A Beginner’s Guide to OCR APIs (+10 Best OCR APIs in 2025)
Discover the ten best OCR APIs for organizations in 2025. Learn about key features, pros, cons, and pricing for top solutions like Docsumo.


OCR technology helps organizations reduce manual data entry and operational costs, enhance work management, and improve customer service, leading to massive adoption and implementation of these tools.
Despite their numerous advantages and use cases, OCR APIs pose specific business challenges, such as security, accuracy, and formatting issues. Also, it can be difficult for data teams to research the best OCR solutions in the market, review them individually, and finalize the best one.
The global Optical Character Recognition (OCR) market, valued at USD 12.56 billion in 2023, is expected to grow at a CAGR of 14.8% from 2023 to 2030. This article will discuss OCR APIs, their limitations, applications, and use cases.
What is OCR API?
Optical Character Recognition (OCR) technology analyzes printed documents, scanned images, and PDFs, recognizes texts, and converts them into editable and searchable data. OCR APIs simplify this process by providing a powerful interface that allows users to incorporate OCR into business workflows easily.
Optical Character Recognition (OCR) API helps you transcribe text from image files and PDF documents and receive the extracted data in JSON/CSV/Excel or other file formats. OCR scans images of documents, invoices, and receipts, recognizes and extracts text from them, and transcribes it into a format for machines to interpret.
OCR APIs are built on OCR technology, but what differentiates them is that they are trained to extract data from specific documents, which is why they are more accurate.
How does it Work?
OCR APIs scan and analyze the framework of document images and breaks down the page into blocks of tables or text lines. These lines are then subdivided into words and eventually into characters.
Once the OCR tool singles out individual characters, it analyzes them against a set of pattern images. The program then formulates a series of hypotheses to figure out the nature of the symbol.
Limitations of OCR APIs
Organizations use OCR APIs to eliminate manual data entry and its associated errors. However, traditional OCR software has several limitations, as it was initially designed to extract data from black-and-white documents.

Let's understand the challenges in detail by dividing them into product shortcomings and technology limitations.
Product shortcomings
Here are some aspects where OCR as a product falls short, leading to accuracy issues and inefficiencies:
1. Incompetency with working on custom data
OCR requires unique algorithms to handle different types of data. OCRs are untrainable if the text displayed is in a format other than horizontal text. For instance, the current API OCR cannot read vertical characters, making the detection task tedious and inconvenient.
2. Substantial requirement for post-processing
If you wish to use the text extracted from a scanned invoice, you have to design the parsing rules for the OCR software that allows you to extract dates, sum amounts, product details, and other information.
This step implies that you require an in-house developers team to use existing OCR APIs and build software for intelligent data structuring.
3. Satisfactory results only in specific constraints
Current web OCR API methods yield satisfactory results on scanned documents that contain digital text. However, handwritten documents that contain multiple languages, low-resolution images, and other non-ideal scenarios can cause your OCR model to display errored results and render low accuracy.
Check out how Valtatech drives 3x faster data extraction from 20k+ invoices monthly
Technological limitations
An increase in documents with formatting issues, blur, different layouts, and complex tables leads to technological limitations, which standalone OCR software cannot overcome. Here are some of the challenges:
1. Tilted text in scanned documents
OCR tools find it difficult to detect objects. Because of this, an OCR model cannot recognize tilted characters and words. Under such cases, the text appears tilted and cannot be considered acceptable for automation.
2. Natural scenes
OCR models fall short when extracting text from images shot in various settings. An OCR tool finds the first character and traverses horizontally, searching for subsequent symbols.
However, if the image is blurry, the font is unrecognizable, or the text is tilted, OCR fails to yield satisfactory results.
3. Handwriting and varied fonts
The OCR annotation process identifies each character as a bounding box by spotting the gaps between words that remain absent in handwritten text or cursive fonts. Without these gaps, the OCR model acknowledges that all the characters are a single pattern and do not fit into any character descriptions.
4. Multi-language text recognition
Most OCR models work satisfactorily for English but need to be more competent for other languages. This incompetency occurs because there is insufficient training data or syntactical rules for various languages.
You must rely on something other than OCR when analyzing documents that contain multiple languages, such as forms, to deal with government processes.
5. Blurry scanned documents
Document OCR API models often generate wrong results when dealing with noisy images. Your OCR model can get baffled between ‘8’ and ‘B’ or ‘A’ and ‘4’. The only way to tackle noisy images is to implement Deep Learning in your OCR solution or use de-noising image processing tools.
6. Accuracy Issues
OCR APIs depend on the quality of source documents to extract data with a high accuracy rate. Factors such as handwritten, distorted, minuscule, skewed texts, noises, intricate layouts, low-quality images, and blur impact accuracy and contribute to errors and inconsistencies.
7. Language Support
OCR APIs that support only a limited number of languages extract incorrect data when faced with a new language. Another serious challenge is the lack of advanced machine learning models in simple OCR solutions, which makes extracting text in global languages difficult.
8. Formatting Preservation
A simple OCR solution may not preserve the document’s formatting, including the original composition of the table and key-value pairs. It requires help from third-party software solutions to process and preserve graphs and tables.
This leads to misaligned texts, incorrect line breaks, and incomprehensible tables, requiring human effort to align formatting; this decreases productivity and efficiency.
9. Contextual Understanding
Simple OCR solutions that lack advanced technologies, such as ML and NLP algorithms, need help understanding the context, nuances, and relationships between the extracted text.
They are limited to text recognition and digitization, leading to errors when extracting data based on the context.
10. Security Concerns
Basic PDF OCR API software solutions that don't follow security protocols might expose sensitive information such as bank account numbers, social security numbers, financial data, and IDs to the software provider’s server.
Cybercriminals can easily access this data, resulting in security breaches and penalties.
5 OCR APIs Industry-wise Use-cases
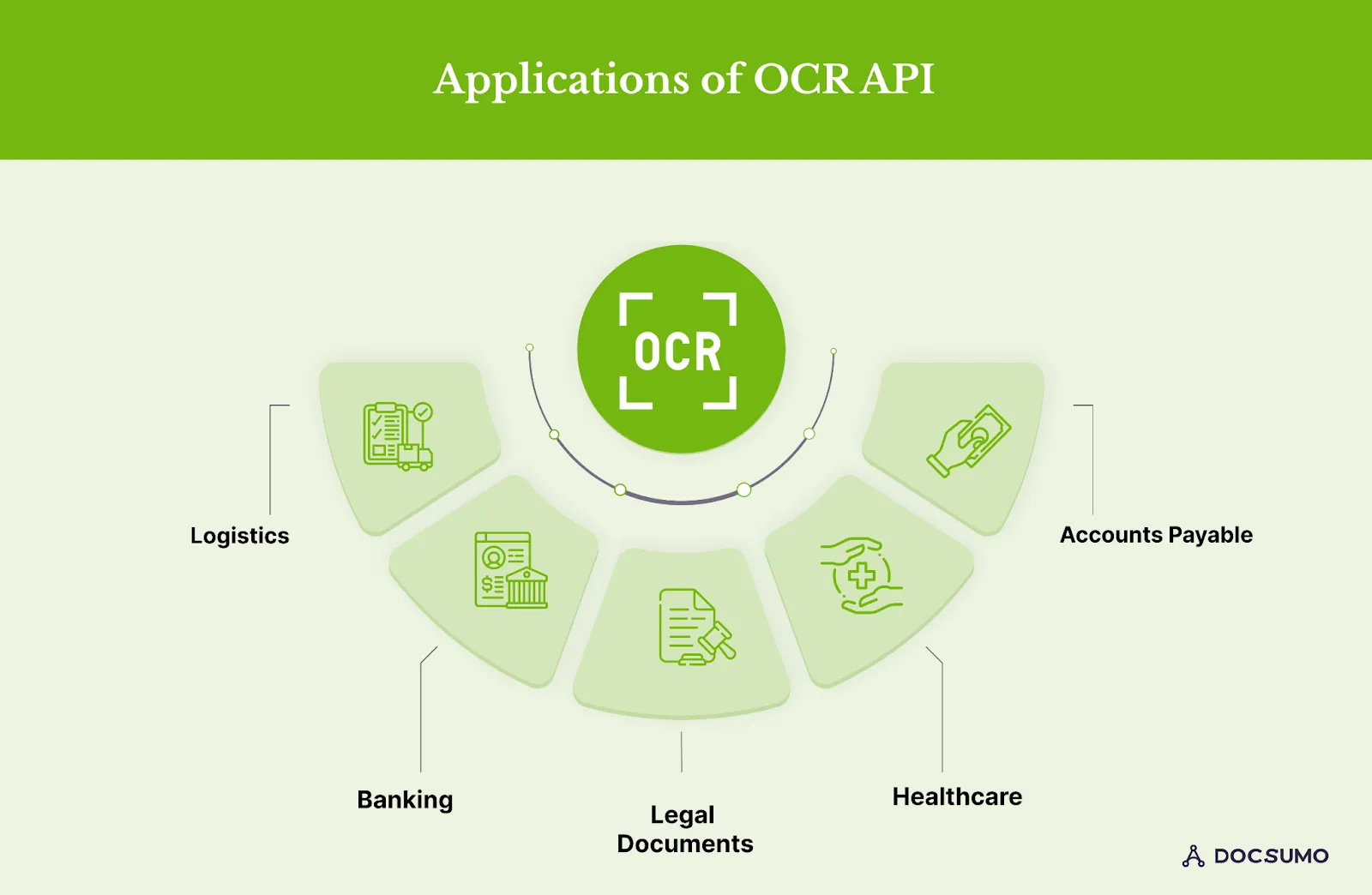
Let's now explore the use cases of OCR APIs across diverse industries and see how they convert images and documents into editable text:
1. Logistics
According to Flexport's 2023 Logistics Trends Report, 74% of global supply chain leaders expect to increase their investment in supply chain innovation and technology. They also believe automation, artificial intelligence (AI), and data insights will drive supply chain efficiency in the coming years.
OCR API can extract data from bills of lading, shipping labels, delivery notes, invoices, and purchase orders in real time. It lets you extract key-value pairs, validate tax rates and amounts, and reduce back-office costs by up to 50%.
Besides accurately recognizing text and converting unstructured documents into structured types, OCR APIs help:
- Streamline communications between vendors, suppliers, and buyers
- Eliminate re-corrections involved with entering incorrect amounts through smart validations
- optimize operations by sending electronic invoices over email and getting faster order confirmations
2. Legal documents
OCR APIs transcribe different forms of documents, such as affidavits, judgments, and filings, which can ease information browsing. Legal firms and attorneys benefit from OCR technology in the following ways:
- Save case files in electronic formats, thus reducing the need for paper-based document storage
- Convert and process legal documents in different languages based on client requirements
- Ensure the safety, integrity, and privacy of legal papers with robust encryption
3. Banking
According to Deloitte's 2023 Human Capital Trends Report, 96% of surveyed financial executives report using technology to improve work outcomes and team performance.
OCR technology for banking and financial businesses can process data from cheques, passbooks, bank statements, and KYC documents. Banks use OCR APIs to:
- Process financial statements, authenticate transactions, and verify account standings
- Verify account numbers, transaction details, identity, and tax details quickly and reduce the turnaround time
- Automate Loan origination and administrative tasks by combining OCR APIs with AI and machine learning for processing customer applications
4. Healthcare
Hakkoda’s State of Healthcare Data report shows that 51% of healthcare organizations want to modernize their data stack in 2024. OCR API can be used in healthcare to:
- Transcribe patient’s medical records, history of illnesses, and medication.
- Scan prescription slips, lab notebooks, and clinical trial data and convert them into digital formats for safe patient record-keeping and streamlining patient onboarding processes
- Educate patients on their rights, safety concerns, and medical treatment options by scraping, extracting, sorting, and organizing appropriate medical data
- Ensure legal compliance when it comes to maintaining medical documentation systems and workflows in hospitals and healthcare institutions
5. Accounts Payable
According to IFOL and SAP Concur’s Accounts Payable Automation Trends Report 2023,
- Over half of AP teams (56%) spend more than ten hours a week processing invoices
- 82% of AP teams manually key invoices into an ERP/accounting software
PDF OCR API overcome challenges in the Accounts Payables department by:
- Automating analyzing bills, invoices, and receipts, and extracting products, prices, and company names in the retail and logistics sector.
- Recognize different invoice layouts and extract essential fields with 95% accuracy.
- Help businesses that want to keep stock of inventory and issue pre-orders by scanning invoices, optimizing budgets, and performing cash flow analysis based on financial statements.
- Assist companies in deriving insights from data and lay the groundwork for providing a better customer experience by ensuring data accuracy and integrity.
10 Best OCR APIs in 2024
Here are the top 10 OCR APIs in 2024 with detailed descriptions, features, pros, cons, and pricing:
1. Docsumo

Docsumo’s intelligent OCR efficiently scans, analyzes, and extracts characters and texts from any document. It even processes difficult-to-read unstructured documents such as contracts, rent rolls, invoices, bank statements, bills of lading, tax reports, and ACORD forms.
Along with OCR technology, Docsumo also leverages Natural Language Processing (NLP), machine learning (ML), and deep learning algorithms to automate data extraction, understand context, and provide business insights with a high accuracy rate.
After extracting data, you can create and use Excel-like rules/formulae to validate the information across multiple documents and against databases. This way, Docsumo helps organizations achieve a greater than 95%+ accuracy rate.
a. Features
- Ingests documents automatically from computers, cloud drives, and emails using powerful image to text APIs.
- Preprocesses documents using deskewing, denoising, and binarization techniques to improve precision
- Extracts key-value pairs using feature detection and pattern recognition algorithms.
- Categories table line items to derive metrics required for business decisions
- Validates the extracted data to detect errors
- Integrates the data seamlessly with existing systems to analyze and make intelligent decisions
b. Pros
- Data recognition features are very convenient to use
- Cuts down the document processing time by 80-90%
- The customer support team is friendly and proactive in solving issues
- OCR API is straightforward to implement
- Provides integrations with many different platforms
c. Cons
- Lacks advanced reporting features
d. Pricing
- Growth - $500+/month
- Business - Custom pricing
- Enterprise - Custom pricing
2. Google Document AI

Google Document AI powers OCR technology with AI to offer capabilities beyond traditional text recognition in document processing. It understands, organizes, and enriches data to generate insights that can optimize business operations.
Google Cloud’s OCR solutions provide access to pre-trained ML models that businesses can start using immediately through an API. The platform also allows uptraining existing ML models or creating custom models according to specific business needs.
a. Features
- Extracts text in 200+ languages and 50 handwritten languages
- Classifies and splits documents using a custom classifier and document splitter
- Recognizes math formulas and styles with high accuracy
b. Pros
- Processes a wide range of document types with a high accuracy rate
- Supports many languages
- Integrates easily with other Google tools
c. Cons
- Doesn't offer flexible pricing options, and it is expensive for small businesses
- Navigating the platform and exploring features can be time-consuming
- Provides minimal features for organizing documents
d. Pricing
- Custom pricing
3. Amazon Textract

Amazon Textract is a machine learning-based OCR model that extracts text, handwritten and layout elements, and line items from scanned images, PDFs, and printed documents. The platform automatically adapts to varying font styles and templates and efficiently handles distorted and noisy texts.
It helps financial services, healthcare, life sciences, and the public sector securely automate text digitization with data privacy rules, encryption, and compliance standards.
Businesses can use pre-trained models to start recognizing texts or train the model with sample documents to customize the Queries feature and improve extraction accuracy for specific document types.
a. Features
- Preprocesses and classifies documents and recognizes texts
- Returns a confidence score for recognized texts to help decide how to use the results
- Extracts layout elements such as paragraphs, titles, lists, headers, and footers
- Detects signatures on documents such as checks, loan applications, and claims
b. Pros
- Ready to use and the OCR model requires no custom training
- Recognizes text from documents without extraction rules/templates
- Extracts data quickly and is easy to use
c. Cons
- Provides only a low accuracy rate for handwritten documents
- Supports only a limited number of documents
d. Pricing
- Custom pricing
4. IBM

IBM Document Processing uses OCR technology combined with NLP and deep learning algorithms to process documents and extract text from them. It first classifies the documents by their type to help machine learning models accurately recognize text irrespective of the document format.
NLP algorithms in IBM document processing read documents, analyze conversations, and extract relevant texts by understanding the context. Moreover, they automatically verify the extracted data, flag issues, and correct errors to avoid bottlenecks.
a. Features
- Classifies documents and sorts them to the proper workflows for processing
- Recognizes text from structured, semi-structured, and unstructured documents
- Detects and corrects errors in the extracted data
b. Pros
- Integration is simple and easy
- Automates the text recognition processes and reduces manual efforts
c. Cons
- Quite expensive
- Steep learning curve and require professional training before actual implementation
- Digitization of image text is not accurate
d. Pricing
- Custom pricing
5. HP

HP’s intelligent document scan software uses OCR technology to scan documents, capture characters, and convert them into editable texts. The platform allows users to edit text and clarify characters after completing the scan.
a. Features
- Scans any document and recognizes text from them
- Provides flexibility to modify settings
b. Pros
- Analyzes documents and converts them to searchable texts
c. Cons
- Has only basic and limited features
- Lacks features for table extraction, validation, and integration
d. Pricing
- Custom pricing
6. Adobe Acrobat OCR

Adobe Acrobat’s OCR tool scans documents, applies text recognition algorithms, and transforms static PDFs into editable texts. Copy and highlight any text in the document and search for phrases or words to locate critical information swiftly.
Businesses don't need additional software to install the OCR platform; they can use it in any browser, such as Microsoft Edge and Google Chrome. The platform follows security and privacy protocols, such as encryption, to secure PDFs when working with files online.
a. Features
- Process documents, recognize texts and make them editable, searchable, and selectable.
- Reproduces the font style of static texts throughout the document for consistency
b. Pros
- Exceptional security features such as digital signatures and password encryption
- Recognizes and converts text from documents quickly and easily
c. Cons
- Takes a very long time to load documents
- The free version has only the most basic features
- Compatibility issues with specific devices and operating systems
d. Pricing
- Acrobat Standard - USD 14.99/month
- Acrobat Pro - USD 23.99/month
- Acrobat Pro for teams 5-pack - USD 22.19/month
7. Wipro
Wipro’s intelligent OCR handles multi-format, handwritten, printed, structured, and unstructured documents, classify them, and extracts accurate data for storage and digitization processes. It provides a higher straight-through processing rate (STP), enhancing productivity and efficiency.
Moreover, it auto-tracks documents and uses interactive reports and dashboards to provide business insights and enhance transparency. Moreover, data operators don't need to create rules as the platform follows a template-less document processing approach to extract data.
a. Features
- Classifies documents according to the type and converts characters into editable texts.
- Routes documents smartly to the right stakeholders for approval
- Generates reports automatically regarding the number of documents processed and data extracted
b. Pros
- User-friendly and cost-effective
- Handles different formats with a high accuracy rate
- Routes documents to downstream systems
c. Cons
- Lacks proper validation features to detect errors and correct them
d. Pricing
- Custom pricing
8. Xerox

Xerox leverages OCR and AI technologies to automate data recognition from documents. The platform helps mitigate and overcome document processing challenges, allowing businesses to focus on strategic initiatives.
Its user-friendly and intuitive browser interface allows team members to efficiently collaborate and access information anytime and anywhere. The Digital Vault feature in Xerox OCR ensures data security with role-based access control and cloud storage capabilities.
Xerox machine learning algorithms learn from previous experience to extract accurate data and improve without the need for manual training.
a. Features
- Classifies and captures critical information from paper and digital documents
- Automates records management to protect sensitive data and maintain regulatory compliance
- Integrates editable data with existing business workflows
b. Pros
- Rapid deployment and smooth implementation process
- Enhances customer experiences by empowering teams with the correct information
c. Cons
- It lacks features to route documents and doesn't provide any reporting
. d. Pricing
- Custom pricing
9. Tesseract

Tesseract is an open-source OCR engine that extracts printed and handwritten text from images, PDFs, and other documents using pattern recognition algorithms.
The tool supports more than 100 languages, and the recent version has an AI integration that recognizes texts of different sizes. Once the data is extracted, businesses can download it in a desired format, such as PDF, plain text, HTML, TSV, or XML.
a. Features
- Preprocesses the documents and images using edge detection, pixel manipulation, and deskewing techniques to enhance image quality and achieve accurate data extraction
- OCR analyzes the images and extracts relevant text
b. Pros
- Provides flexibility to adjust parameters and improve data extraction results
- Extracts text across different languages
- Easy to set and integrate with other tools
c. Cons
- The accuracy of pre-trained OCR models is low
- Manual intervention is required to preprocess documents and help Tesseract enhance accuracy
d. Pricing
- Free for all users
10. Azure AI Vision

Azure AI Vision OCR analyzes images such as posters, street signs, product labels, and several document types to extract texts as editable text lines or paragraphs. It even recognizes texts from documents with mixed languages, and data operators don't need to specify the languages for OCR to recognize.
The system supports many languages for both printed and handwritten texts and offers robust integration capabilities. With Azure AI Vision, businesses can focus on customer needs as it can scale, ensure high performance, and address data security and compliance needs.
a. Features
- Supports mixed languages, mixed modes (print and handwritten), and different writing styles
- Provides confidence scores for recognized text lines and words
- Available as a Distroless Docket container for on-premises deployment
b. Pros
- Training the model does not require any knowledge of machine learning algorithms
- Easy to create classification and object detection models for images and documents
c. Cons
- Little hard to understand for first-time users
- It takes time or struggles when uploading documents of large sizes
d. Pricing
- Custom pricing
Why Should You Choose Docsumo OCR API?
OCR APIs reduce document processing and text recognition costs, identify fraud, prevent manual data entry errors, and improve speed. Some of the factors that businesses should consider while choosing an image to text API solution are:
- A high accuracy rate and low churn rate
- Flexibility to handle different types of documents
- Ability to adapt to automatically changing variations in documents
- Customization and security measures
Docsumo is a comprehensive OCR text recognition solution that offers advanced analytics using AI along with the features as mentioned above. Pre-trained API models are ready to implement and require no manual training. In addition, businesses can customize and train these models to achieve specific business results.
The platform easily adapts to font styles, templates, and languages. Machine learning models in Docsumo improve over time from human feedback. With advanced technologies and robust validation and security features, Docsumo helps organizations:
- Achieve a 95%+ accuracy rate with text recognition
- Reduce processing time and enhance efficiency by 10X
- Improve straight-through processing rate
- Increase security through role-based access and cloud storage
- Ensure compliance as it is GDPR and SOC-2-compliant.
Ready to automate text recognition from documents? Sign up for a free trial and learn how Docsumo OCR streamlines document processing workflows.

Frequently Asked Questions
What is an OCR API?

OCR API accurately transcribes text from visual documents, delivering structured data in your preferred format.
What is the difference between OCR API and read API?
While OCR APIs effectively extract limited text from images, Read APIs are optimized for processing scanned documents with extensive textual content.
What is an OCR used for?
Optical Character Recognition (OCR) automatically converts text from images into editable digital format. It's widely used for scanning documents and extracting text.