Oops! Something went wrong while submitting the form.
Machine learning techniques for generating new, synthetic data without human intervention are well-established and involve data augmentation. Multiple methods can be effectively employed for extracting information related to business processes, hence increasing data extraction accuracy.
In this article, you will explore what data augmentation is and its importance. Since data extraction is crucial for training models, data augmentation is necessary to prevent constraints.
What is Data Augmentation?
Data augmentation is a powerful technique in AI and machine learning that artificially increases the size and diversity of datasets without manually collecting new data. It involves minor changes in existing data points to create new variations, expanding the training set for machine learning models.
Deep learning models depend on vast and varied data to accurately predict different scenarios. Data augmentation enhances the generation of diverse data variations, helping models refine their prediction accuracy. Augmented data plays a vital role in the training process
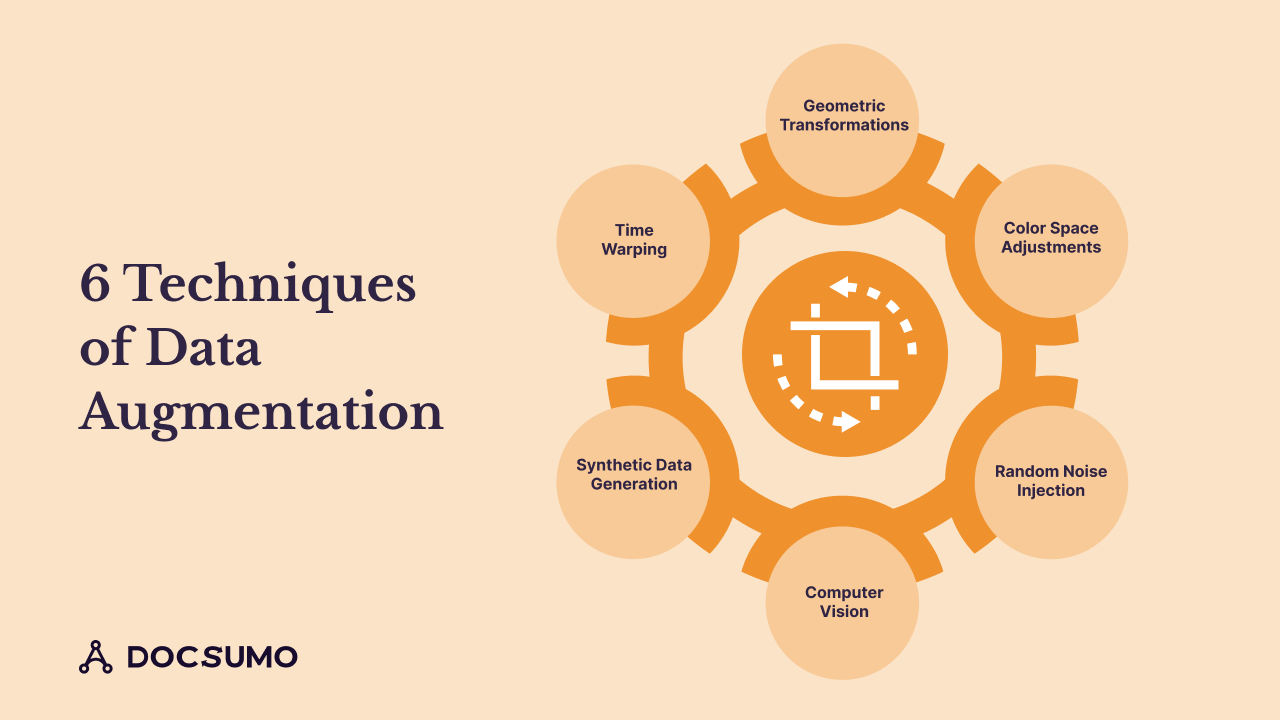
Techniques of Data Augmentation
Computer vision applications use standard data augmentation techniques for training data. Basic and complex data augmentation techniques exist for image recognition and natural language processing. Let’s study the techniques of data augmentation to know more abo
a. Geometric transformations
Geometric transformations in augmenting image datasets determine their suitability for specific tasks. Techniques such as image scaling, rotation, translation, shearing, and flipping are commonly employed. However, certain transformations like inverting may not be ideal for certain image types, such as digits, where confusion between 6 and 9 can arise.
Image scaling resizes input images using scale factors, which can improve model performance and robustness to input size variations.
Image rotation involves rotating images at a certain angle to create additional training data.
Image translation shifts images along the x and y axes. It creates more training data and enhances model strength to positional variations.
Image shearing skews images along the x and y axes based on their coordinates. It handles images captured from different perspectives or angles.
Image flipping reverses images' left and right sides, with horizontal flipping often used in tasks like handwritten gesture recognition.
b. Color space adjustments
Color space adjustments alter the distribution of colors in an image, affecting hue, brightness, contrast, and saturation.
It is useful for tasks like segmentation or classification of images sensitive to color changes.
It is beneficial for correcting color imbalances in the dataset, improving image quality, and simulating various lighting scenarios.
c. Random noise injection
Adding random disturbances to the pixel values of text, image, or audio signals is known as random noise injection.
Suitable for introducing variability and enhancing model generalization across various data types, including image, text, and audio data.
Effective for decreasing overfitting, emulating real-world noise in data, and regularizing it.
d. Computer vision
A key method in computer vision jobs is data augmentation, which provides a variety of data representations and fixes class imbalances in training datasets.
Positional adjustments are a major method of augmentation in computer vision. This process involves cropping, flipping, or rotating the input photos to create augmented variations.
Cropping creates a new image by resizing the original or extracting a portion. In the meantime, random changes are made to the original image through rotations, flips, and scaling operations, producing new variations according to predefined probabilities.
Color augmentation is another practical computer vision application. This method involves adjusting basic features of training images, like saturation, contrast, and brightness.
These common image alterations introduce variations in color, brightness, and the distribution of light and dark areas, producing augmented images.
e. Synthetic Data Generation
Synthetic data production approaches use simulations or algorithms to produce artificial data samples.
Dependent on the artificial generation technique, it is useful for various data types, such as text, audio, or images.
It is ideal when real-world data is limited or insufficient, as it improves or produces a variety of data sets for training.
f. Time warping
Time warping is the process of skewing the temporal organization of time-series data or audio signals.
Applicable to sequential data analytic problems like time-series forecasting, audio classification, and voice recognition.
It is helpful in imitating distortions, adding temporal fluctuations, or strengthening the model's resistance to temporal changes in the data.
Benefits of Data Augmentation for Data Extraction
Data augmentation largely depends on improving the efficacy and accuracy of data extraction processes. Increasing the training dataset with enhanced samples addresses problems like data scarcity, variability, and class imbalances. Machine learning and artificial intelligence are highly efficient.
a. Enhanced ML model robustness
Data augmentation helps improve machine learning models' resilience by exposing them to various training instances.
The variations and abnormalities found in real-world situations are inclined to affect models trained on augmented data.
Augmented data achieves better generalization, reducing overfitting by offering a wider range of training cases.
b. Improved Accuracy
Data augmentation reduces the effects of data variability and scarcity, improving data extraction procedures' accuracy.
Augmented data offers a more prominent and representative dataset, which allows models to benefit from a wider range of examples.
Data diversity increases the model's ability to manage unseen differences in input data and lowers the probability of bias.
c. Cost reduction
Data augmentation lowers the expenses related to labor-intensive manual data collecting and annotation.
Through augmentation, one can create artificial data samples and lessen the need for expensive or time-consuming data-collecting procedures.
Through augmented data, organizations might reduce the necessity for substantial labeling efforts, leading to significant financial benefits.
d. Handling imbalanced datasets
Unbalanced datasets are a prevalent problem in data extraction tasks addressed by data augmentation.
Some enhancement methods improve model performance on underrepresented categories and contribute to class distribution balance by producing more instances of minority classes.
Improvements in classification outcomes and equal model training occur from mitigating the imbalance issue by synthesizing augmented samples.
e. Versatility in application
Data augmentation techniques provide versatility when used for different types of data and extraction tasks.
Customizing augmentation techniques can address the needs of various data types, such as text, audio, graphics, and structured data.
Data augmentation offers flexible ways to improve model training for various applications, including speech recognition, object detection, OCR, and sentiment analysis.
Implementing Data Augmentation in Data Extraction processes
Integrating data augmentation into current data extraction operations requires a few easy techniques for optimal benefits and smooth implementation.
a. Integration with Machine Learning pipelines
Integration of augmentation techniques into the data preparation stage is necessary to integrate data augmentation into machine learning pipelines.
Determine which ML pipeline data preprocessing stage allows for the application of augmentation.
Before feeding the data into the model, you can use augmentation techniques for the data transformation process.
Maintaining workflow efficiency requires compatibility with existing pipeline frameworks and libraries.
b. Use of Augmentation libraries
Augmentation libraries provide pre-built functions and tools to facilitate the application of augmentation techniques to various data types.
When applying augmentation techniques to different forms of data, augmentation libraries offer pre-built functions and tools that make the process easier.
Tools to Data Augmentation
TensorFlow data augmentation API provides numerous image augmentation features in TensorFlow processes.
imgaug is a versatile library for picture augmentation that allows for color space modifications, geometric changes, and other features.
NLPAug offers text augmentation methods such as character-level changes, contextual word embeddings, and synonym replacement.
Audiomentations: Specialized library for pitch shifting, time stretching, and noise adding to audio data.
c. Custom Augmentation strategies
Custom augmentation strategies involve developing augmentation approaches to meet demands or overcome obstacles in data extraction operations.
Examine the dataset's unique features and limitations to find any places where standard augmentation methods might fall short.
Create unique augmentation functions or transformations based on the objectives of the extraction process and the data domain.
To ensure that bespoke augmentation tactics are efficient and compatible with the workflow, validate them through experimentation and performance review.
d. Batch Augmentation
Batch augmentation aims to increase scalability and efficiency by applying augmentation techniques to data samples in batches.
Split the dataset into batches, then concurrently apply augmentation techniques to each batch.
For huge datasets, accelerate the augmentation process by utilizing distributed computing frameworks or parallel processing.
Implement batch augmentation pipelines within workflow management systems or machine learning frameworks for a quicker process.
Monitoring and adjusting parameters
Continuous monitor parameters should be done and adjust for augmentation to be as successful as possible per project objectives.
Track model performance and data quality indicators to spot any augmentation-induced biases or degradation.
Evaluate the effect of augmentation parameters on the training and validation results of the model regularly.
Optimize model performance and generalization by adjusting augmentation parameters in response to input and performance review.
Overcoming the challenges of Data Augmentation
Businesses need to create tools for evaluating the quality of enhanced datasets. The necessity to assess the output quality will increase along with the use of data augmentation techniques.
Data augmentation needs more investigation and study to generate new or synthetic data with advanced applications.
a. Avoiding overfitting
Poor generalization on unseen data results from overfitting. It happens when a model learns to memorize the training data instead of identifying underlying patterns.
Using regularization techniques like dropout layers or L1/L2 regularization prevents the model from fitting noise in the data.
Monitor the model's performance on a validation set and cease training when overfitting becomes apparent.
Data augmentation approaches can introduce diversity into the training data and reduce the probability of overfitting by exposing the model to various examples.
b. Maintaining Data Integrity
Inaccurate or biased models could result from augmentation's introduction of noise or distortions that mess with the data's integrity.
Implement quality tests to ensure the enhanced data accurately depicts the original distribution and does not create unintentional biases.
Use augmentation pipelines with controlled changes throughout the augmentation process to preserve the data's accuracy and consistency.
c. Balancing the Augmentation mix
To prevent either over- or under-transforming the data, strike the correct balance using augmentation approaches.
Try out several augmentation methods and how to combine them to balance reality and diversity.
When choosing augmentation strategies, consider the task's demands and the dataset's features to ensure they support the project's objectives.
d. Computational efficiency
Utilizing computationally demanding augmentation techniques or augmenting sizable datasets can strain computer resources.
You can use parallel processing techniques to expedite the augmentation process by using multi-core CPUs or GPUs.
Employ hardware acceleration using libraries designed for GPU acceleration or specialized devices like TPUs.
To maximize efficiency, give priority to augmentation strategies that provide a good balance between computational cost and efficiency.
e. Assessing Augmentation impact
It can be challenging to evaluate the influence of augmentation approaches on model performance and their efficiency.
Examine the model's performance on supplemented data using appropriate validation methods, such as holdout or k-fold cross-validation.
Maintain a close eye on model performance and adjust augmentation parameters in response to feedback to stay in line with project objectives and gradually increase productivity.
Conclusion: Enhancing Data Extraction with Augmentation techniques
Augmentation approaches present a potent way to improve data extraction procedures in various fields. Artificially adding datasets helps increase the model's size, diversity, and accuracy.
Automation makes integrating augmentation into extraction procedures even more efficient and smoother. Adopting augmentation approaches can maximize the potential of data-driven applications and gain deeper insights.
Docsumo offers advanced technology and experience to simplify business processes, making it the ideal solution for efficient data extraction needs. In addition to ensuring accurate data extraction, Docsumo's strong architecture allows it to integrate data augmentation techniques, improving the quality and diversity of your datasets.
1. What is the best way to determine the right data augmentation techniques for a specific data extraction task?
Understand your dataset's features, then experiment with customized augmentation approaches for image, text, or audio data. Assess their effect on model performance to choose the ones that work best for your task. Some techniques are cropping, flipping, synonym replacement, back-translation, etc.
2. How can data augmentation affect the speed and efficiency of data extraction models?
Data augmentation can boost model training speed and efficiency by giving a bigger and more diverse dataset, reducing overfitting, and enhancing generalization. As a result, data extraction models become more reliable and accurate.
3. Can data augmentation be automated within data extraction workflows?
Yes, by employing libraries and frameworks with built-in augmentation functionalities, data augmentation can be automated within data extraction operations, increasing workflow efficiency.
Oops! Something went wrong while submitting the form.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.