vision that aids in detecting lines in document scans. Length, rotation, and average darkness of a line are utilized to filter out false positives and determine if the line is, in fact, a table line. The intersections of the remaining horizontal and vertical lines are computed after the Hough lines have been filtered. Table cells are created based on the crossings.
Summary
Tables come in several layouts and formats. As a result, creating a rule-based generic method for table detection and table structure recognition takes a lot of work which is not worth it as the rules need to be maintained manually. Therefore, machine learning approaches started to be employed to solve the table extraction problem.
2. Machine learning-based table extraction
Machine learning-based table extraction involves using a combination of supervised and unsupervised learning techniques to train the model to recognize tables in different layouts and formats. There are multiple approaches to building models for both table detection and table structure recognition. Let’s look at one of the approaches for both:
Table detection
The method includes three main steps for table detection:-
i) Feature extraction
In this process, a set of features are identified to describe the visual characteristics of the document image. These features include
Texture-based features: Extracted using Gabor filters.
Region-based features: Extracted using a set of statistical measures such as mean, variance, and skewness of pixel intensities within the image regions.
ii) Classifier training
In this step, a modified version of the XY tree algorithm is used to train a decision tree classifier. The classifier is trained on features extracted from the annotated images containing both table and non-table regions.
iii) Table detection
Finally, in the table detection step, the trained classifier is applied to the features of test images to detect the presence of tables. The classifier output is thresholded to generate a binary mask indicating the table regions in the image.
Overall, the proposed method achieves good performance in detecting tables in document images with different layouts and formats.
Table structure recognition
The method also uses a decision tree for structure recognition. In this method, features from table regions using a combination of structural and content-based features are extracted.
The structural features include:-
i) The number of rows and columns,
ii) The distance between adjacent cells, and
iii) The vertical and horizontal alignment of cell boundaries.
The content-based features include:-
i) The density of text in each cell,
ii) The presence of horizontal and vertical lines, and
iii) The presence of certain characters and symbols.
These features are used to train a decision tree classifier, which is able to recognize the structure of a table by examining the features of its constituent cells. The model is evaluated on a dataset of scanned documents, achieving an F1 score of 87.6% for table detection and 87.3% for table structure recognition.
Overall, this method demonstrates the effectiveness of decision tree classifiers for table structure recognition and highlights the importance of both structural and content-based features in the recognition process.
Summary
Machine learning-based methods give higher accuracy than rule-based methods on varied datasets. However, The performance is not great and feature engineering can be more complicated for varied datasets. Therefore, deep learning approaches started to be employed to solve the table extraction problem.
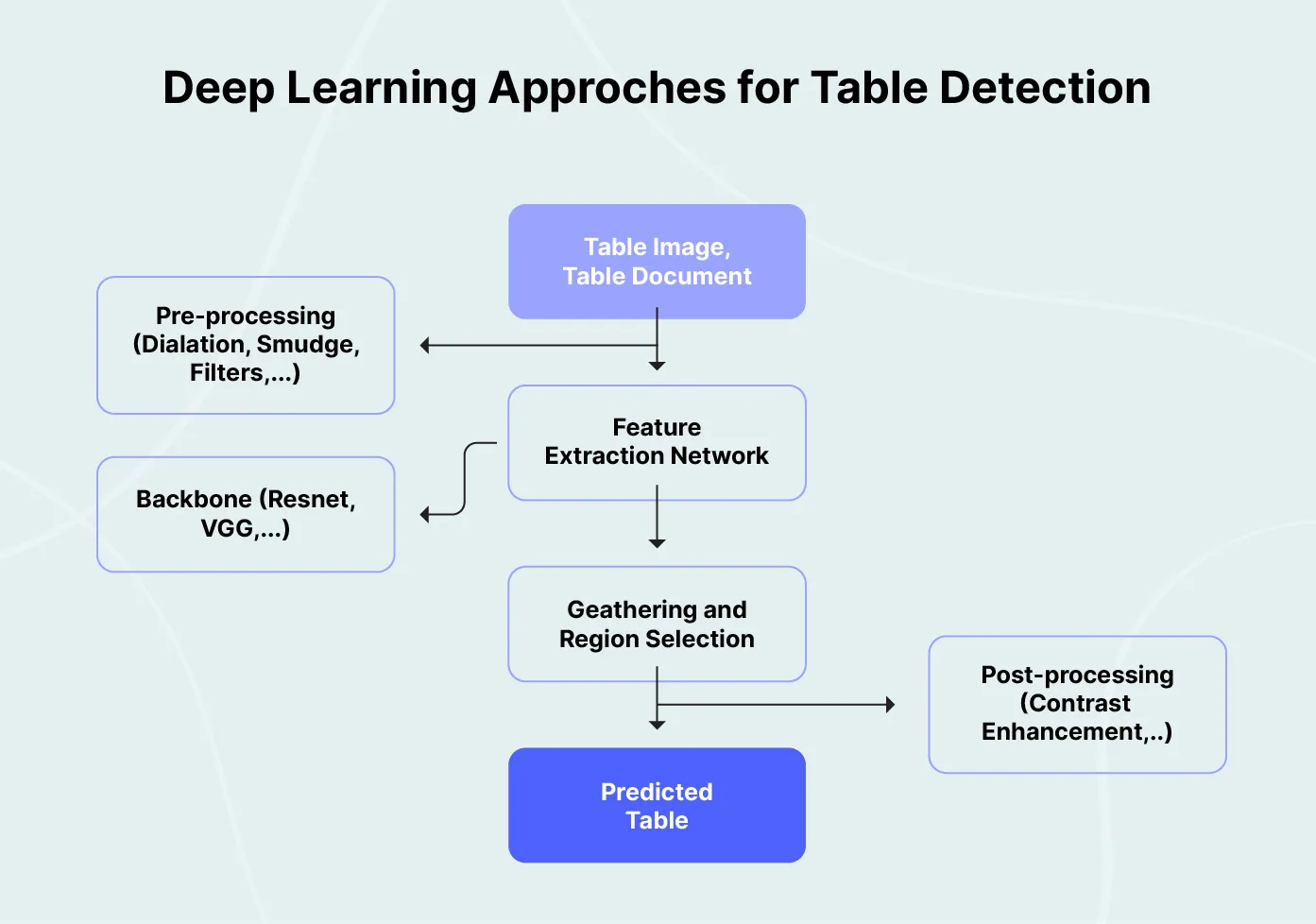
3. Deep learning-based table extraction
Unlike machine learning algorithms requiring manually created features, Deep learning algorithms retrieve features using neural networks, primarily convolutional neural networks. Object detection or image segmentation networks then tries to differentiate the tabular portion that is further broken down and recognized in a document image.
Deep learning has been used to build an automatic table information extraction method that involves two subtasks of table detection and table structure recognition. Let’s look at the CascadeTabNet released in 2020 has State of the art results on many benchmark datasets.
CascadeTabNet is an approach for end-to-end table detection and structure recognition from image-based documents. It uses a combination of deep learning techniques and ensemble methods to achieve high accuracy and robustness in detecting and recognizing tables of various sizes and styles.
The architecture of CascadeTabNet is based on a cascade of detection and recognition modules, each of which is trained to perform a specific task in the overall process.
i) The first module is a fast and lightweight object detector based on the RetinaNet architecture. It is used to locate potential table regions in the input image.
ii) The second module is a refinement network that takes the output of the object detector as input and further refines the table region proposals.
iii) The third module is a table recognition network that takes the refined table regions as input and performs the task of table structure recognition.
Here is a visual representation of the CascadeTabNet architecture:
As shown in the diagram, the input image is passed through the object detector, which generates a set of bounding boxes around potential table regions. These bounding boxes are refined by the refinement network, which helps to eliminate false positives and improve the accuracy of the table region proposals. Finally, the refined table regions are passed to the table recognition network, which performs the task of table structure recognition.
The table recognition network is based on a deep neural network architecture called TabNet, which is specifically designed for the task of table structure recognition. TabNet uses a combination of convolutional and recurrent neural networks to extract features from the input table regions and perform a sequence-to-sequence prediction of the table structure. The output of the network is a set of predicted cells, which can be used to reconstruct the table structure.
Here is an example of table detection and structure recognition using CascadeTabNet:
CascadeTabNet Bordered Table Detection
CascadeTabNet Borderless Table Detection
As shown in the image, CascadeTabNet can accurately detect and recognize tables of various sizes and styles, even in complex documents with multiple columns and rows. The output of the model includes both the bounding boxes around the table regions and the predicted table structure, which can be used for downstream tasks such as table analysis and data extraction.
Summary
In summary, Deep Learning is an effective approach for end-to-end table detection and structure recognition from documents because of the high accuracy in complex and varied table structures. Also, its modular architecture and use of ensemble methods make it highly accurate and robust, even in challenging scenarios.
Comparison between different table extraction techniques
Architecture diagram of Machine Learning
Architecture diagram of Deep Learning Approach for Table Detection
While convolutional networks are used in deep learning techniques, classical approaches primarily perform feature extraction through image processing techniques. Deep learning methods for interpreting tables are more generalizable and independent of data than conventional approaches. The below table provides an additional comparison:
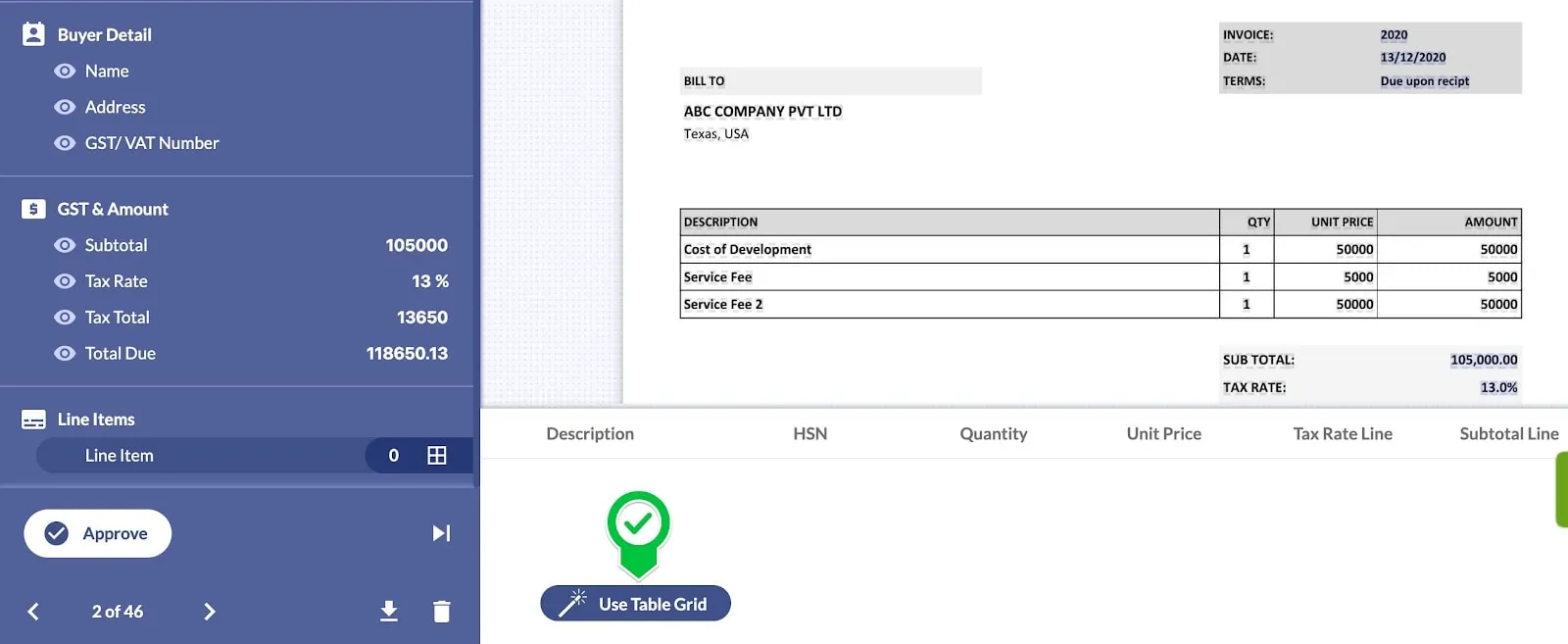
The output of table extraction alone is not sufficient to get the desired table output. Most of the time, a wrapper on top of a table extractor is needed to further post-process the output.
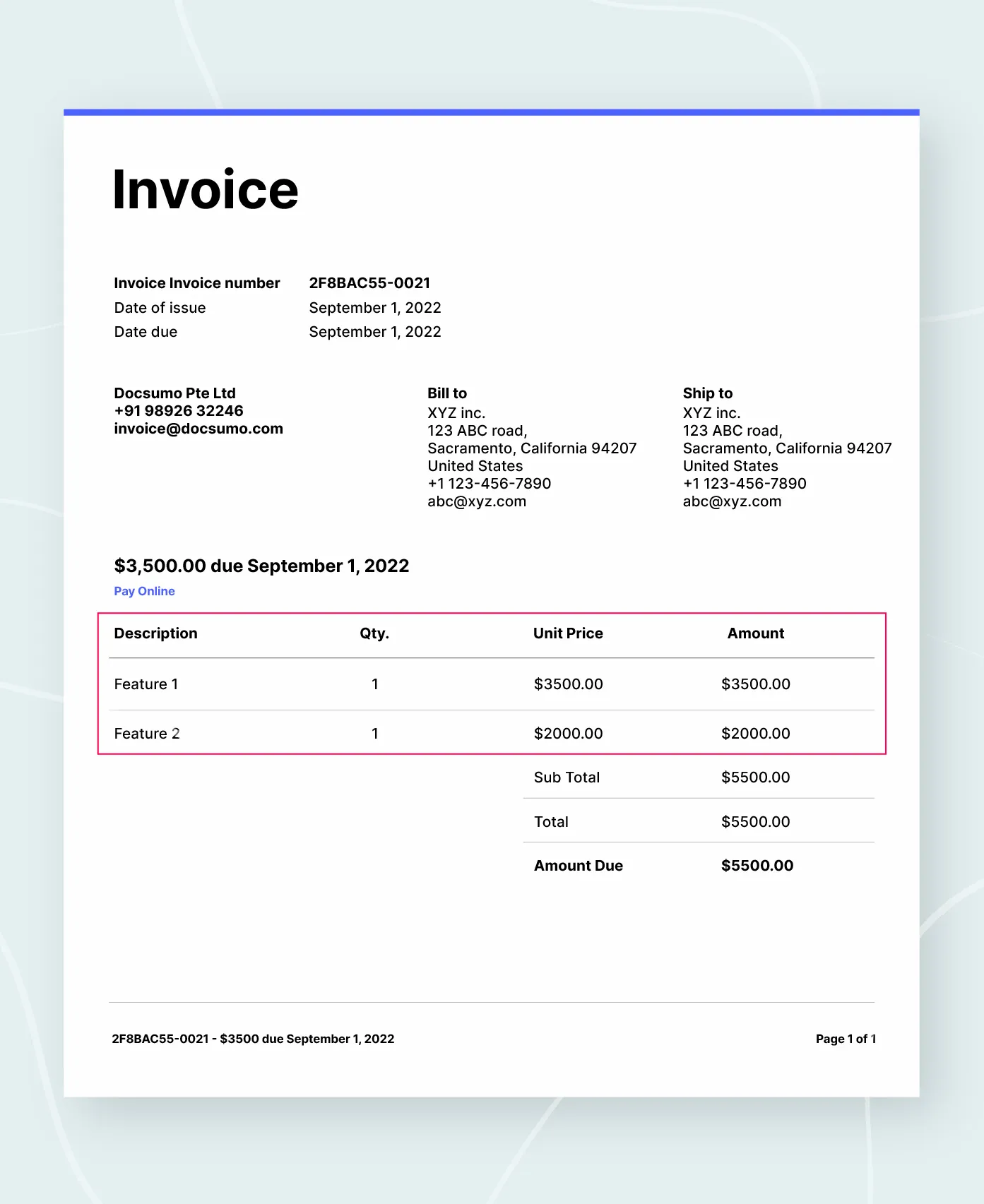
Let’s say we have an invoice document that contains two tables:-
i) A summary table
ii) Line-item table.
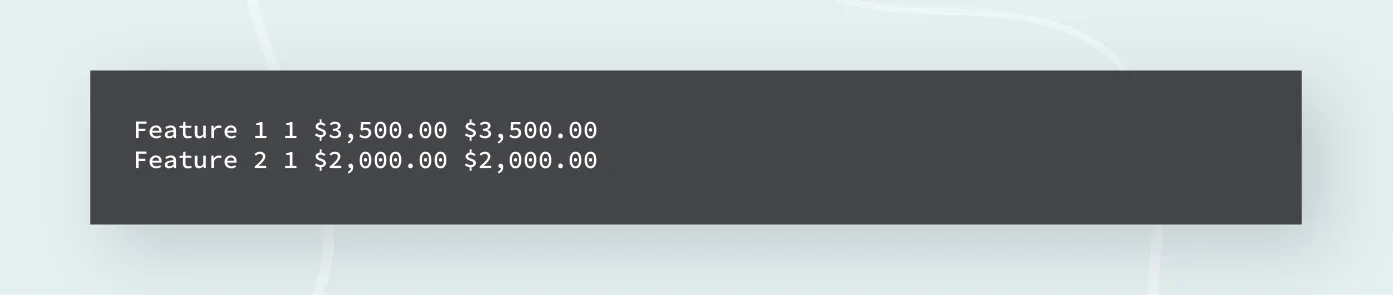
The intelligent table extractor filters the line-item table. Further, the rows that are not line items (eg. Total) are cleaned in the processed output as shown in the image.
Not only filtering tables and line items, merging multiple headers, header mapping, row post-processing, and merging multi-page tables are some other features of Intelligent Table Extractor.
Use cases of table extraction
Table extraction is useful for businesses in many industries, including lending, insurance, commercial real estate (CRE), and logistics. Some examples of how table extraction is used in these industries include:
The extracted data from tables are used to determine the creditworthiness of a borrower (credit reports), calculate loan amounts and interest rates (loan applications), and identify default risks (loan repayment schedules).
The extracted data from tables are used to determine policy premiums (policy documents), calculate claims amounts (claims form), and identify fraud (claims forms, medical reports).
The extracted data from tables are used to analyze property values (property appraisal reports), Portfolio analysis (financial statements, rent rolls), and Due diligence (property inspection reports, title reports).
The extracted data from tables are used to track inventory levels (inventory lists), optimize supply chain management (shipment manifests, bills of lading), and Order processing (purchase orders, order forms)
What sets Docsumo apart from the rest in extracting tables from pdf documents?
1. Accuracy
In the case of a 500-character page, although an OCR engine might have 99 percent accuracy at the page level, what if the 1 percent erroneous characters are within 5 of the 10 data fields required by the business? Suddenly, this 99 percent accuracy drops to 50 percent accuracy. This is where field-level accuracy comes into play, using what's known as the field-level confidence score.
We have developed algorithms based on Deep Neural Networks and Computer Vision Techniques claiming a field-level accuracy of more than 95 percent for any kind of form. We make use of additional knowledge regarding the language and the context used in a text.
2. Accessibility
Docsumo is user friendly, and it does not require you to be an expert in the field. It predetermines the field category (date, address, etc) and suggests you the key. It not only allows you to edit the partially correct fields but also helps you to map the fields stored in the database. Docsumo comes with an amazing edit and review tool, which makes it very easy to specify the fields that you want to capture.
3. Adaptability
Unlike other products in the market for document processing, Docsumo is template independent. It can extract information from unstructured documents as well. You just need to provide a sample of your documents and the platform is smart enough to apply the same to the rest of your documents.
4. Data Validation
The data in the tables may be present in the invalid format such as invalid date, PAN number, Aadhar number, amount (negative amount), characters and fonts, etc. It provides you suggestions/alerts to correct those fields. It can also be used as prior information for any fraud.
5. Analytics
Docsumo helps you to convert the data from various documents into tables which can further be used in analytics to get insights.
Data analytics is important because it helps businesses optimize their performances. Implementing it into the business model means companies can help reduce costs by identifying more efficient ways of doing business and by storing large amounts of data. A company can also use data analytics to make better business decisions and analyze customer trends and satisfaction, which can lead to new—and better—products and services.
Using AI and Machine Learning, we have developed a system that is intelligent enough to categorize text into more than 80 different labels that include salary, loan, interest, shopping, sell, etc. It provides the user the ability to segregate the data into different fields which can be further used for data analysis.
6. Fraud Detection
In the 21st century, due to the advancement of technology, it is relatively easy to commit fraud, and the major part of these frauds belongs to digital transactions. The insurance companies and banks incur huge losses every year due to fraudulent documents. Some of the most common methods implemented by insurers to tackle the menace are by Investigating and cross-checking the documents to detect frauds, perform deep data analytics and statistical analysis.
How can Docsumo impact various Industries
Docsumo has been a gamechanger for several organizations belonging to numerous sectors by pioneering a basic function - to capture data from any PDF or scanned document. Using intelligent OCR and Artificial Intelligence.
Docsumo decreases the odds of mistakes by 95%. From bank statements to patient records, Docsumo helps in easy extraction of information with high precision in numbers. Alongside this, organizations get an opportunity to work with insights that play an integral role for understanding the current scenario and drafting future plans. There are several parameters for different documents in different sectors.
For example - Banks are more likely to deal with credit card numbers whereas billing will require accurate numbering of transactions made. In order to facilitate this, the data validation function notifies to correct the format and it likewise helps in fraud detections.
We have proudly served the following sectors till date:
Banking and Finance Sector:
Insurance
Healthcare
Education
Government and BPOs
Transportation and logistics
To sum up, Docsumo is your go-to tool for table extraction from PDF, independent of any sector you belong to. Automating document workflow by seamlessly integrating Docsumo in your processes helps in sparring a great deal of human effort. Also, it is efficient and effective.
Check out Docsumo's free table extractor tool and see for yourself. No signup, no credit card required. Do connect with us to know more and we ensure to tailor our product to meet your needs.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.




.webp)