
Suggested
An in-depth Guide to Automated Invoice Scanning Software
Automated Invoice Processing, a key back-office task that can lead to a great deal of time & cost savings if automated correctly.

PDF extraction is the process of extracting text, images, or other data from a PDF file. In this article, we explore the current methods of PDF data extraction, their limitations, and how GPT-4 can be used to perform question-answering tasks for PDF extraction. We also provide a step-by-step guide for implementing GPT-4 for PDF data extraction.
In this article, we discuss:-
- What are the current methods of PDF data extraction and their limitations?
- How to use GPT-4 to query a set of PDF files and find answers to any questions. Specifically, we'll explore the process of PDF extraction and how it can be used in conjunction with GPT-4 to perform question-answering tasks.
So, let's jump right into it:-
PDF data extraction is the process of extracting text, images, or other data from a PDF (Portable Document Format) file. These files are widely used for sharing and storing documents, but their content is not always easily accessible.
Accessibility and readability of PDF files are very necessary for those who have vision issues or have trouble reading small or blurred text, useful for legal situations, data analysis, and research. Some instances where extraction is required include using text or image content from PDF files in other documents to save time and avoid mistakes.
It’s 2023, and there are a lot of PDF Extraction techniques and tools available on the internet. Let’s dive deeper into the 3 popular techniques of data extraction and some examples for the same :
OCR or abbreviation for `Optical Character Recognition` can be used to extract text from a variety of sources, including scanned documents, images, and PDF files, and is commonly used to digitize printed documents such as books, newspapers, and historical documents.
Some of the popular OCR tools includes:
Template-based techniques take into consideration the style of the document PDF and use hard-coded rules. These techniques generally work on structured documents, whose structure remains constant and are easy to understand.
Some of the popular template-based techniques include:
Using regex pattern
Ex: date can be extracted by the following regex rule:
[dd-mm-yyyy or yyyy-mm-dd] - [0-9]{2,4}/[0-9]{2}/[0-9]{2,4}
Hard-Coding rules based on the position of texts and dimensions of the documents
Machine Learning (ML) techniques are considered one of the best methods for PDF extraction because it allows for highly accurate text recognition and extraction from PDF files regardless of the file structure. These models can store information of both the `layout` and the `position of the text` keeping in mind the neighboring text too. This helps them to generalize better and learn document structure more efficiently.
Large Language Models are a subset of artificial intelligence that has been trained on vast quantities of text data. Large language models (LLMs) are a subset of artificial intelligence that has been trained on vast quantities of text data. For example : ChatGPT which is trained on the whole internet data and information to produce human-like responses to dialogue or other natural language inputs.
In order to produce these natural language responses, LLMs make use of deep learning models, which use multi-layered neural networks to process, analyze, and make predictions with complex data.
Some popular ML models include:
One major issue that this type of model faces is that they can just extract out the information from the PDF without knowing whether the extraction is actually accurate and correct. The extracted texts might also include some other keys information in another key. Having a intelligent context helps the model to mitigate those inaccuracies.
To solve this problem and integrate intelligence into the system of PDF extraction we can leverage the power of GPT-4.
GPT-4 and GPT 4 with vision (Generative Pre-trained Transformer 4) is a large language model developed by OpenAI that uses deep learning techniques to generate human-like natural language text. It is one of the largest and most powerful language models available, with 175 billion parameters.
Chat-GPT, on the other hand, is a variant of GPT that has been specifically trained for conversational AI applications. It has been fine-tuned on a large dataset of conversational data and can generate human-like responses to user queries. Chat GPT can be used for a variety of applications, including chatbots, customer service, and virtual assistants.
Let’s move forward with the problem statement and look into how can GPT-4 along with ChatGPT helps us to solve the problem of PDF extraction
The challenge of efficiently extracting specific information from a collection of PDFs is one that many applications and industries encounter regularly. Extracting information from bank statements or tax forms are tough. The old-fashioned way of manually scanning through numerous PDFs takes a lot of time and can produce inaccurate or inconsistent data. Moreover, unstructured data found in PDFs makes it challenging for automated systems to extract the necessary information.
We intend to solve the problem of finding the answer to user’s questions from the PDF with little manual intervention.
We can use the GPT-4 and its embeddings to our advantage:-
1. Generate document embeddings as well as embeddings for user queries.
2. Identify the document that is the closest to the user's query and may contain the answers using any similarity method (for example, cosine score), and then,
3. Feed the document and the user's query to GPT-4 to discover the precise answer by turning PDF into chatbot.
A: Extract text from the PDF
You can use any of the OCR or ML techniques to extract text from the document
B: Split the text into proper smaller chunks based on structure of the document
Using the coordinate information of Bounding-Box [x0, y0, x2, y2] where x0 and y0 are the top-left coordinates and x2 and y2 are the bottom-right coordinates, you can break the entire text into smaller chunks of certain width and height.
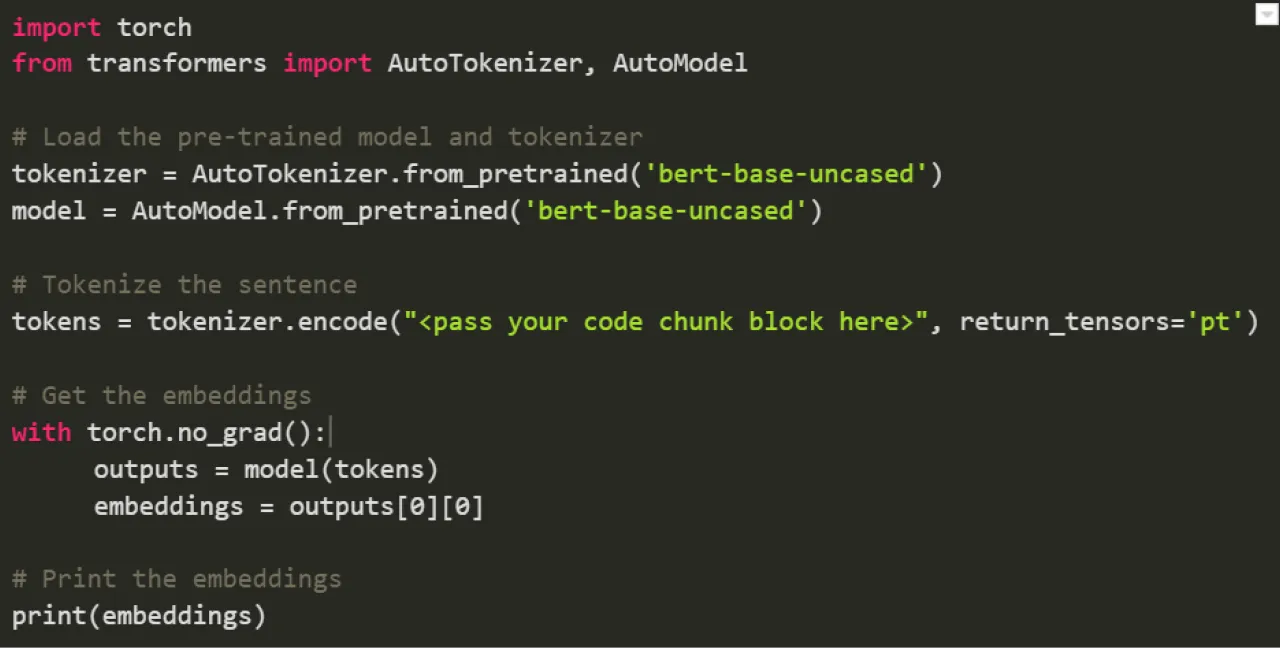
C: Encode those chunks into Embeddings [ either use OpenAI Embeddings or HuggingFace ]
What is a Vector DB and why is it necessary?
- Vector databases are purpose-built DB to handle the unique structure of vector embeddings. They index vectors for easy search and retrieval by comparing values and finding those that are most similar to one another. Examples include Pinecone and Weaviate.
- This V-DB contains vectors of each chunk snippets and document itself
A: Compute embeddings for user’s query
Use the same technique as mentioned above to compute the embeddings
B: Search chunk embedding vector from the vector database whose embeddings closely match with user query’s embeddings
You could use any of the `similarity search algorithm`.
You could use Semantic Sentence Similarity of sentence transformer library

A: Provide 3 inputs.
Input1 : User query
Input2 : The chunk which closely resembled the query
Input3 : Some Meta-Instructions if any [ System : Answer questions solely based on the information provided in the document ]
B: GPT-4 output’s the answer
.webp)
As we already know since GPT4 is such a powerful LLM which can incorporate a large amount of context with token length of 8,192 and 32,768 tokens, producing very accurate results becomes easier and very fast.
The ChatGPT API seamlessly integrates with any of the programming language which can help us more in the downstream tasks
- We learnt about the different PDF and data extraction techniques and tools
- What are the limitations of these kinds of modules and models
- What and how is ChatGPT and GPT-4 helpful in our use case and how they can be used to solve data extraction from PDFs
